This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. DecisionTrees visualize decision-making processes for better understanding.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
With the growing use of machine learning (ML) models to handle, store, and manage data, the efficiency and impact of enterprises have also increased. Categorical data is one such form of information that is handled by ML models using different methods. Learn about 101 ML algorithms for data science with cheat sheets 5.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machine learning?
We shall look at various machine learning algorithms such as decisiontrees, random forest, K nearest neighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. I wrote about Python ML here. data = trainData) 5. From research to projects and ideas.
As we navigate this landscape, the interconnected world of Data Science, Machine Learning, and AI defines the era of 2024, emphasising the importance of these fields in shaping the future. ’ As we navigate the expansive tech landscape of 2024, understanding the nuances between Data Science vs Machine Learning vs ai.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
With a modeled estimation of the applicant’s credit risk, lenders can make more informed decisions and reduce the occurrence of bad loans, thereby protecting their bottom line. This can lead to fairer and more equitable credit decisions. What Does a Credit Score or DecisioningML Pipeline Look Like?
Mastering Tree-Based Models in Machine Learning: A Practical Guide to DecisionTrees, Random Forests, and GBMs Image created by the author on Canva Ever wondered how machines make complex decisions? Just like a tree branches out, tree-based models in machine learning do something similar.
Photo by Andy Kelly on Unsplash Choosing a machine learning (ML) or deep learning (DL) algorithm for application is one of the major issues for artificial intelligence (AI) engineers and also data scientists. ML algorithms and their application [table by author] Table 2. Here I wan to clarify this issue.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ? ✔ how to reduce the complexity and computational expensiveness of ML models ? will my data help in this ?
Classification In Classification, we use an ML Algorithm to classify the digit based on its features. SupportVectorMachines (SVMs) are another ML models that can be used for HDR. The algorithm can be trained on a dataset of labeled digit images, which allows it to learn to recognize the patterns in the images.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. Hence, the assumption causes a problem.
This is where the power of machine learning (ML) comes into play. Machine learning algorithms, with their ability to recognize patterns, anomalies, and trends within vast datasets, are revolutionizing network traffic analysis by providing more accurate insights, faster response times, and enhanced security measures.
Basically, Machine learning is a part of the Artificial intelligence field, which is mainly defined as a technic that gives the possibility to predict the future based on a massive amount of past known or unknown data. ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning.
Introduction In today’s rapidly evolving technological landscape, terms like Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) are thrown around constantly. This led to the rise of Machine Learning (ML). Machine Learning is a subset of Artificial Intelligence.
To address this challenge, data scientists harness the power of machine learning to predict customer churn and develop strategies for customer retention. I write about Machine Learning on Medium || Github || Kaggle || Linkedin. ? Our project uses Comet ML to: 1. The entire code can be found on both GitHub and Kaggle.
Introduction Machine Learning (ML) is revolutionising the business world by enabling companies to make smarter, data-driven decisions. As an advanced technology that learns from data patterns, ML automates processes, enhances efficiency, and personalises customer experiences. What is Machine Learning?
bag of words or TF-IDF vectors) and splitting the data into training and testing sets. Define the classifiers: Choose a set of classifiers that you want to use, such as supportvectormachine (SVM), k-nearest neighbors (KNN), or decisiontree, and initialize their parameters.
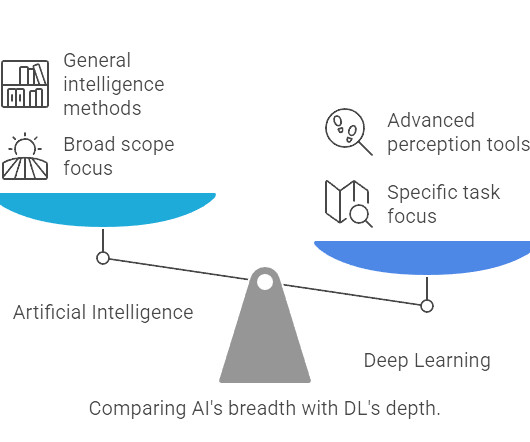
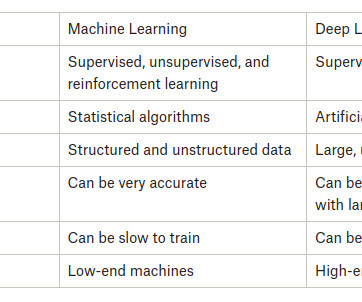
Summary: Machine Learning and Deep Learning are AI subsets with distinct applications. ML works with structured data, while DL processes complex, unstructured data. ML requires less computing power, whereas DL excels with large datasets. Key Takeaways ML requires structured data, while DL handles complex, unstructured data.
Machine Learning Techniques for Demand Forecasting Machine Learning (ML) offers powerful tools for tackling complex demand forecasting challenges. DecisionTrees These tree-like structures categorize data and predict demand based on a series of sequential decisions.
Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
Photo by Shahadat Rahman on Unsplash Introduction Machine learning (ML) focuses on developing algorithms and models that can learn from data and make predictions or decisions. One of the goals of ML is to enable computers to process and analyze data in a way that is similar to how humans process information.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
What is machine learning? Machine learning (ML) is a subset of artificial intelligence (AI) that focuses on learning from what the data science comes up with. Some examples of data science use cases include: An international bank uses ML-powered credit risk models to deliver faster loans over a mobile app.
This article delves into using deep learning to enhance the effectiveness of classic ML models. Background Information Decisiontrees, random forests, and linear regression are just a few examples of classic machine-learning models that have been used extensively in business for years.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: SupportVectorMachine , S upport Vectors and Linearly vs. Non-linearly Separable Data. The linear kernel is ideal for linear problems, such as logistic regression or supportvectormachines ( SVMs ).
Machine Learning and Neural Networks (1990s-2000s): Machine Learning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming. Techniques such as decisiontrees, supportvectormachines, and neural networks gained popularity.
Source: [link] Similarly, while building any machine learning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. You need to make that model available to the end users, monitor it, and retrain it for better performance if needed. What is MLOps?
PyTorch This essential library is an open-source ML framework capable of speeding up research prototyping, allowing companies to enter the production deployment phase. Key PyTorch features include robust cloud support, a rich ecosystem of tools, distributed training and native ONNX (Open Neural Network Exchange) support.
ML algorithms for analyzing IoT data using artificial intelligence Machine learning forms the foundation of AI in IoT, allowing devices to learn patterns, make predictions, and adapt to changing circumstances. Unsupervised learning Unsupervised learning involves training machine learning models with unlabeled datasets.
Variance in Machine Learning – Examples Variance in machine learning refers to the model’s sensitivity to changes in the training data, leading to fluctuations in predictions. If you are planning to excel in Machine Learning concepts, but are not familiar with it, then join the Free ML Course Online course by Pickl.AI.
Decisiontrees are more prone to overfitting. Let us first understand the meaning of bias and variance in detail: Bias: It is a kind of error in a machine learning model when an ML Algorithm is oversimplified. Some algorithms that have low bias are DecisionTrees, SVM, etc. character) is underlined or not.
Model Complexity Machine Learning : Traditional machine learning models have fewer parameters and a simpler structure than deep learning models. They typically rely on simpler algorithms like decisiontrees, supportvectormachines, or linear regression.
Some important things that were considered during these selections were: Random Forest : The ultimate feature importance in a Random forest is the average of all decisiontree feature importance. A random forest is an ensemble classifier that makes predictions using a variety of decisiontrees. Cambridge: MIT Press.
As MLOps become more relevant to ML demand for strong software architecture skills will increase aswell. Machine Learning As machine learning is one of the most notable disciplines under data science, most employers are looking to build a team to work on ML fundamentals like algorithms, automation, and so on.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decisiontrees, and supportvectormachines.
49% of companies in the world that use Machine Learning and AI in their marketing and sales processes apply it to identify the prospects of sales. On the other hand, 48% use ML and AI for gaining insights into the prospects and customers. An ensemble of decisiontrees is trained on both normal and anomalous data.
Machine Learning Approaches Machine Learning (ML) techniques automate the sentiment classification process by training models on labelled datasets. SupportVectorMachines (SVM) : This method identifies optimal decision boundaries to classify sentiment effectively across various datasets.
Machine Learning Machine Learning (ML) is a crucial component of Data Science. ML models help predict outcomes, automate tasks, and improve decision-making by identifying patterns in large datasets. This program provides a deep dive into AI and ML concepts, supported by hands-on projects and immersion modules.
A new ML method will be the driving force toward improving algorithms Regularly evaluating and refining your AI model Regularly evaluating and refining your AI model is essential for improving its accuracy and efficiency. Model selection: Choose a model that is appropriate for the size and complexity of the data.
They are: Based on shallow, simple, and interpretable machine learning models like supportvectormachines (SVMs), decisiontrees, or k-nearest neighbors (kNN). Relies on explicit decision boundaries or feature representations for sample selection. It can be run locally or through a cloud service.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content