This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. That is, is giving supervision to adjust via.
Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g., If you are a regular PyImageSearch reader and have even basic knowledge of DeepLearning in Computer Vision, then this tutorial should be easy to understand. tomato, brinjal, and bottle gourd).
Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models. Transfer learning and better annotation tooling are both key to our current plans for spaCy and related projects.
There are three main types of machine learning : supervisedlearning, unsupervised learning, and reinforcement learning. SupervisedLearning In supervisedlearning, the algorithm is trained on a labelled dataset containing input-output pairs. predicting house prices).
Gradient boosting is a supervisedlearning algorithm that attempts to accurately predict a target variable by combining an ensemble of estimates from a set of simpler and weaker models. For CSV, we still recommend splitting up large files into smaller ones to reduce data download time and enable quicker reads. 16 1592 1412.2
Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? For instance, if a user who typically accesses the network during business hours suddenly logs in at midnight and starts downloading large amounts of data, this behavior would be considered anomalous.
Machine Learning Basics Machine learning (ML) enables AI agents to learn patterns from data without explicit programming. There are three main types: SupervisedLearning: Training a model with labeled data. Unsupervised Learning: Finding hidden structures in unlabeled data. Pandas: For data manipulation.
Additionally, both AI and ML require large amounts of data to train and refine their models, and they often use similar tools and techniques, such as neural networks and deeplearning. Inspired by the human brain, neural networks are crucial for deeplearning, a subset of ML that deals with large, complex datasets.
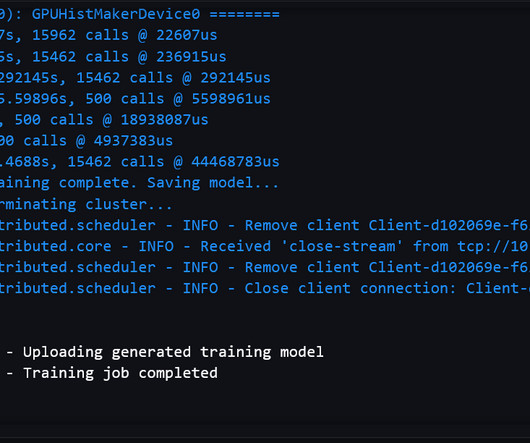
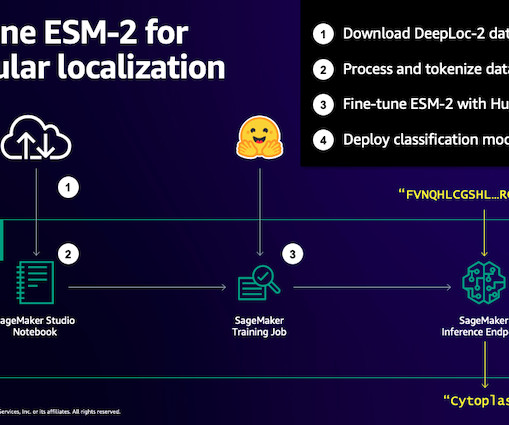
Similarly, pLMs are pre-trained on large protein sequence databases using unlabeled, self-supervisedlearning. We start by downloading a public dataset using Amazon SageMaker Studio. We can adapt them to predict things like the 3D structure of a protein or how it may interact with other molecules.
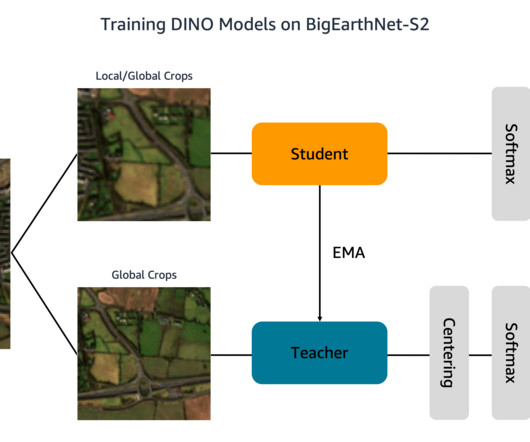
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). His specialty is Natural Language Processing (NLP) and is passionate about deeplearning.
You could imagine, for deeplearning, you need, really, a lot of examples. So, deeplearning, similarity search is a very easy, simple, task. And that’s the power of self-supervisedlearning. But desert, ocean, desert, in this way, I think that’s what the power of self-supervisedlearning is.
You could imagine, for deeplearning, you need, really, a lot of examples. So, deeplearning, similarity search is a very easy, simple, task. And that’s the power of self-supervisedlearning. But desert, ocean, desert, in this way, I think that’s what the power of self-supervisedlearning is.
It is a supervisedlearning methodology that predicts if a piece of text belongs to one category or the other. As a machine learning engineer, you start with a labeled data set that has vast amounts of text that have already been categorized. Create a new R Script and call it train.R.
Limited availability of labeled datasets: In some domains, there is a scarcity of datasets with fine-grained annotations, making it difficult to train segmentation networks using supervisedlearning algorithms. kaggle datasets download haziqasajid5122/yolov8-finetuning-dataset-ducks !unzip
Learn more Building DeepLearning-Based OCR Model: Lessons Learned What is triplet network training? You can actually improve embeddings and train embeddings in a self-supervised way. How self-supervisedlearning works. In a situation that-, what do you mean by downloading? This is new to me.
Train an ML model on the preprocessed images, using a supervisedlearning approach to teach the model to distinguish between different skin types. Download the HAM10000 dataset. Jake Wen is a Solutions Architect at AWS, driven by a passion for Machine Learning, Natural Language Processing, and DeepLearning.
In HPO mode, SageMaker Canvas supports the following types of machine learning algorithms: Linear learner: A supervisedlearning algorithm that can solve either classification or regression problems. Deeplearning algorithm: A multilayer perceptron (MLP) and feedforward artificial neural network.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content