This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. That is, is giving supervision to adjust via.
I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’. Photo by Andrea De Santis on Unsplash So, What is Machine Learning? Definition says, machine learning is the ability of computers to learn without explicit programming.
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Building a Machine Learning platform (Lemonade). Design Patterns in Machine Learning for MLOps (by Pier Paolo Ippolito).
A lot of people are building truly new things with Large Language Models (LLMs), like wild interactive fiction experiences that weren’t possible before. But if you’re working on the same sort of NaturalLanguageProcessing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them?
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. Unsupervised learning: This involves using unlabeled data to identify patterns and relationships within the data. Level of human intervention: Minimal human intervention required.
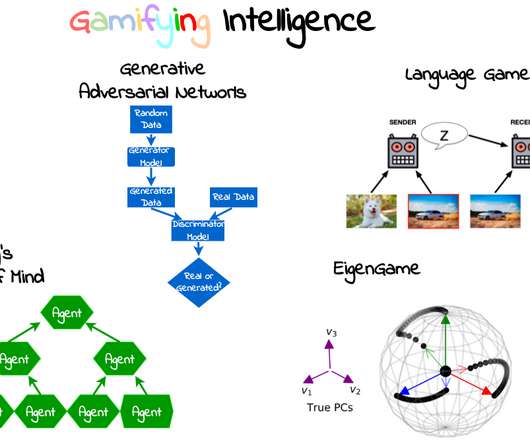
Our internal agents are playing games until they learn how to cooperate and trick us into believing we are an individual. Gamification There are many definitions for what a game is. Language as a game: the field of Emergent Communication Firstly, what is language? Do you think there is something odd in this definition?
This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
Data mining is the process of discovering these patterns among the data and is therefore also known as Knowledge Discovery from Data (KDD). The former is a term used for models where the data has been labeled, whereas, unsupervised learning, on the other hand, refers to unlabeled data. Classification. Regression.
Summary: This article compares Artificial Intelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. While AI aims to replicate human intelligence across various domains, ML focuses on learning from data to improve performance.
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. Unsupervised learning: This involves using unlabeled data to identify patterns and relationships within the data. Level of human intervention: Minimal human intervention required.
Introduced by Claude Shannon in 1948, entropy revolutionised how we measure information and remains central to modern Data Science, including Machine Learning. Lets delve into its mathematical definition and key properties. Lets explore its definition, connection to entropy, and practical applications.
Large language models (LLMs) are a class of foundational models (FM) that consist of layers of neural networks that have been trained on these massive amounts of unlabeled data. Large language models (LLMs) have taken the field of AI by storm.
ChatGPT is a next-generation language model (referred to as GPT-3.5) While this technology is definitely entertaining, it’s not quite clear yet how it can effectively be applied to the needs of the typical enterprise. They can be fine-tuned on a smaller dataset to perform a specific task, such as language translation or summarization.
Such models can also learn from a set of few examples The process of presenting a few examples is also called In-Context Learning , and it has been demonstrated that the process behaves similarly to supervisedlearning. Either way, language models, like ChatGPT. Will ChatGPT replace your job?
Key Takeaways Machine Learning Models are vital for modern technology applications. Types include supervised, unsupervised, and reinforcement learning. Key steps involve problem definition, data preparation, and algorithm selection. Ethical considerations are crucial in developing fair Machine Learning solutions.
But I definitely think there’s still much more to come. SyntaxNet provides an important module in a naturallanguageprocessing (NLP) pipeline such as spaCy. The thing that’s really significant is how quickly the speed and accuracy of naturallanguageprocessing technologies is advancing. What’s next?
Unsupervised learning has shown a big potential in large language models but high-quality labelled data remains the gold standard for AI systems to be accurate and aligned with human language and understanding. Text labeling has enabled all sorts of frameworks and strategies in machine learning.
Unsupervised learning has shown a big potential in large language models but high-quality labelled data remains the gold standard for AI systems to be accurate and aligned with human language and understanding. Text labeling has enabled all sorts of frameworks and strategies in machine learning.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, Machine Learning, NaturalLanguageProcessing , Statistics and Mathematics. After that, move towards unsupervised learning methods like clustering and dimensionality reduction.
As humans, we learn a lot of general stuff through self-supervisedlearning by just experiencing the world. DK: I’m a big fan of the HELM (Holistic Evaluation of Language Models) project and Percy Liang’s work there and in general. Naturallanguageprocessing itself shouldn’t just focus on text.
As humans, we learn a lot of general stuff through self-supervisedlearning by just experiencing the world. DK: I’m a big fan of the HELM (Holistic Evaluation of Language Models) project and Percy Liang’s work there and in general. Naturallanguageprocessing itself shouldn’t just focus on text.
An In-depth Look into Evaluating AI Outputs, Custom Criteria, and the Integration of Constitutional Principles Photo by Markus Winkler on Unsplash Introduction In the age of conversational AI, chatbots, and advanced naturallanguageprocessing, the need for systematic evaluation of language models has never been more pronounced.
Up-to-date knowledge about naturallanguageprocessing is mostly locked away in academia. Averaged Perceptron POS tagging is a “supervisedlearning problem”. And it definitely doesn’t matter enough to adopt a slow and complicated algorithm like Conditional Random Fields. We’re careful. Here’s the problem.
Large language models (LLMs) can be used to perform naturallanguageprocessing (NLP) tasks ranging from simple dialogues and information retrieval tasks, to more complex reasoning tasks such as summarization and decision-making. This leads to responses that are untruthful, toxic, or simply not helpful to the user.
This deep learning model is designed to extract hierarchical representations from unlabeled data, setting a strong foundation for tasks across various domains, including image recognition and naturallanguageprocessing. Here, labeled data comes into play as it is used for supervisedlearning.
These sophisticated algorithms facilitate a deeper understanding of data, enabling applications from image recognition to naturallanguageprocessing. What is deep learning? Deep learning is a subset of artificial intelligence that utilizes neural networks to process complex data and generate predictions.
Definition and characteristics of algorithms Algorithms are characterized by their systematic procedures. Machine learning as an algorithm example Machine learning encompasses a variety of algorithms that learn from data and improve over time. It represents a logical framework for approaching tasks and finding solutions.
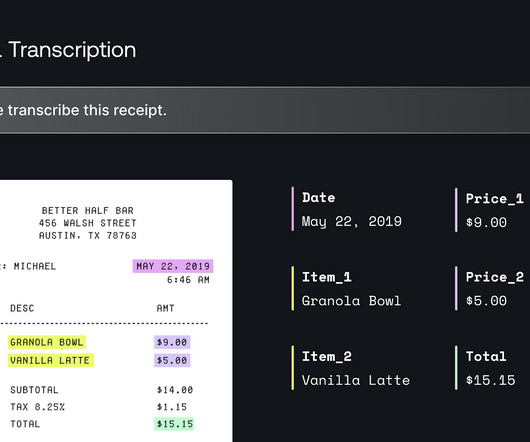
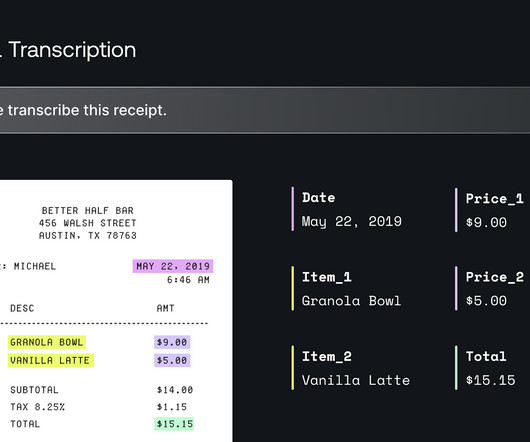
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. When you evaluate a case, evaluate the definitions in order and label the case with the first definition that fits.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content