This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Start here with a simple Python pipeline that covers the essentials. Well grab data from a CSV file (like youd download from an e-commerce platform), clean it up, and store it in a proper database for analysis. In this article, Ill walk you through creating a pipeline that processes e-commerce transactions.
On Thursday, Google and the Computer History Museum (CHM) jointly released the source code for AlexNet , the convolutional neural network (CNN) that many credit with transforming the AI field in 2012 by proving that "deeplearning" could achieve things conventional AI techniques could not.
We will explore collections of tools, resources, tutorials, guides, and learning paths, all designed to help you maximize your learning journey in data science. This is a must-have bookmark for any data scientist working with Python, encompassing everything from data analysis and machine learning to web development and automation.
By Iván Palomares Carrascosa , KDnuggets Technical Content Specialist on July 4, 2025 in Python Image by Author | Ideogram Principal component analysis (PCA) is one of the most popular techniques for reducing the dimensionality of high-dimensional data. He trains and guides others in harnessing AI in the real world.
Home Table of Contents Getting Started with Python and FastAPI: A Complete Beginner’s Guide Introduction to FastAPI Python What Is FastAPI? Your First Python FastAPI Endpoint Writing a Simple “Hello, World!” Jump Right To The Downloads Section Introduction to FastAPI Python What Is FastAPI?
With Modal, you can configure your Python app, including system requirements like GPUs, Docker images, and Python dependencies, and then deploy it to the cloud with a single command. In this tutorial, we will learn how to set up Modal, create a vLLM server, and deploy it securely to the cloud. Create the a vllm_inference.py
This method involves setting up everything as specified in the official repo , running the Gradio app , and then demonstrating how to run YOLOv12 directly via Python and CLI without the Gradio UI. Create a new conda environment with Python 3.11: conda create -n yolov12 python=3.11 git checkout v1.0
To learn how to master YOLO11 and harness its capabilities for various computer vision tasks , just keep reading. Jump Right To The Downloads Section What Is YOLO11? Using Python # Load a model model = YOLO("yolo11n.pt") # Predict with the model results = model("[link] First, we load the YOLO11 object detection model.
Jump Right To The Downloads Section Need Help Configuring Your Development Environment? Spaces supports two primary SDKs (software development kits), Gradio and Streamlit , for building interactive ML demo apps in Python. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated?
Trainium chips are purpose-built for deeplearning training of 100 billion and larger parameter models. Model training on Trainium is supported by the AWS Neuron SDK, which provides compiler, runtime, and profiling tools that unlock high-performance and cost-effective deeplearning acceleration. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
70B through SageMaker JumpStart offers two convenient approaches: using the intuitive SageMaker JumpStart UI or implementing programmatically through the SageMaker Python SDK. Lokeshwaran Ravi is a Senior DeepLearning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. Deploy Llama 3.3
These improvements are available across a wide range of SageMaker’s DeepLearning Containers (DLCs), including Large Model Inference (LMI, powered by vLLM and multiple other frameworks), Hugging Face Text Generation Inference (TGI), PyTorch (Powered by TorchServe), and NVIDIA Triton.
Jump Right To The Downloads Section Introduction Cracks and potholes on the road aren’t just a nuisance. This is where deeplearning steps in — specifically, object detection models that can analyze images or videos of roads and automatically detect potholes. Defining Pothole Severity Can the Pothole Severity Logic Be Improved?
This lesson is the 2nd of a 3-part series on YOLOv12 : Breaking the CNN Mold: YOLOv12 Brings Attention to Real-Time Object Detection People Tracker with YOLOv12 and Centroid Tracker (this tutorial) Lesson 3 To learn how to monitor a people tracker in real-time using YOLOv12 and Centroid Tracker, just keep reading.
In this post, I’ll show you exactly how I did it with detailed explanations and Python code snippets, so you can replicate this approach for your next machine learning project or competition. The data came as a.parquet file that I downloaded using duckdb. I used my personal laptop, a MacBook Pro with 16GB RAM and no GPU.
Python or R) to find the critical value from the -distribution for the chosen and degrees of freedom ( ). Performing the Grubbs Test In this section, we will see how to perform the Grubbs test in Python for sample datasets with small sample sizes. Note: We need to use statistical tables ( Table 1 ) or software (e.g., Thakur, eds.,
SageMaker Large Model Inference (LMI) is deeplearning container to help customers quickly get started with LLM deployments on SageMaker Inference. One of the primary bottlenecks in the deployment process is the time required to download and load containers when scaling up endpoints or launching new instances.
References Physics-Informed Neural Networks: A DeepLearning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations , Raissi et al. 2021) Neural Operator: Learning Maps Between Function Spaces , Kovachki et al. 2019) Lagrangian Neural Networks , Cranmer et al. We build it.
First, set up your Python environment to run the examples: conda init eval $SHELL # Create a new env for the post conda create --name gsf python=3.10 amazonaws.com/graphstorm:sagemaker-cpu Download and prepare datasets In this post, we use two citation datasets to demonstrate the scalability of GraphStorm. million edges.
SageMaker AI provides distributed training libraries and supports various distributed training options for deeplearning tasks. Familiarity with Python and PyTorch for distributed training and model customization. Download the SQuaD dataset and upload it to SageMaker Lakehouse by following the steps in Uploading data.
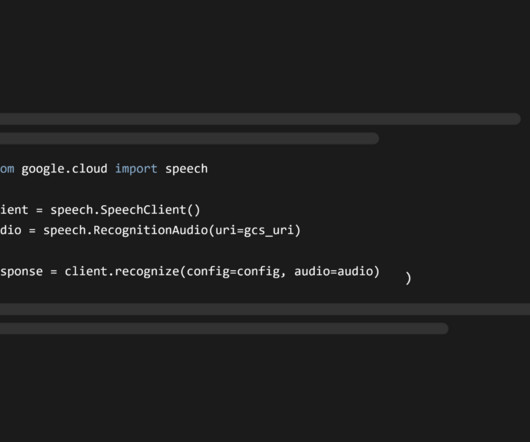
This tutorial will guide you through the process of using Google Cloud's Speech-to-Text API in your Python projects. The Google Cloud Speech-to-Text API is a service that enables developers to convert audio to text using DeepLearning models exposed through an API. This will download the JSON private key to your computer.
Jump Right To The Downloads Section Introduction In the previous post , we walked through the process of indexing and storing movie data in OpenSearch. If you havent already set up the project from the previous post, you can download the source code from the tutorials “Downloads” section. data queries_set_1.txt
This lesson is the last in a 2-part series on Vision-Language Models — SmolVLM : SmolVLM to SmolVLM2 : Compact Models for Multi-Image VQA Generating Video Highlights Using the SmolVLM2 Model (this tutorial) To learn how to create your own video highlights using the SmolVLM2 model, just keep reading. Looking for the source code to this post?
Jump Right To The Downloads Section What Is Matrix Diagonalization? The code uses the NumPy library, which can be installed in your Python environment via pip install numpy. Download the code! Looking for the source code to this post? Thakur, eds.,
Unleashed: Transforming Vision Tasks with AI : Content Moderation via Zero Shot Learning with Qwen 2.5 this tutorial) To learn how Qwen 2.5 Jump Right To The Downloads Section Enhanced Video Comprehension Ability in Qwen 2.5 To download the video locally, simply paste the video URL into any YouTube video downloader website (e.g.,
You will use DeepLearning AMI Neuron (Ubuntu 22.04) as your AMI, as shown in the following figure. r}") EOF Now, run the script python offline_inference.py If the container was terminated, the model will be downloaded again. You will use inf2.xlarge xlarge as your instance type. Increase the gp3 volume to 100 G.
To learn how to fine-tune the PaliGemma 2 model for detecting Valorant Objects, just keep reading. Jump Right To The Downloads Section How would you like immediate access to 3,457 images curated and labeled with hand gestures to train, explore, and experiment with … for free? Looking for the source code to this post?
Under Application and OS Images (Amazon Machine Image) , select an AWS DeepLearning AMI that comes preconfigured with NVIDIA OSS driver and PyTorch. For our deployment, we used DeepLearning OSS Nvidia Driver AMI GPU PyTorch 2.3.1 Amazon Linux 2). Next, complete the following steps to deploy Llama 3.2-3B
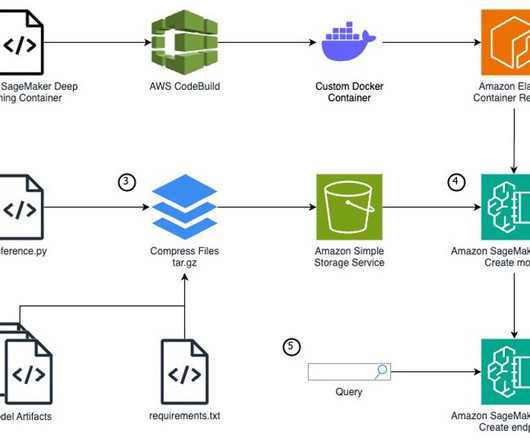
Write a Python model definition using the SageMaker inference.py You use an AWS DeepLearning SageMaker framework container as the base image because it includes required dependencies such as SageMaker libraries, PyTorch, and CUDA. file Now that you have downloaded the complete inference.py file format.
By extending a pre-built image, you can use the included deeplearning libraries and settings without having to create an image from scratch. In this application, we install or update a few libraries for running Llama.cpp in Python. You can also extend a pre-built container to accommodate your needs.
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models. b64encode(img).decode('utf-8')
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. Vision models. You can access the Meta Llama 3.2
medium instance with a Python 3 (ipykernel) kernel. SageMaker AI starts and manages all the necessary Amazon Elastic Compute Cloud (Amazon EC2) instances for us, supplies the appropriate containers, downloads data from our S3 bucket to the container and uploads and runs the specified training script, in our case fine_tune_llm.py.
This lesson is the 1st in a 2-part series on Vision-Language Models — SmolVLM : SmolVLM to SmolVLM2 : Compact Models for Multi-Image VQA (this tutorial) Generating Video Highlights Using the SmolVLM2 Model To learn about SmolVLMs and perform a multi-image understanding task, just keep reading. Looking for the source code to this post?
In our case, we don’t need such performance because we are downloading and loading the model weights when we are spinning up or scaling out an NVIDIA Dynamo deployment. Prerequisites To implement this solution, you must have the AWS Command Line Interface (AWS CLI), kubectl, helm, terraform, Docker, earthly, and Python 3.10+ installed.
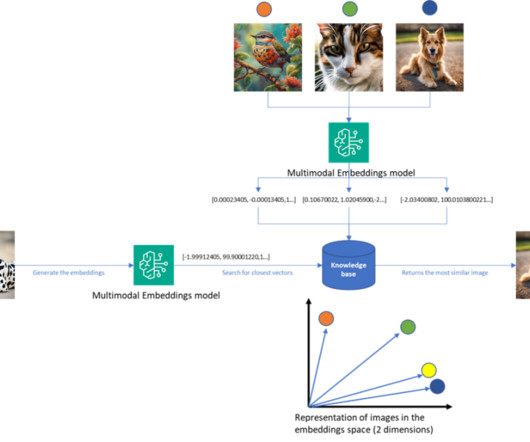
Building State-of-the-Art, Open-Source Embedding Models Andriy Mulyar, Founder & CTO of NomicAI Go behind the scenes of Nomic Embed, one of the most popular open-source embedding model families on Hugging Face, with over 35M+ downloads.
bashrc conda activate ft-embedding-blog Add the newly created Conda environment to Jupyter: python -m ipykernel install --user --name=ft-embedding-blog From the Launcher, open the repository folder named embedding-finetuning-blog and open the file Embedding Blog.ipynb. These PDFs will serve as the source for generating document chunks.
But how can we harness machine learning for something as niche as rice classification? Well, this is where PyTorch, a powerful deeplearning library, steps in. This hands-on tutorial is designed for anyone with a basic understanding of Python, and I’ll walk you through each step of the code so you can follow along effortlessly.
Using the Ollama API (this tutorial) To learn how to build a multimodal chatbot with Gradio, Llama 3.2, Jump Right To The Downloads Section What Is Gradio and Why Is It Ideal for Chatbots? Gradio is an open-source Python library that enables developers to create user-friendly and interactive web applications effortlessly.
Jump Right To The Downloads Section Overview of Ordinary Least Squares Ordinary Least Squares (OLS) is one of the popular and widely adopted methods of estimating the unknown parameters in a linear regression model. The code uses the NumPy library, which can be installed in your Python environment via pip install numpy.
These models are largely a manifestation of deeplearning architecture-based application with transformers being one of the most common which deals with understanding complex mapping within text data. They are designed utilizing deeplearning and most commonly with a transformer architecture. What Are Proprietary LLMs?
Jump Right To The Downloads Section Building on FastAPI Foundations In the previous lesson , we laid the groundwork for understanding and working with FastAPI. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? Looking for the source code to this post?
After your requested quotas are applied to your account, you can use the default Studio Python 3 (Data Science) image with an ml.t3.medium Walkthrough This post walks you through creating an EC2 instance, downloading and deploying the container image, and hosting a pre-trained language model and custom adapters from Amazon S3.
LLMs are large deeplearning models that are pre-trained on vast amounts of data. S3 Transfer Acceleration is a separate AWS service that can be integrated with Amazon S3 to improve the transfer speed of data uploads and downloads. Install Python 3.9 Lastly, build a Lambda layer that includes two Python libraries.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content