This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
This function can be improved by AI and ML, which allow GIS to produce insights, automate procedures, and learn from data. Types of Machine Learning for GIS 1. Supervisedlearning– In supervisedlearning, the input data and associated output labels are paired, letting the system be trained on labelled data.
Machine learning applications in healthcare are revolutionizing the way we approach disease prevention and treatment Machine learning is broadly classified into three categories: supervisedlearning, unsupervised learning, and reinforcement learning.
There are various types of machine learning algorithms, including supervisedlearning, unsupervised learning, and reinforcement learning. In supervisedlearning, the model learns from labeled examples, where the input data is paired with corresponding target labels.
Machine learning types Machine learning algorithms fall into five broad categories: supervisedlearning, unsupervised learning, semi-supervisedlearning, self-supervised and reinforcement learning. the target or outcome variable is known). temperature, salary).
Its adaptability renders it well-suited for a multitude of applications, spanning from medical research and legal documentation to creative content generation. First Generation: Early language models used simple statistical techniques like n-grams to predict words based on the previous ones.
Semi-Supervised Sequence Learning As we all know, supervisedlearning has a drawback, as it requires a huge labeled dataset to train. Having used multiple source documents, there have been duplicates and resulted in a huge set, which is impossible to train a model on, due to lack of processing power.
Let’s first take a look at the process of supervisedlearning as motivation. Supervisedlearning The term supervisedlearning describes, at a high-level, one paradigm in which data can be used to train an AI model. They can summarize documents, translate between languages, answer questions, and more.
The core process is a general technique known as self-supervisedlearning , a learning paradigm that leverages the inherent structure of the data itself to generate labels for training. Fine-tuning may involve further training the pre-trained model on a smaller, task-specific labeled dataset, using supervisedlearning.
Using such data to train a model is called “supervisedlearning” On the other hand, pretraining requires no such human-labeled data. This process is called “self-supervisedlearning”, and is identical to supervisedlearning except for the fact that humans don’t have to create the labels.
Self-supervision: As in the Image Similarity Challenge , all winning solutions used self-supervisedlearning and image augmentation (or models trained using these techniques) as the backbone of their solutions. We believe VSC 2022 makes good social impact and is of great value to the deeplearning research community.
Despite its limitations, the Perceptron laid the groundwork for more complex neural networks and DeepLearning advancements. Introduction The Perceptron is one of the foundational concepts in Artificial Intelligence and Machine Learning.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents.
Though once the industry standard, accuracy of these classical models had plateaued in recent years, opening the door for new approaches powered by advanced DeepLearning technology that’s also been behind the progress in other fields such as self-driving cars. The data does not need to be force-aligned.
Machine Learning Basics Machine learning (ML) enables AI agents to learn patterns from data without explicit programming. There are three main types: SupervisedLearning: Training a model with labeled data. Unsupervised Learning: Finding hidden structures in unlabeled data. Hugging Face Documentation 3.
Without linear algebra, understanding the mechanics of DeepLearning and optimisation would be nearly impossible. These techniques span different types of learning and provide powerful tools to solve complex real-world problems. Neural networks are the foundation of DeepLearning techniques.
It builds on advances in deeplearning efficiency and leverages reinforcement learning from human feedback to provide more relevant responses and increase the model’s ability to follow instructions. We use deeplearning technology to achieve voice preservation and lip matching and enable high-quality video translation.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. They can also perform self-supervisedlearning to generalize and apply their knowledge to new tasks.
It includes text documents, social media posts, customer reviews, emails, and more. Here are seven benefits of text mining: Information Extraction Text mining enables the extraction of relevant information from unstructured text sources such as documents, social media posts, customer feedback, and more.
Step-by-Step Guide to Learning AI in 2024 Learning AI can seem daunting at first, but by following a structured approach, you can build a solid foundation and gain the skills needed to thrive in this field. This step-by-step guide will take you through the critical stages of learning AI from scratch. Let’s dive in!
Evaluation Techniques for Large Language Models Rajiv Shah, PhD | Machine Learning Engineer | Hugging Face Selecting the right LLM for your needs has become increasingly complex. In this workshop, you’ll see how to build both a simple QA bot as well as an automated workflow agent. Sign me up!
It is a supervisedlearning methodology that predicts if a piece of text belongs to one category or the other. As a machine learning engineer, you start with a labeled data set that has vast amounts of text that have already been categorized. Follow the official documentation for additional help with getting started with R.
supervisedlearning and time series regression). In the background, models are being trained in parallel for efficiency and speed—from Tree-based models to DeepLearning models (which will be chosen based on your historical data and target variable) and more. Generate Model Compliance Documentation.
Optimized Expert Time Active Learning ensures expert time is spent on cases where their expertise adds the most value. Key Characteristics Static Dataset : Works with a predefined set of unlabeled examples Batch Selection : Can select multiple samples simultaneously for labeling because of which it is widely used by deeplearning models.
Highlights included: Developed new deeplearning models for text classification, parsing, tagging, and NER with near state-of-the-art accuracy. Relaunched the spaCy website with almost 25k words of documentation and a dozen new usage tutorials, including an extensive spaCy 101 guide for beginners.
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). His specialty is Natural Language Processing (NLP) and is passionate about deeplearning.
Foundation models are AI models trained with machine learning algorithms on a broad set of unlabeled data that can be used for different tasks with minimal fine-tuning. The model can apply information it’s learned about one situation to another using self-supervisedlearning and transfer learning.
At the same time as the emergence of powerful RL systems in the real world, the public and researchers are expressing an increased appetite for fair, aligned, and safe machine learning systems. However the unique ability of RL systems to leverage temporal feedback in learning complicates the types of risks and safety concerns that can arise.
Using PyTorch DeepLearning Framework and CNN Architecture Photo by Andrew S on Unsplash Motivation Build a proof-of-concept for Audio Classification using a deep-learning neural network with PyTorch framework. This is inherently a supervisedlearning problem. Data Source here.
Unstructured Data: Data without a predefined structure, like text documents, social media posts, or images. Machine Learning: Subset of AI that enables systems to learn from data without being explicitly programmed. SupervisedLearning: Learning from labeled data to make predictions or decisions.
This section explores how entropy contributes to supervisedlearning , evaluates uncertainty or impurity in datasets, and finds applications across various Machine Learning algorithms and tasks. For instance, in document clustering, entropy can evaluate how well documents within a cluster share common topics.
In today’s modern era, we use data in various forms, such as videos, images, audio, and documents. Things become more complex when we apply this information to DeepLearning (DL) models, where each data type presents unique challenges for capturing its inherent characteristics. A vector embedding is an object (e.g., and Auli, M.,
Barron Program Advisory Board includes: Cordelia Schmid , Richard Szeliski Panels History and Future of Artificial Intelligence and Computer Vision Panelists include: Chelsea Finn Scientific Discovery and the Environment Panelists include: Sara Beery Best Paper Award candidates MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient (..)
Natural language processing (NLP): ML algorithms can be used to understand and interpret human language, enabling organizations to automate tasks such as customer support and document processing. Unsupervised learning: This involves using unlabeled data to identify patterns and relationships within the data.
Limited availability of labeled datasets: In some domains, there is a scarcity of datasets with fine-grained annotations, making it difficult to train segmentation networks using supervisedlearning algorithms. By default, ultralytics includes several models for each task with varying sizes.
Sheer volume—I think where this came about is when we had the rise of deeplearning, there was a much larger volume of data used, and of course, we had big data that was driving a lot of that because we found ourselves with these mountains of data. And in supervisedlearning, it has to be labeled data. AR : Yeah.
Sheer volume—I think where this came about is when we had the rise of deeplearning, there was a much larger volume of data used, and of course, we had big data that was driving a lot of that because we found ourselves with these mountains of data. And in supervisedlearning, it has to be labeled data. AR : Yeah.
Sheer volume—I think where this came about is when we had the rise of deeplearning, there was a much larger volume of data used, and of course, we had big data that was driving a lot of that because we found ourselves with these mountains of data. And in supervisedlearning, it has to be labeled data. AR : Yeah.
Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs. So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns.
" These models are trained using self-supervisedlearning , a technique that utilizes the data's inherent structure to generate labels for training. A language model can be fine-tuned on medical documents for specialized tasks in the medical field.
Important note: Continual learning aims to allow the model to effectively learn new concepts while ensuring it does not forget already acquired information. Plenty of CL techniques exist that are useful in various machine-learning scenarios. Model personalization via continual learning in a document classification process.
Decision Trees: A supervisedlearning algorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks. DeepLearning : A subset of Machine Learning that uses Artificial Neural Networks with multiple hidden layers to learn from complex, high-dimensional data.
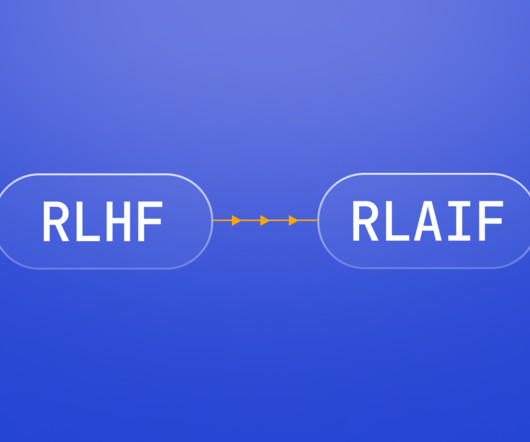
The model was fine-tuned to reduce false, harmful, or biased output using a combination of supervisedlearning in conjunction to what OpenAI calls Reinforcement Learning with Human Feedback (RLHF), where humans rank potential outputs and a reinforcement learning algorithm rewards the model for generating outputs like those that rank highly.
Natural language processing (NLP): ML algorithms can be used to understand and interpret human language, enabling organizations to automate tasks such as customer support and document processing. Unsupervised learning: This involves using unlabeled data to identify patterns and relationships within the data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















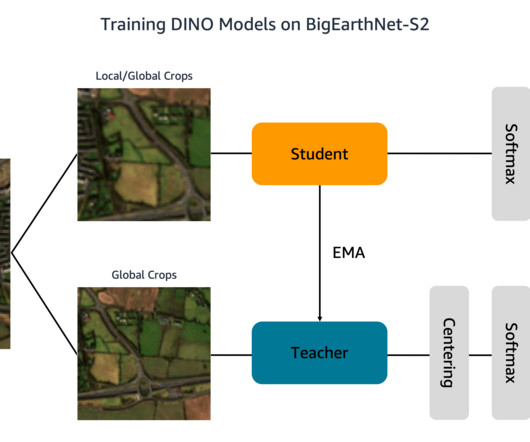

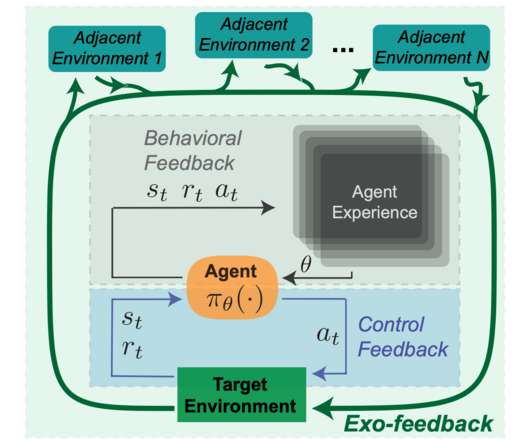





















Let's personalize your content