This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction DocVQA (Document Visual Question Answering) is a research field in computer vision and natural language processing that focuses on developing algorithms to answer questions related to the content of a document, like a scanned document or an image of a text document.
Introduction Document information extraction involves using computer algorithms to extract structured data (like employee name, address, designation, phone number, etc.) from unstructured or semi-structured documents, such as reports, emails, and web pages.
This cheatsheet should be easier to digest than the official documentation and should be a transitional tool to get students and beginners to get started reading documentations soon.
Integrating with various tools allows us to build LLM applications that can automate tasks, provide […] The post What are Langchain Document Loaders? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Objective To get the bounding boxes around the scanned documents with. The post Document Layout Detection and OCR With Detectron2 ! appeared first on Analytics Vidhya.
What I’ve learned from the most popular DL course Photo by Sincerely Media on Unsplash I’ve recently finished the Practical DeepLearning Course from Fast.AI. So you definitely can trust his expertise in Machine Learning and DeepLearning. Luckily, there’s a handy tool to pick up DeepLearning Architecture.
This makes it ideal for high-performance use cases like real-time chat applications or APIs for machine learning models. Figure 3: FastAPI vs Django: Async capabilities | by Nanda Gopal Pattanayak | Medium Automatic Interactive API Documentation Out of the box, FastAPI generates Swagger UI and ReDoc documentation for all API endpoints.
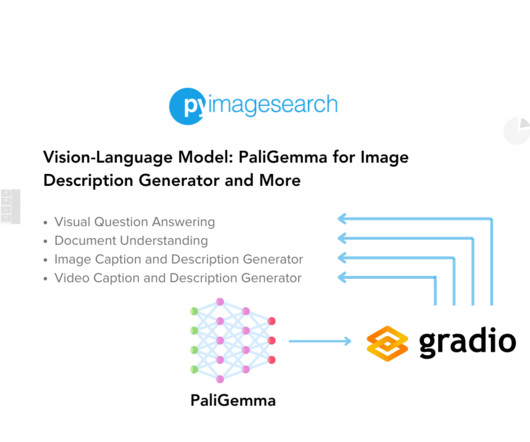
It has been trained on diverse datasets that contain both visual and textual elements, making it versatile for tasks such as visual question answering, document understanding, image captioning, etc. But What Is Document Understanding? In Figure 1 , we can see the architecture of PaliGemma.
Transformers, a type of DeepLearning model, have played a crucial role in the rise of LLMs. This solution aims to address the deeplearning deployment gap in the banking sector by jump-starting banks’ deeplearning language capabilities in a matter of weeks, rather than years [ 1 ].
The vector stores have become an integral part of developing apps with DeepLearning Models, especially the Large Language Models. In the ever-evolving landscape of […] The post A Deep Dive into Qdrant, the Rust-Based Vector Database appeared first on Analytics Vidhya.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
If modern artificial intelligence has a founding document, a sacred text, it is Google’s 2017 research paper “Attention Is All You Need.” This paper introduced a new deeplearning architecture known as the transformer, which has gone on to revolutionize the field of AI over the past half-decade.
Micah Goldblum , a Postdoctoral Researcher at CDS, has created exactly that, in a recent survey intended to capture the multifaceted views of influential figures in deeplearning. Goldblum’s work, the first in a planned series, aims to document diverse opinions in the field, particularly those not amplified by social media platforms.
Approaches to NLP NLP can be broadly categorized into rule-based systems and machine learning systems. Rule-based systems utilize predefined linguistic rules to analyze text, while machine learning systems rely on data-driven approaches to train models. Gensim: Primarily used for topic modeling and document similarity analysis.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Photo by AltumCode on Unsplash As a data scientist, I used to struggle with experiments involving the training and fine-tuning of large deep-learning models. In this article, we’ll explore how to track hyperparameters and performance scores of deeplearning models using kedro-viz.
This enigmatic model has been released without official documentation, leading to speculation about its origins and capabilities. This new artificial intelligence (AI) model has recently emerged and is causing quite a stir in the tech community.
identifying the “emotional tone” of a particular document). These approaches were all based on a technique called “bagging”; the process of splitting documents into a collection of words (which we’ll refer to as “tokens”). In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
The explosion in deeplearning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. BERT ) to a factorized dual-encoder , an important setting for the task of scoring the relevance of a [ query , document ] pair.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language. MICR line format).
These models can understand and generate human-like text, enabling applications like chatbots and document summarization. Introduction to Ludwig The development of Natural Language Machines (NLP) and Artificial Intelligence (AI) has significantly impacted the field.
Document Intelligence Series — Part-1: Table Detection with YOLOv8 Photo by Mr Cup / Fabien Barral on Unsplash Introduction When dealing with unstructured data, you frequently encounter a situation where you must seek a resolution to efficiently retrieve information from a table within any document. Perform OCR.
Introduction Imagine standing in a dimly lit library, struggling to decipher a complex document while juggling dozens of other texts. This was the world of Transformers before the “Attention is All You Need” paper unveiled its revolutionary spotlight – the attention mechanism.
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), natural language processing (NLP), and recommendation systems. If not, refer to Using the SageMaker Python SDK before continuing.
Unstructured data, including text documents and social media posts, exacerbates this challenge with its inherent lack of predefined structure, making extracting meaningful insights even […] The post Ways of Converting Textual Data into Structured Insights with LLMs appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Overview Sentence classification is one of the simplest NLP tasks that have a wide range of applications including document classification, spam filtering, and sentiment analysis. A sentence is classified into a class in sentence classification.
Emerging as a key player in deeplearning (2010s) The decade was marked by focusing on deeplearning and navigating the potential of AI. Introduction of cuDNN Library: In 2014, the company launched its cuDNN (CUDA Deep Neural Network) Library. It provided optimized codes for deeplearning models.
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. The following diagram represents each stage in a mortgage document fraud detection pipeline.
Summary: Attention mechanism in DeepLearning enhance AI models by focusing on relevant data, improving efficiency and accuracy. Introduction DeepLearning has revolutionised artificial intelligence, driving advancements in natural language processing, computer vision, and more. Its global market size, valued at USD 17.60
Compliance and Rights Management AI automates regulatory document analysis, ensuring compliance with ever-evolving regulations. It monitors content portfolios for compliance with predefined rules and policies, automates documentation and reporting processes, and flags potential compliance violations or discrepancies.
The Challenge ¶ Motivation ¶ Much of the world's healthcare data is stored in free-text documents, usually clinical notes taken by doctors. In the inference phase each document is processed independently of the others. Gleb Sokolov is an experienced deeplearning engineer with a strong background in computer vision.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machine learning. product specifications, movie metadata, documents, etc.)
For instance, when developing a medical search engine, obtaining a large dataset of real user queries and relevant documents is often infeasible due to privacy concerns surrounding personal health information. These PDFs will serve as the source for generating document chunks.
text documents, software executables, and scientific data). Course information: 86 total classes 115+ hours of on-demand code walkthrough videos Last updated: October 2024 4.84 (128 Ratings) 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deeplearning.
The rise of Generative AI While generative AI has been around for several decades, it has only recently become a reality thanks to the development of deeplearning techniques. These techniques allow AI systems to learn from large amounts of data and generate new content that is indistinguishable from human-created content.
Graphics Processing Units (GPUs) have become the leading hardware accelerator for deeplearning applications and are used widely in training and inference of transformers; transformers have achieved state-of-the-art performance in many areas of machine learning and are especially used in most modern Large Language Models (LLMs).
We present the results of recent performance and power draw experiments conducted by AWS that quantify the energy efficiency benefits you can expect when migrating your deeplearning workloads from other inference- and training-optimized accelerated Amazon Elastic Compute Cloud (Amazon EC2) instances to AWS Inferentia and AWS Trainium.
He became a regular at AI hackathons, including the one where he met Reyes, whod written his thesis on deeplearning and worked on language models at Microsoft and Hugging Face. Similarly, if a project has code that lacks commentsembedded explanations documenting what the software is doing and how it does ita Droid can add them.
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
Better documentation with more examples , clearer explanations of the choices and tools, and a more modern look and feel. Find the latest at [link] (the old documentation will redirect here shortly). Project documentation ¶ As data science codebases live longer, code is often refactored into a package.
Limited memory Limited memory systems can learn from past experiences, enhancing their decision-making abilities over time. Legal: AI improves document analysis, streamlining legal research. 2010s: Advances in voice recognition and deeplearning techniques revolutionized AI capabilities.
For more information about the NoCapacityInvocationFailures metric, see documentation. SageMaker’s new Scale to Zero feature for GPU inference endpoints shows immense promise for deep fake detection operations. Depending on your use case, you can adjust ScalingAdjustment as required.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content