This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Scikit-learn Scikit-learn is a powerful library for machine learning in Python. It provides a wide range of tools for supervised and unsupervised learning, including linear regression, k-means clustering, and supportvectormachines. Scikit-learn is a go-to tool for data scientists and machine learning practitioners.
The proposed Q-BGWO-SQSVM approach utilizes an improved quantum-inspired binary Grey Wolf Optimizer and combines it with SqueezeNet and SupportVectorMachines to exhibit sophisticated performance. SqueezeNet’s fire modules and complex bypass mechanisms extract distinct features from mammography images.
Machine learning models: Machine learning models, such as supportvectormachines, recurrent neural networks, and convolutional neural networks, are used to predict emotional states from the acoustic and prosodic features extracted from the voice.
Machine Learning for Beginners Learn the essentials of machine learning including how SupportVectorMachines, Naive Bayesian Classifiers, and Upper Confidence Bound algorithms work. After this talk, you will have an intuitive understanding of these three algorithms and real-life problems where they can be applied.
Classification algorithms include logistic regression, k-nearest neighbors and supportvectormachines (SVMs), among others. Association algorithms allow data scientists to identify associations between data objects inside large databases, facilitating data visualization and dimensionality reduction.
SupportVectorMachine Classification algorithm makes use of a multidimensional representation of the data points. In practical terms, the data may be collected from databases of marketing, biomedical, geospatial databases among many other places. Hence, the assumption causes a problem.
It leverages the power of technology to provide actionable insights and recommendations that support effective decision-making in complex business scenarios. At its core, decision intelligence involves collecting and integrating relevant data from various sources, such as databases, text documents, and APIs.
Classification algorithms like supportvectormachines (SVMs) are especially well-suited to use this implicit geometry of the data. It boasts advanced capabilities like chat with data, advanced Retrieval Augmented Generation (RAG), and agents, enabling complex tasks such as reasoning, code execution, or API calls.
Unlike structured data, which resides in databases and spreadsheets, unstructured data poses challenges due to its complexity and lack of standardization. Machine Learning algorithms, including Naive Bayes, SupportVectorMachines (SVM), and deep learning models, are commonly used for text classification.
For example, SupportVectorMachines are not probabilistic, but they are still used for Discriminative AI by finding a decision boundary in the space. On the other hand, with Generative AI it is generally safe to say that we are modeling a joint distribution because the distribution itself is the object of interest.
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). Understanding the differences between SQL and NoSQL databases is crucial for students.
After picking the set of images you desire to use, the algorithm will detect the keypoints of the images and store them in a database. Object detection will then occur via feature comparison between any new image’s features and the database’s features. It has a relatively straightforward method of operation.
Public Datasets: Utilising publicly available datasets from repositories like Kaggle or government databases. SupportVectorMachines (SVM) SVMs classify data points by finding the optimal hyperplane that maximises the margin between classes. Web Scraping : Extracting data from websites and online sources.
websites, social media platforms, customer surveys, online reviews, emails and/or internal databases). Machine learning algorithms like Naïve Bayes and supportvectormachines (SVM), and deep learning models like convolutional neural networks (CNN) are frequently used for text classification.
Several constraints were placed on selecting these instances from a larger database. The objective of the dataset is to diagnostically predict whether or not a patient has diabetes based on specific diagnostic measurements included in the dataset. In particular, all patients here are females at least 21 years old of Pima Indian heritage.
These systems used vast databases of knowledge and complex if-then rules coded by humans. Think of “expert systems” from the 1980s, designed to mimic the decision-making ability of a human expert in a specific domain (like medical diagnosis or financial planning).
Algorithms Used in Both Fields In Machine Learning, algorithms focus on learning from labelled data to make predictions or decisions. Common algorithms include Linear Regression, Decision Trees, Random Forests, and SupportVectorMachines. Deep Learning, however, thrives on large volumes of data.
SupportVectorMachines (SVM) SVM can be employed for anomaly detection by finding the hyperplane that best separates normal data from anomalies. Autoencoders These neural network architectures are used to learn efficient representations of data. By training an autoencoder on normal data, it can reconstruct input data.
Data can be collected from various sources, such as databases, sensors, or the internet. Machine learning and deep learning algorithms are commonly used in AI development. This data could be in the form of structured data (such as data in a database) or unstructured data (such as text, images, or audio).
Overview Vector Embedding 101: The Key to Semantic Search Vector indexing: when you have millions or more vectors, searching through them would be very tedious without indexing. OpenAI’s Embedding Model With VectorDatabase OpenAI updated in December 2022 the Embedding model to text-embedding-ada-002. lower price.
Be aware that pip is probably what you should use if you’re installing packages directly into a Colab notebook or another environment that makes use of virtual machines. !pip pip install comet_ml — or — !conda It contains 60,000 examples, where each example is a grayscale image of a handwritten digit, and a test set of 10,000 examples.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
By combining data from mass spectrometry experiments and sequence databases, researchers can identify and characterize proteins, understand their functions, and explore their interactions with other molecules. In proteomics, bioinformatics tools have been instrumental in deciphering the complex world of proteins.
By analyzing historical data and utilizing predictive machine learning algorithms like BERT, ARIMA, Markov Chain Analysis, Principal Component Analysis, and SupportVectorMachine, they can assess the likelihood of adverse events, such as hospital readmissions, and stratify patients based on risk profiles.
To execute, the Ocean Protocol Data Science team and the challenge participants used the provided data made available by the European Commission EDGAR — Emissions Database for Global Atmospheric Research. Two Data Sets were used to weigh carbon emission rates under two different metrics: Co2 (Carbon Dioxide) and GHG (Green House Gases).
Structured data refers to neatly organised data that fits into tables, such as spreadsheets or databases, where each column represents a feature and each row represents an instance. This data can come from databases, APIs, or public datasets. Without high-quality data, even the most sophisticated model will fail.
SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane. databases, CSV files). Decision Trees These trees split data into branches based on feature values, providing clear decision rules. They are handy for high-dimensional data.
They had a hunch that their data, with samples from American Census Bureau workers and American high school students, wouldn’t be a great fit for machine learning experiments. So, what does the MNIST database look like? In their debut paper, they used a support-vectormachine and only messed up 0.8%
The e1071 package provides a suite of statistical classification functions, including supportvectormachines (SVMs), which are commonly used for spam detection. Naive Bayes, according to Nagesh Singh Chauhan in KDnuggets, is a straightforward machine learning technique that uses Bayes’ theorem to create predictions.
For example, the Institute of Cancer Research cancer database combines genetic and clinical data from patients with information from scientific research. Deep neural networks and supportvectormachines are being explored in developing pre-diabetic screening tools. Further applications in genomic medicine (e.g.,
Scikit-learn provides a consistent API for training and using machine learning models, making it easy to experiment with different algorithms and techniques. It also provides tools for model evaluation , including cross-validation, hyperparameter tuning, and metrics such as accuracy, precision, recall, and F1-score.
Another example can be the algorithm of a supportvectormachine. Hence, we have various classification algorithms in machine learning like logistic regression, supportvectormachine, decision trees, Naive Bayes classifier, etc. What are SupportVectors in SVM (SupportVectorMachine)?
Databases to be migrated can have a wide range of data representations and contents. For the sake of argument, let’s ignore the fact that the use of such data types in databases is justified only in a few specific cases, as this problem often arises when migrating complex systems. in XML, CLOB, BLOB etc.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






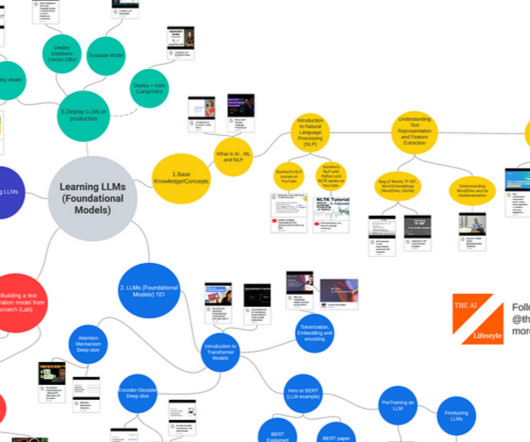

































Let's personalize your content