This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. Introduction Have you ever struggled with managing complex data transformations?
In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deeplearning, aimed at assisting users in advancing their careers. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution.
Key Skills: Mastery in machine learning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods. Stanford AI Lab recommends proficiency in deeplearning, especially if working in experimental or cutting-edge areas.
Since data warehouses can deal only with structured data, they also require extract, transform, and load (ETL) processes to transform the raw data into a target structure ( Schema on Write ) before storing it in the warehouse. Therefore, ETL processes are usually required to be built around the data warehouse.
Instead, we use pre-trained deeplearning models like VGG or ResNet to extract feature vectors from the images. Image retrieval search architecture The architecture follows a typical machine learning workflow for image retrieval. Towhee is a framework that provides ETL for unstructured data using SoTA machine learning models.
To solve this problem, we build an extract, transform, and load (ETL) pipeline that can be run automatically and repeatedly for training and inference dataset creation. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account. AutoGluon is a toolkit for automated machine learning (AutoML).
20212024: Interest declined as deeplearning and pre-trained models took over, automating many tasks previously handled by classical ML techniques. While traditional machine learning remains fundamental, its dominance has waned in the face of deeplearning and automated machine learning (AutoML).
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset. He believes deeplearning will power future technology growth.
Just like this in Data Science we have Data Analysis , Business Intelligence , Databases , Machine Learning , DeepLearning , Computer Vision , NLP Models , Data Architecture , Cloud & many things, and the combination of these technologies is called Data Science. Data Science and AI are related?
These are used to extract, transform, and load (ETL) data between different systems. Data integration tools allow for the combining of data from multiple sources. The most popular of these tools are Talend, Informatica, and Apache NiFi.
Photo by Jeroen den Otter on Unsplash Who should read this article: Machine and DeepLearning Engineers, Solution Architects, Data Scientist, AI Enthusiast, AI Founders What is covered in this article? Continuous training is the solution. This article explains how to build a continuous and automated model training pipeline.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deeplearning to the team. They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs.
Solution overview The following diagram shows the architecture reflecting the workflow operations into AI/ML and ETL (extract, transform, and load) services. Here, a non-deeplearning model was trained and run on SageMaker, the details of which will be explained in the following section.
It uses advanced deeplearning technologies to accurately transcribe audio into text. It’s useful for coordinating tasks, distributed processing, ETL (extract, transform, and load), and business process automation. Step Functions lets you create serverless workflows to orchestrate and connect components across AWS services.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks. He holds a Ph.D.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deeplearning. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered.
Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Machine Learning: Supervised and unsupervised learning techniques, deeplearning, etc. ETL Tools: Apache NiFi, Talend, etc. Read more to know. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Advanced Data Processing Capabilities KNIME provides a wide range of nodes for data extraction, transformation, and loading (ETL), but it also offers advanced data manipulation and processing capabilities. This includes machine learning , statistical modeling, and text mining, among others.
These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines. Multimodal embeddings help combine unstructured data from various sources in data warehouses and ETL pipelines. The features extracted in the ETL process would then be inputted into the ML models.
New Tool Thunder Hopes to Accelerate AI Development Thunder is a new compiler designed to turbocharge the training process for deeplearning models within the PyTorch ecosystem. Learn more about them here!
In the era of Industry 4.0 , linking data from MES (Manufacturing Execution System) with that from ERP, CRM and PLM systems plays an important role in creating integrated monitoring and control of business processes.
TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations. Hesham Fahim is a Lead Machine Learning Engineer and Personalization Engine Architect at Thomson Reuters.
This article was published as a part of the Data Science Blogathon. Introduction Apache Pig is a high-level programming language that may be used to analyse massive amounts of data. The pig was developed as a consequence of Yahoo’s Development efforts. Programs must be converted into a succession of Map and Reduce stages in a MapReduce […].
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. You have learned how to trigger a DAG in Airflow, create a DAG from scratch, and initiate its execution. We pay our contributors, and we don't sell ads.
While dealing with larger quantities of data, you will likely be working with Data Engineers to create ETL (extract, transform, load) pipelines to get data from new sources. You will need to learn to query different databases depending on which ones your company uses. In the industry, deeplearning is not always the preferred approach.
Related article How to Build ETL Data Pipelines for ML See also MLOps and FTI pipelines testing Once you have built an ML system, you have to operate, maintain, and update it. Some ML systems use deeplearning, while others utilize more classical models like decision trees or XGBoost.
Furthermore, in addition to common extract, transform, and load (ETL) tasks, ML teams occasionally require more advanced capabilities like creating quick models to evaluate data and produce feature importance scores or post-training model evaluation as part of an MLOps pipeline. In her spare time, she enjoys movies, music, and literature.
Understanding ETL (Extract, Transform, Load) processes is vital for students. Unsupervised Learning Exploring clustering techniques like k-means and hierarchical clustering, along with dimensionality reduction methods such as PCA (Principal Component Analysis). Students should learn about neural networks and their architecture.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? Explain the Extract, Transform, Load (ETL) process. The ETL process involves extracting data from source systems, transforming it into a suitable format or structure, and loading it into a data warehouse or target system for analysis and reporting.
As computational power increased and data became more abundant, AI evolved to encompass machine learning and data analytics. This close relationship allowed AI to leverage vast amounts of data to develop more sophisticated models, giving rise to deeplearning techniques.
DeepLearning Techniques Used to Manage Unstructured Data Now that you have seen some of the tools used in unstructured data management let’s explore the deeplearning techniques you can use to process and understand unstructured data. is similar to the traditional Extract, Transform, Load (ETL) process.
About the Authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. Andrei has a Master’s in CS from the University of Toronto, where he was a researcher at the intersection of deeplearning, robotics, and autonomous driving.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. It really depends on what you have to do to stitch together a flow of data to transform for your deeplearning use case.
About the Authors Siokhan Kouassi is a Data Scientist at Parameta Solutions with expertise in statistical machine learning, deeplearning, and generative AI. Visit the Amazon Bedrock console to start building your first flow, and explore our AWS Blog for more customer success stories and implementation patterns.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















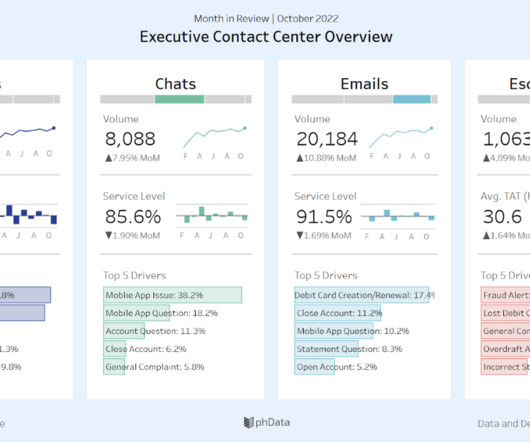








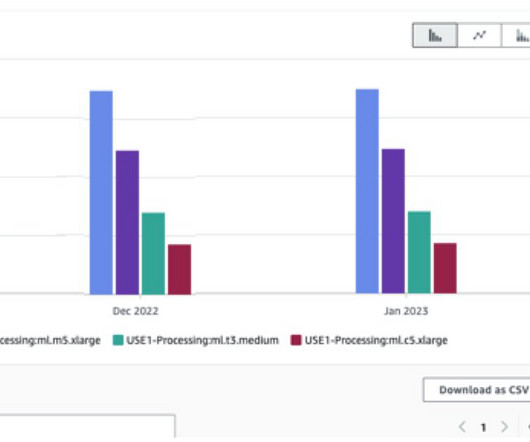













Let's personalize your content