This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Photo by Avi Waxman on Unsplash What is KNN DefinitionK-NearestNeighbors (KNN) is a supervised algorithm. The basic idea behind KNN is to find Knearest data points in the training space to the new data point and then classify the new data point based on the majority class among the knearest data points.
Traditional exact nearestneighbor search methods (e.g., brute-force search and k -nearestneighbor (kNN)) work by comparing each query against the whole dataset and provide us the best-case complexity of. With reaching billions, no hardware can process these operations in a definite amount of time.
Decision trees and K-nearestneighbors (KNN) Both decision trees and KNN play vital roles in classification and prediction. Decision trees provide clear, visual representations of decision-making processes, while KNN classifies data based on the proximity of neighboring points.
MongoDB Atlas Vector Search uses a technique called k-nearestneighbors (k-NN) to search for similar vectors. k-NN works by finding the k most similar vectors to a given vector. Vector data is a type of data that represents a point in a high-dimensional space.
The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. What are KNearestNeighbors in Machine Learning? Definition of KNN Algorithm KNearestNeighbors (KNN) is a simple yet powerful machine learning algorithm for classification and regression tasks.
The prediction is then done using a k-nearestneighbor method within the embedding space. In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations. XMLC overview The goal of an XMLC model is to predict a set of labels for a specific test input.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
K-NearestNeighborK-nearestneighbor (KNN) ( Figure 8 ) is an algorithm that can be used to find the closest points for a data point based on a distance measure (e.g., Figure 8: K-nearestneighbor algorithm (source: Towards Data Science ).
So in these two plots, we actually calculated the largest connected component based on the K-nearestneighbor graph for different values of k and we plotted the CDF. So have you tried other clustering approaches other than K-means, and how does that impact this entire process? AB : Got it. Thank you. CC : Oh, yes.
So in these two plots, we actually calculated the largest connected component based on the K-nearestneighbor graph for different values of k and we plotted the CDF. So have you tried other clustering approaches other than K-means, and how does that impact this entire process? AB : Got it. Thank you. CC : Oh, yes.
So in these two plots, we actually calculated the largest connected component based on the K-nearestneighbor graph for different values of k and we plotted the CDF. So have you tried other clustering approaches other than K-means, and how does that impact this entire process? AB : Got it. Thank you. CC : Oh, yes.
Some common quantitative evaluations are linear probing , Knearestneighbors (KNN), and fine-tuning. They have done a very comprehensive study regarding this topic so lot of things we can talk about. Thus, it is better to begin with a general one. Besides that, there is also qualitative evaluation.
Role context – Start each prompt with a clear role definition. Modular prompts – Split prompts into section-specific chunks for enhanced accuracy and reduced latency, because it allows the LLM to focus on a smaller context at a time. For example, “Separate prompts for executive summary and opportunity pipeline sections.”
K-NearestNeighbor Regression Neural Network (KNN) The k-nearestneighbor (k-NN) algorithm is one of the most popular non-parametric approaches used for classification, and it has been extended to regression.
You can approximate your machine learning training components into some simpler classifiers—for example, a k-nearestneighbors classifier. That is something that, with this k-nearestneighbor proxy thing, to a certain extent we are able to achieve. It is definitely a very important problem.
You can approximate your machine learning training components into some simpler classifiers—for example, a k-nearestneighbors classifier. That is something that, with this k-nearestneighbor proxy thing, to a certain extent we are able to achieve. It is definitely a very important problem.
Understanding Image Embeddings Definition and Basics At its core, image embedding, also referred to as latent vector or representation, is a technique that transforms high-dimensional image data into a more manageable, lower-dimensional numerical representation. As we can see, applications of image embeddings can vary.
In this article, we will explore the definitions, differences, and impacts of bias and variance, along with strategies to strike a balance between them to create optimal models that outperform the competition. K-NearestNeighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance.
Key steps involve problem definition, data preparation, and algorithm selection. K-NearestNeighbors), while others can handle large datasets efficiently (e.g., Key Takeaways Machine Learning Models are vital for modern technology applications. Types include supervised, unsupervised, and reinforcement learning.
The K-NearestNeighbor Algorithm is a good example of an algorithm with low bias and high variance. This trade-off can easily be reversed by increasing the k value which in turn results in increasing the number of neighbours. You will definitely succeed. Let us see some examples.
Definition and importance of machine learning algorithms The core value of machine learning algorithms lies in their capacity to process and analyze vast amounts of data efficiently. K-nearestneighbors (KNN): Classifies based on proximity to other data points.
Definition and structure of feature vectors A feature vector contains numerical values that represent the attributes of an observed phenomenon. Classification problems In classification tasks, feature vectors assist algorithms like neural networks and k-nearestneighbors in making informed predictions based on historical data.
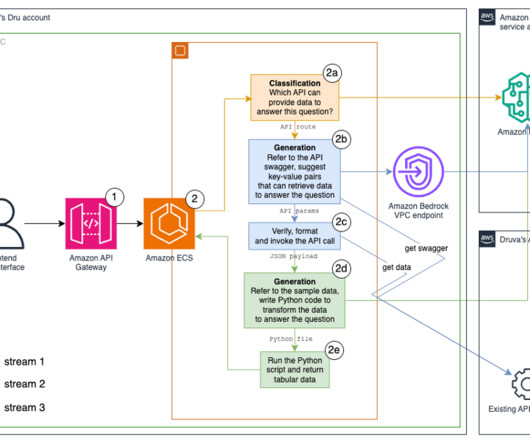
We tried different methods, including k-nearestneighbor (k-NN) search of vector embeddings, BM25 with synonyms , and a hybrid of both across fields including API routes, descriptions, and hypothetical questions. Look up the API definition This step uses an FM to perform classification.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content