This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
ExploratoryDataAnalysis(EDA)on Biological Data: A Hands-On Guide Unraveling the Structural Data of Proteins, Part II — ExploratoryDataAnalysis Photo from Pexels In a previous post, I covered the background of this protein structure resolution data set, including an explanation of key data terminology and details on how to acquire the data.
Feature engineering in machinelearning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through ExploratoryDataAnalysis , imputation, and outlier handling, robust models are crafted. Time features Objective: Extracting valuable information from time-related data.
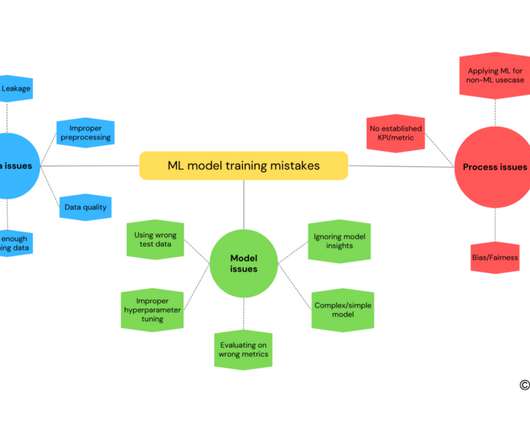
Mind Map: Mistakes in ML model training This blog highlights some important mistakes that one can make while training a machinelearning model. MachineLearning model training is the process of teaching a model how to recognize patterns in data. Thank you for reading and appreciate your feedback.
Source: Author MachineLearning Visualization is the art and science of representing machinelearning models, data, and their relationships through graphical or interactive means. Visualization is crucial to any machinelearning project to understand complex data.
That post was dedicated to an exploratorydataanalysis while this post is geared towards building prediction models. and reflect the inherent imbalance in the training and testing data; Using a penalized model (instead of a sampling technique like SMOTE) with a simple weighting scheme that is the inverse of a class frequency.
METAR, Miami International Airport (KMIA) on March 9, 2024, at 15:00 UTC In the recently concluded data challenge hosted on Desights.ai , participants used exploratorydataanalysis (EDA) and advanced artificial intelligence (AI) techniques to enhance aviation weather forecasting accuracy.
Summary: In the tech landscape of 2024, the distinctions between Data Science and MachineLearning are pivotal. Data Science extracts insights, while MachineLearning focuses on self-learning algorithms. ML catalyses AI advancements, enabling systems to evolve and improve decision-making.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. Introduction In the rapidly evolving field of Data Science, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machinelearning and deep learning. Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence.
Data Science Project — Predictive Modeling on Biological Data Part III — A step-by-step guide on how to design a ML modeling pipeline with scikit-learn Functions. Photo by Unsplash Earlier we saw how to collect the data and how to perform exploratorydataanalysis. Now comes the exciting part ….
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform ExploratoryDataAnalysis to uncover patterns and insights hidden within the data. Data Integration Data integration combines data from different sources into a single dataset.
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. It covers essential topics such as SQL queries, data visualization, statistical analysis, machinelearning concepts, and data manipulation techniques.
Data Science skills that will help you excel professionally. Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, MachineLearning algorithms, and data manipulation techniques.
R is a popular programming language and environment widely used in the field of data science. It provides a comprehensive suite of tools, libraries, and packages specifically designed for statistical analysis, data manipulation, visualization, and machinelearning.
Hands-on Project Why customer churn matters and how to predict it with machinelearning, explained step-by-step Photo by Gabrielle Ribeiro on Unsplash Introduction In today’s competitive business environment, retaining customers is essential to a company’s success. Follow “Nhi Yen” for future updates! Our project uses Comet ML to: 1.
In this article, we will explore the essential steps involved in training LLMs, including data preparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
The reasoning behind that is simple; whatever we have learned till now, be it adaptive boosting, decisiontrees, or gradient boosting, have very distinct statistical foundations which require you to get your hands dirty with the math behind them. The goal is to nullify the abstraction created by packages as much as possible.
Setting Up the Prerequisites Building the Model Assessing the Model Summary Citation Information Scaling Kaggle Competitions Using XGBoost: Part 2 In our previous tutorial , we went through the basic foundation behind XGBoost and learned how easy it was to incorporate a basic XGBoost model into our project. Table 1: The Dataset.
Data Science Project — Build a DecisionTree Model with Healthcare Data Using DecisionTrees to Categorize Adverse Drug Reactions from Mild to Severe Photo by Maksim Goncharenok Decisiontrees are a powerful and popular machinelearning technique for classification tasks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content