This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Making visualizations is one of the finest ways for data scientists to explain dataanalysis to people outside the business. Exploratorydataanalysis can help you comprehend your data better, which can aid in future data preprocessing. ExploratoryDataAnalysis What is EDA?
In data science, use linear algebra for understanding the statistical graphs. Probability is the measurement of the likelihood of events. Probability distributions are collections of all events and their probabilities. Knowledge of probability distributions is needed for understanding and predicting data. DeepLearning.
Model architectures : All four winners created ensembles of deeplearning models and relied on some combination of UNet, ConvNext, and SWIN architectures. We take a gap year to participate in AI competitions and projects, and organize and attend events. tuning the threshold for submit to match kelp distribution on training data.
If your dataset is not in time order (time consistency is required for accurate Time Series projects), DataRobot can fix those gaps using the DataRobot Data Prep tool , a no-code tool that will get your data ready for Time Series forecasting. Prepare your data for Time Series Forecasting. Perform exploratorydataanalysis.
Comet is an MLOps platform that offers a suite of tools for machine-learning experimentation and dataanalysis. It is designed to make it easy to track and monitor experiments and conduct exploratorydataanalysis (EDA) using popular Python visualization frameworks.
Comet Comet is a platform for experimentation that enables you to monitor your machine-learning experiments. Comet has another noteworthy feature: it allows us to conduct exploratorydataanalysis. You can learn more about Comet here. train.head() We also perform EDA on the test dataset.
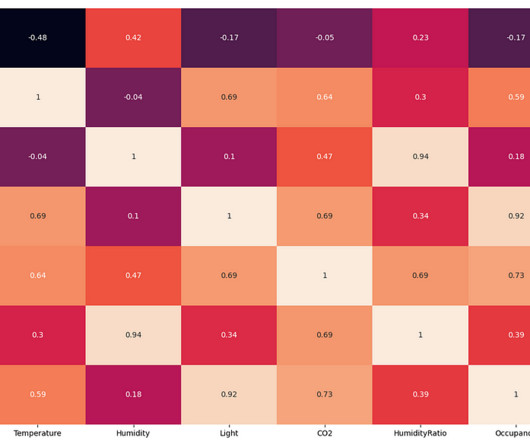
The exploratorydataanalysis found that the change in room temperature, CO levels, and light intensity can be used to predict the occupancy of the room in place of humidity and humidity ratio. We will also be looking at the correlation between the variables.
I will start by looking at the data distribution, followed by the relationship between the target variable and independent variables. Editor's Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deeplearning practitioners.
The process begins with a careful observation of customer data and an assessment of whether there are naturally formed clusters in the data. After that, there is additional exploratorydataanalysis to understand what differentiates each cluster from the others. Interested in attending an ODSC event?
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. AB : Makes sense.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deeplearning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. AB : Makes sense.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. AB : Makes sense.
About Comet Comet is an experimentation tool that helps you keep track of your machine-learning studies. Another significant aspect of Comet is that it enables us to carry out exploratorydataanalysis. You can learn more about Comet here. If you’d like to contribute, head on over to our call for contributors.
This allows Data Scientists to bring their existing code, libraries, and workflows into the Azure ecosystem without disruption. Support for DeepLearning Frameworks It integrates with TensorFlow, PyTorch, and other DeepLearning frameworks, providing scalable infrastructure for training and deploying complex models.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. Batch size and learning rate are two important hyperparameters that can significantly affect the training of deeplearning models, including LLMs.
Diagnostic Analytics Projects: Diagnostic analytics seeks to determine the reasons behind specific events or patterns observed in the data. It involves deeper analysis and investigation to identify the root causes of problems or successes. Root cause analysis is a typical diagnostic analytics task. ImageNet).
In a typical MLOps project, similar scheduling is essential to handle new data and track model performance continuously. Load and Explore Data We load the Telco Customer Churn dataset and perform exploratorydataanalysis (EDA). Experiment Tracking in CometML (Image by the Author) 2.
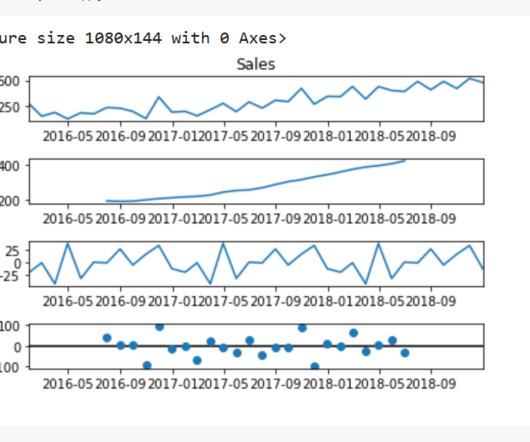
Making Data Stationary: Many forecasting models assume stationarity. If the data is non-stationary, apply transformations like differencing or logarithmic scaling to stabilize its statistical properties. ExploratoryDataAnalysis (EDA): Conduct EDA to identify trends, seasonal patterns, and correlations within the dataset.
In this article, let’s dive deep into the Natural Language Toolkit (NLTK) data processing concepts for NLP data. Before building our model, we will also see how we can visualize this data with Kangas as part of exploratorydataanalysis (EDA).
As discussed in the previous article , these challenges may include: Automating the data preprocessing workflow of complex and fragmented data. Monitoring models in production and continuously learning in an automated way, so being prepared for real estate market shifts or unexpected events.
Decision Trees: A supervised learning algorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks. DeepLearning : A subset of Machine Learning that uses Artificial Neural Networks with multiple hidden layers to learn from complex, high-dimensional data.
Mid-point review and challenge Q&A event. This challenge included two optional milestones to help solvers understand the challenge goals and learn how well their solution aligned with those goals, an opportunity to get feedback via a mid-point review and a Q&A event. Overall and bonus prize structure.
It is important to experience such problems as they reflect a lot of the issues that a data practitioner is bound to experience in a business environment. We first get a snapshot of our data by visually inspecting it and also performing minimal ExploratoryDataAnalysis just to make this article easier to follow through.
Email classification project diagram The workflow consists of the following components: Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratorydataanalysis (EDA), data cleaning and preparation, and building prototype models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content