This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Gradient boosting decisiontrees (GBDT) are at the forefront of machine learning, combining the simplicity of decisiontrees with the power of ensemble techniques. Understanding the mechanics behind GBDT requires diving into decisiontrees, ensemble learning methods, and the intricacies of optimization strategies.
In this post, I will show how to develop, deploy, and use a decisiontree model in a Db2 database. Using examples from the dataset, we’ll build a classification model with decisiontree algorithm. Since I will create a decisiontree model, I don’t need to deal with the large value and the missing values.
Classification Classification techniques, including decisiontrees, categorize data into predefined classes. Decisiontrees and K-nearest neighbors (KNN) Both decisiontrees and KNN play vital roles in classification and prediction. This approach is useful for predicting outcomes based on historical data.
Base model training Next, each bootstrap sample undergoes independent training with base models, which can be decisiontrees or other machine learning algorithms. Definition and purpose The Bagging Regressor is an application of the bagging method designed for regression analysis.
Definition and overview of predictive modeling At its core, predictive modeling involves creating a model using historical data that can predict future events. Unsupervised models Unsupervised models typically use traditional statistical methods such as logistic regression, time series analysis, and decisiontrees.
Definition and types of categorical data Categorical data can be classified into two primary types: nominal and ordinal. Algorithms supporting categorical data Some algorithms, such as decisiontrees, can handle categorical data without the need for extensive preprocessing.
This decision boundary is crucial for achieving accurate predictions and effectively dividing data points into categories. Definition of SVM SVMs operate on the principle of finding the hyperplane that maximizes the margin between different classes.
First bringing together conflicting literature on what XAI is and some important definitions and distinctions. The current state of explainability … explained Any research on explainability will show that there is little by way of a concrete definition. Interpretability — Explaining the meaning of a model/model decisions to humans.
This one is definitely one of the most practical and inspiring. So you definitely can trust his expertise in Machine Learning and Deep Learning. So you definitely can trust his expertise in Machine Learning and Deep Learning. I’ve passed many ML courses before, so that I can compare. About the course The Fast.AI
Summary: Entropy in Machine Learning quantifies uncertainty, driving better decision-making in algorithms. It optimises decisiontrees, probabilistic models, clustering, and reinforcement learning. Lets delve into its mathematical definition and key properties.
For centuries before the existence of computers, humans have imagined intelligent machines that were capable of making decisions autonomously. At the early era of Artificial Intelligence, programmers tried to teach machines from the definition of logical rules that the machine itself could extend during the execution of the program.
This article will cover the basics of DecisionTrees and XGBoost, and demonstrate how to implement the latter for classifying celestial objects in the night sky as either a Galaxy, Star, or Quasar. Photo by Nathan Anderson on Unsplash Brief Intro to ML Algorithms A decisiontree is a widely used algorithm in machine learning.
Definition says, machine learning is the ability of computers to learn without explicit programming. Linear Regression DecisionTrees Support Vector Machines Neural Networks Clustering Algorithms (e.g., I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’.
Correctly predicting the tags of the questions is a very challenging problem as it involves the prediction of a large number of labels among several hundred thousand possible labels. In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations.
DecisionTrees: Represent hypothesis as conditional rules. DecisionTrees : Ideal for classification tasks using conditional rules. For decisiontrees: Conditional rules like “If income > 50K, then class = high.” Decisiontrees examine various tree structures.
This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. DecisionTreesDecisiontrees recursively partition data into subsets based on the most significant attribute values. classification, regression) and data characteristics.
From deterministic software to AI Earlier examples of “thinking machines” included cybernetics (feedback loops like autopilots) and expert systems (decisiontrees for doctors). When the result is unexpected, that’s called a bug. But these were still predictable and understandable. They just followed a lot of rules.
Key steps involve problem definition, data preparation, and algorithm selection. For example, linear regression is typically used to predict continuous variables, while decisiontrees are great for classification and regression tasks. Decisiontrees are easy to interpret but prone to overfitting.
The reasoning behind that is simple; whatever we have learned till now, be it adaptive boosting, decisiontrees, or gradient boosting, have very distinct statistical foundations which require you to get your hands dirty with the math behind them. , you already know that our approach in this series is math-heavy instead of code-heavy.
We went through the core essentials required to understand XGBoost, namely decisiontrees and ensemble learners. AdaBoos t A formal definition of AdaBoost (Adaptive Boosting) is “the combination of the output of weak learners into a weighted sum, representing the final output.” Table 1: The Dataset.
He dissected the four core elements of AI agents: task definition, tool usage, rules and constraints, and structured prompts. Ozdemir focused on structured agent workflows , breaking down AI tasks into decisiontrees with modular components.
DecisionTrees ML-based decisiontrees are used to classify items (products) in the database. In its core, lie gradient-boosted decisiontrees. For instance, when used with decisiontrees, it learns to outline the hardest-to-classify data instances over time. But the results should be worth it.
Decisiontrees are more prone to overfitting. Some algorithms that have low bias are DecisionTrees, SVM, etc. Hence, we have various classification algorithms in machine learning like logistic regression, support vector machine, decisiontrees, Naive Bayes classifier, etc. character) is underlined or not.
The scholar, in her work , opines that: Interpretability is about understanding how the model works, whereas explainability involves providing justifications for specific predictions or decisions. Decisiontrees can be trained and visualized in rule-based explanations to reveal the underlying decision logic. Singh, S. &
In this article, we will explore the definitions, differences, and impacts of bias and variance, along with strategies to strike a balance between them to create optimal models that outperform the competition.
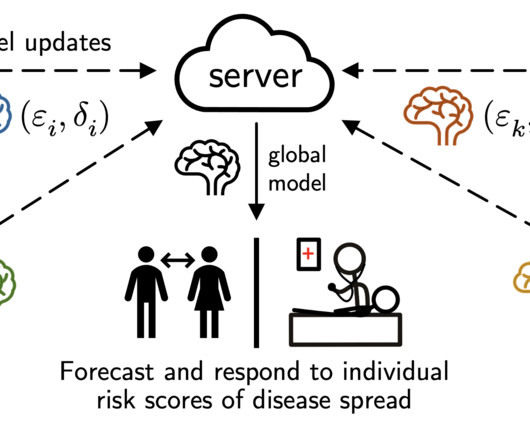
Privacy definition: There are a small number of clients, but each holds many data subjects, and client-level DP isn’t suitable. imposing a max node degree and accounting for it), are there alternative privacy definitions that offer varying degrees of protection for varying node connectedness?
CIU is model-agnostic and provides uniform explanation concepts for all possible DSS models, ranging from linear models such as the weighted sum, to rule-based systems, decisiontrees, fuzzy systems, neural networks and any machine learning-based models. This definition of CU differs from CI by handling negative A values correctly.
The best baseline was achieved with a weighted ensemble of gradient boosted decisiontree models. The ML model takes in the historical sequence of machine events and other metadata and predicts whether a machine will encounter a failure in a 6-hour future time window.
AI automates and optimises Data Science workflows, expediting analysis for strategic decision-making. Data Science Vs Machine Learning Vs AI Aspect Data Science Artificial Intelligence Machine Learning Definition Data Science is the field that deals with the extraction of knowledge and insights from data through various processes.
Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decisiontrees, and support vector machines. It includes regression, classification, clustering, decisiontrees, and more. To obtain practical expertise, run the algorithms on datasets.
The following figure is a decisiontree to help you decide what type of endpoint to use. The diagram outlines a decision-making process for selecting between batch, asynchronous, or real-time inference endpoints.
These statistics underscore the significant impact that Data Science and AI are having on our future, reshaping how we analyse data, make decisions, and interact with technology. Machine Learning Expertise Familiarity with a range of Machine Learning algorithms is crucial for Data Science practitioners.
Summary: This article compares Artificial Intelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. Definition of AI AI refers to developing computer systems that can perform tasks that require human intelligence.
Lists Definitely the most used structure, they are a set of elements separated by the comma. Trees Hierarchical structures are important for Machine Learning for the creation of Decisiontrees (I will talk about it soon if we are lucky). Within the images you will find the code comments.
It’s critical in harnessing data insights for decision-making, empowering businesses with accurate forecasts and actionable intelligence. Options include linear regression for continuous outcomes and decisiontrees for classification tasks. The choice impacts the model’s performance and accuracy.
linear regression, decisiontrees , SVM) – Understanding about the perfect fit for using each algorithm – Parameters and hyperparameters to tune Click here to access -> Cheat sheet for Key Machine Learning Algorithms Deep Learning Concepts and Neural Network Architectures – Neural network components and their functions (e.g.,
This is achieved through the use of a positive definite kernel function, k(x,y), which satisfies the property: k(x,y) = <φ(x), φ(y)> where φ(x) is the mapping of the input data into the high-dimensional feature space and < ,> is the inner product in the RKHS.
It's in contrast to a really broad and undefined definition of the word ”outcome” Paul, one of the design managers at Intercom, was struggling to differentiate between customer outcomes and business impact. High variance means overfitting models with high flexibility tend to have high variance like decisiontrees.
Personally, I think there are definitely horizons in math, biology, and physics that we may never reach… but maybe AI can change that. Ten years ago, this same month, I finished my PhD and started working on Eureqa full time. This search for mathematical formulas makes Eureqa different from other machine learning algorithms.
Definition of supervised learning At its core, supervised learning utilizes labeled data to inform a machine learning model. Common algorithms used in classification tasks include: DecisionTrees: A tree-like model that makes decisions based on feature values.
Machine learning algorithms are specialized computational models designed to analyze data, recognize patterns, and make informed predictions or decisions. Definition and importance of machine learning algorithms The core value of machine learning algorithms lies in their capacity to process and analyze vast amounts of data efficiently.
Understanding baseline models The definition of baseline models emphasizes their purpose in machine learning: they define a minimum level of performance that any model must achieve to be considered useful. Decisiontrees: Provide interpretable predictions based on logical rules.
Definition and purpose Neural networks are designed to mimic human brain functions using layers of interconnected nodes, processing input data through complex mathematical computations. Symbolic approaches, such as decisiontrees, offer clarity and reasoning but may lack the speed and capacity of neural networks.
The decision boundary would be a line that separates these two groups, determining whether a new point falls into the cat or dog category based on its features. Definition of decision boundary The definition of a decision boundary is rooted in its functionality within classification algorithms.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content