This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NaturalLanguageProcessing (NLP) is revolutionizing the way we interact with technology. By enabling computers to understand and respond to human language, NLP opens up a world of possibilitiesfrom enhancing user experiences in chatbots to improving the accuracy of search engines.
This article was published as a part of the Data Science Blogathon Overview Sentence classification is one of the simplest NLP tasks that have a wide range of applications including document classification, spam filtering, and sentiment analysis. A sentence is classified into a class in sentence classification.
Introduction DocVQA (Document Visual Question Answering) is a research field in computer vision and naturallanguageprocessing that focuses on developing algorithms to answer questions related to the content of a document, like a scanned document or an image of a text document.
Over the past few years, a shift has shifted from NaturalLanguageProcessing (NLP) to the emergence of Large Language Models (LLMs). Transformers, a type of DeepLearning model, have played a crucial role in the rise of LLMs.
Key components include machine learning, which allows systems to learn from data, and naturallanguageprocessing, enabling machines to understand and respond to human language. Limited memory Limited memory systems can learn from past experiences, enhancing their decision-making abilities over time.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
NaturalLanguageProcessing (NLP): Data scientists are incorporating NLP techniques and technologies to analyze and derive insights from unstructured data such as text, audio, and video. It is widely used for building and training machine learning models, particularly neural networks. H2O.ai: – H2O.ai
If a NaturalLanguageProcessing (NLP) system does not have that context, we’d expect it not to get the joke. identifying the “emotional tone” of a particular document). In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. deep” architecture). It’s all about context!
Introduction Naturallanguageprocessing (NLP) sentiment analysis is a powerful tool for understanding people’s opinions and feelings toward specific topics. NLP sentiment analysis uses naturallanguageprocessing (NLP) to identify, extract, and analyze sentiment from text data.
Source: Author The field of naturallanguageprocessing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce naturallanguage, NLP opens up a world of research and application possibilities.
Amazon Comprehend launches real-time classification Amazon Comprehend is a service which uses NaturalLanguageProcessing (NLP) to examine documents. Comprehend can now be used to classify documents in real-time. Document classification no longer needs to be performed in batch processes.
I work on machine learning for naturallanguageprocessing, and I’m particularly interested in few-shot learning, lifelong learning, and societal and health applications such as abuse detection, misinformation, mental ill-health detection, and language assessment.
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), naturallanguageprocessing (NLP), and recommendation systems. use train_dataloader in the rest of the training logic.
The advent of more powerful personal computers paved the way for the gradual acceptance of deeplearning-based methods. The introduction of attention mechanisms has notably altered our approach to working with deeplearning algorithms, leading to a revolution in the realms of computer vision and naturallanguageprocessing (NLP).
Their architecture is a beacon of parallel processing capability, enabling the execution of thousands of tasks simultaneously. This attribute is particularly beneficial for algorithms that thrive on parallelization, effectively accelerating tasks that range from complex simulations to deeplearning model training.
Photo by Brooks Leibee on Unsplash Introduction Naturallanguageprocessing (NLP) is the field that gives computers the ability to recognize human languages, and it connects humans with computers. SpaCy is a free, open-source library written in Python for advanced NaturalLanguageProcessing.
Source: Author Introduction Deeplearning, a branch of machine learning inspired by biological neural networks, has become a key technique in artificial intelligence (AI) applications. Deeplearning methods use multi-layer artificial neural networks to extract intricate patterns from large data sets.
Source: Author NaturalLanguageProcessing (NLP) is a field of study focused on allowing computers to understand and process human language. There are many different NLP techniques and tools available, including the R programming language. You must have defined your /.comet.yml
Summary: Attention mechanism in DeepLearning enhance AI models by focusing on relevant data, improving efficiency and accuracy. Introduction DeepLearning has revolutionised artificial intelligence, driving advancements in naturallanguageprocessing, computer vision, and more. from 2024 to 2032.
From virtual assistants like Siri and Alexa to personalized recommendations on streaming platforms, chatbots, and language translation services, language models surely are the engines that power it all. First Generation: Early language models used simple statistical techniques like n-grams to predict words based on the previous ones.
Summary: This blog delves into 20 DeepLearning applications that are revolutionising various industries in 2024. From healthcare to finance, retail to autonomous vehicles, DeepLearning is driving efficiency, personalization, and innovation across sectors.
Manually identifying all mentions of specific types of information in documents is extremely time-consuming and labor-intensive. This process must be repeated for every new document and entity type, making it impractical for processing large volumes of documents at scale.
For the detailed list of pre-set values, refer to the SDK documentation. For a full list of the available configs, including compute and networking, refer to the SDK documentation. We encourage you to try out the ModelTrainer class by referring to the SDK documentation and sample notebooks on the GitHub repo.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
NLP A Comprehensive Guide to Word2Vec, Doc2Vec, and Top2Vec for NaturalLanguageProcessing In recent years, the field of naturallanguageprocessing (NLP) has seen tremendous growth, and one of the most significant developments has been the advent of word embedding techniques. DM Architecture.
We present the results of recent performance and power draw experiments conducted by AWS that quantify the energy efficiency benefits you can expect when migrating your deeplearning workloads from other inference- and training-optimized accelerated Amazon Elastic Compute Cloud (Amazon EC2) instances to AWS Inferentia and AWS Trainium.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering naturallanguage questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
As higher-quality images need more processing power, it is unclear if Midjourney is near to achieving this objective; yet, this is certainly one of the most anticipated additions of Midjourney V6. Smarter naturallanguageprocessingNaturallanguageprocessing is another area in which Midjourney v6 will shine.
Home Table of Contents Deploying a Vision Transformer DeepLearning Model with FastAPI in Python What Is FastAPI? You’ll learn how to structure your project for efficient model serving, implement robust testing strategies with PyTest, and manage dependencies to ensure a smooth deployment process. Testing main.py
Intelligent documentprocessing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. Naturallanguageprocessing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience.
Jerome in his Study | Durer NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER The NLP Cypher | 03.14.21 Let’s talk about “Cryptonite: How I Stopped Worrying and Learned(?) LineFlow was designed to use in all deeplearning… github.com Repo Cypher ?? A new update is out!
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. She helps customers to build, train and deploy large machine learning models at scale.
In the recent past, using machine learning (ML) to make predictions, especially for data in the form of text and images, required extensive ML knowledge for creating and tuning of deeplearning models. These capabilities include pre-trained models for image, text, and document data types.
Unlocking the Power of LLM Use-Cases: AI applications now excel at summarizing articles, weaving narratives, and sparking conversations, all thanks to advanced large language models. Law Technology has greatly transformed the legal field, streamlining tasks like research and document drafting that once consumed lawyers’ time.
Question Answering is the task in NaturalLanguageProcessing that involves answering questions posed in naturallanguage. The goal of QA is to create models that can understand the nuances of a question and some given evidence documents to provide an accurate and concise answer. Haritz Puerto is a Ph.D.
This is because trades involve different counterparties and there is a high degree of variation among documents containing commercial terms (such as trade date, value date, and counterparties). Artificial intelligence and machine learning (AI/ML) technologies can assist capital market organizations overcome these challenges.
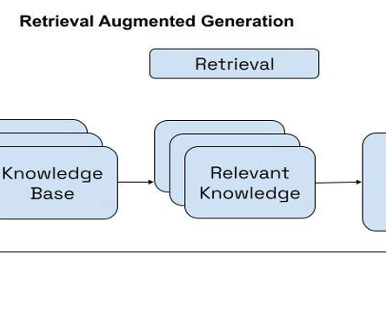
RAG is an approach that combines information retrieval techniques with naturallanguageprocessing (NLP) to enhance the performance of text generation or language modeling tasks. This method involves retrieving relevant information from a large corpus of text data and using it to augment the generation process.
Today, deeplearning technology, heavily influenced by Baidu’s seminal paper Deep Speech: Scaling up end-to-end speech recognition , dominates the field. In the next section, we’ll discuss how these deeplearning approaches work in more detail. How does speech recognition work?
In the first part of the series, we talked about how Transformer ended the sequence-to-sequence modeling era of NaturalLanguageProcessing and understanding. Having used multiple source documents, there have been duplicates and resulted in a huge set, which is impossible to train a model on, due to lack of processing power.
Computer Hardware At the core of any Generative AI system lies the computer hardware, which provides the necessary computational power to process large datasets and execute complex algorithms. Foundation Models Foundation models are pre-trained deeplearning models that serve as the backbone for various generative applications.
Choose Your Framework & Environment Flexibility is key : Google Gemma AI works seamlessly with popular deeplearning frameworks like JAX, PyTorch, and Keras 3.0 Explore and Experiment Google AI Gemma Website : Find quickstart guides, code samples, and detailed documentation. TensorFlow backend).
Footnotes These consisted of two evolving document graphs based on citation data and Reddit post data (predicting paper and post categories, respectively), and a multigraph generalization experiment based on a dataset of protein-protein interactions (predicting protein functions).
Dive into DeepLearning ( D2L.ai ) is an open-source textbook that makes deeplearning accessible to everyone. First, we put the source documents, reference documents, and parallel data training set in an S3 bucket. The ParallelData folder holds the parallel data input file prepared in the previous step.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content