This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. That is, is giving supervision to adjust via.
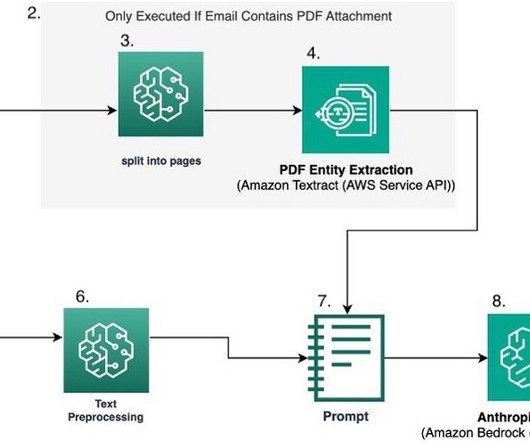
Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. An FM-driven solution can also provide rationale for outputs, whereas a traditional classifier lacks this capability.
Support Vector Machines (SVM) are a type of supervisedlearning algorithm designed for classification and regression tasks. Definition of SVM SVMs operate on the principle of finding the hyperplane that maximizes the margin between different classes. What are Support Vector Machines (SVM)?
“Self-Supervised methods […] are going to be the main method to train neural nets before we train them for difficult tasks” — Yann LeCun Well! Let’s have a look at this Self-SupervisedLearning! Let’s have a look at Self-SupervisedLearning. That is why it is called Self -SupervisedLearning.
NOTES, DEEP LEARNING, REMOTE SENSING, ADVANCED METHODS, SELF-SUPERVISEDLEARNING A note of the paper I have read Photo by Kelly Sikkema on Unsplash Hi everyone, In today’s story, I would share notes I took from 32 pages of Wang et al., Taxonomy of the self-supervisedlearning Wang et al. 2022’s paper.
At the early era of Artificial Intelligence, programmers tried to teach machines from the definition of logical rules that the machine itself could extend during the execution of the program. Although there are many types of learning, Michalski defined the two most common types of learning: SupervisedLearning.
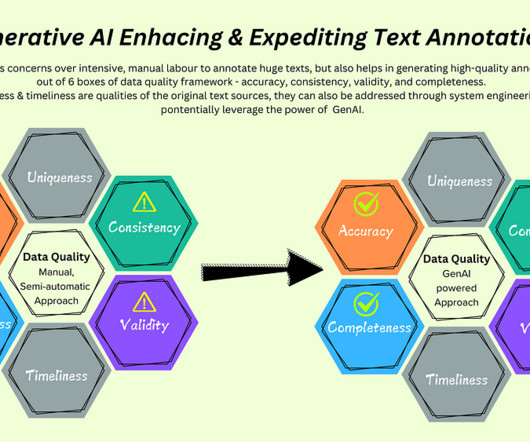
How do you tell the Machine Learning models the meaning of a particular word, especially when they are quantitatively intelligent and lexically challenged? This definitely estimates the spectrum of usage of text annotations to cater to the demands of the AI revolution across various industries. Behind the Medium paywall?
Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models. Transfer learning and better annotation tooling are both key to our current plans for spaCy and related projects.
The below animation demonstrates this process: 0:00 / 1× Since the Language Model is, by definition, a probability distribution over word sequences, we generate text by simply recursively asking for the most likely next word given all of our previous words. Yes, it really is that simple. Can we do better?
That’s definitely new. Once you’re past prototyping and want to deliver the best system you can, supervisedlearning will often give you better efficiency, accuracy and reliability than in-context learning for non-generative tasks — tasks where there is a specific right answer that you want the model to find.
I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’. Photo by Andrea De Santis on Unsplash So, What is Machine Learning? Definition says, machine learning is the ability of computers to learn without explicit programming.
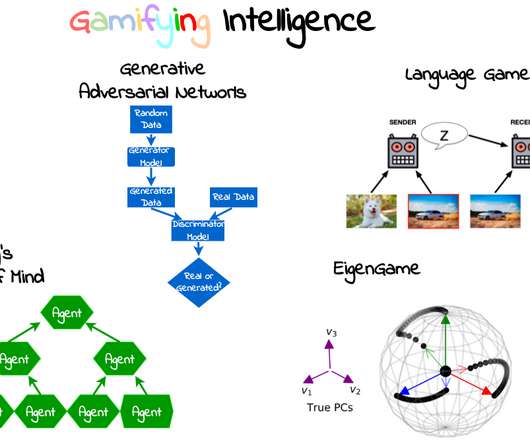
Our internal agents are playing games until they learn how to cooperate and trick us into believing we are an individual. Gamification There are many definitions for what a game is. Techniques developed in NLP, such as the Transformer architecture, are useful in very diverse fields such as computer vision and reinforcement learning.
2 Denn heute spielt die Definition darüber, was Big Data eigentlich genau ist, wirklich keine Rolle mehr. GPT-3 wurde mit mehr als 100 Milliarden Wörter trainiert, das parametrisierte Machine Learning Modell selbst wiegt 800 GB (quasi nur die Neuronen!) Neben SupervisedLearning kam auch Reinforcement Learning zum Einsatz.
I definitely recommend watching this one for all learners out here! Ramcharan12345 is looking to collaborate with AI devs who can leverage spaCy for NLP, utilize scikit-learn for supervisedlearning on historical data for symptom mapping, and implement TensorFlow/Keras for neural network-based risk prediction.
Typically, you let the experts read some articles, label them, and then use them as training data and train the supervisedlearning model. To address all these problems, we looked into weak supervisedlearning. Once we label a fraction of documents, we use that as training data to train the supervisedlearning model.
Typically, you let the experts read some articles, label them, and then use them as training data and train the supervisedlearning model. To address all these problems, we looked into weak supervisedlearning. Once we label a fraction of documents, we use that as training data to train the supervisedlearning model.
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. Unsupervised learning: This involves using unlabeled data to identify patterns and relationships within the data. Technology: Includes a range of technologies, including ML and deep learning.
A definition from the book ‘Data Mining: Practical Machine Learning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Classification. Regression.
Such models can also learn from a set of few examples The process of presenting a few examples is also called In-Context Learning , and it has been demonstrated that the process behaves similarly to supervisedlearning. Although the model acts as a highly-skilled, the profession definitely carries a lot of risks.
A large percentage of ML projects are based on supervisedlearning, which is very dependent on good feature selection. But then, Robert, what do you think are some of the challenges applied folks in the supervisedlearning space face when trying to productionize these use cases? That actually brings us to a good point.
A large percentage of ML projects are based on supervisedlearning, which is very dependent on good feature selection. But then, Robert, what do you think are some of the challenges applied folks in the supervisedlearning space face when trying to productionize these use cases? That actually brings us to a good point.
A large percentage of ML projects are based on supervisedlearning, which is very dependent on good feature selection. But then, Robert, what do you think are some of the challenges applied folks in the supervisedlearning space face when trying to productionize these use cases? That actually brings us to a good point.
Key Takeaways Machine Learning Models are vital for modern technology applications. Types include supervised, unsupervised, and reinforcement learning. Key steps involve problem definition, data preparation, and algorithm selection. Ethical considerations are crucial in developing fair Machine Learning solutions.
Introduced by Claude Shannon in 1948, entropy revolutionised how we measure information and remains central to modern Data Science, including Machine Learning. Lets delve into its mathematical definition and key properties. Lets explore its definition, connection to entropy, and practical applications.
You’ll collect more user actions, giving you lots of smaller pieces to learn from, and a much tighter feedback loop between the human and the model. By definition, you can’t directly control what the process returns. Sometimes the meaning representation will directly address a useful question.
So, here is a list of components in an image labeling guideline: Clear Definitions for Each Label/Class: A good guideline should provide a precise definition of each label or class to be assigned to an image. In this technique, a model is trained on an initial labeled dataset.
This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
Summary: This article compares Artificial Intelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. While AI aims to replicate human intelligence across various domains, ML focuses on learning from data to improve performance.
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. Unsupervised learning: This involves using unlabeled data to identify patterns and relationships within the data. Technology: Includes a range of technologies, including ML and deep learning.
They use self-supervisedlearning algorithms to perform a variety of natural language processing (NLP) tasks in ways that are similar to how humans use language (see Figure 1). Large language models (LLMs) have taken the field of AI by storm.
So domain-specific LLMs can assist newcomers by providing explanations, definitions, and context, reducing the learning curve. Often jargon and other contextual pieces of information don’t translate well when making the move to a new industry. The same can also be said with popular tools.
Currently, most models are trained via supervisedlearning, which relies on well-annotated data from humans to create training examples. Data annotation is especially important when considering the amount of unstructured data that exists in the form of text, images, video, and audio.
Key Terms and Definitions To fully grasp the concepts of dimensionality reduction, it’s essential to understand the key terms and definitions associated with this field. We aim to retain the essential information by reducing dimensions while discarding less relevant details.
Data Analysis When working with data, especially supervisedlearning, it is often a best practice to check data imbalance. If you haven’t coded an image classification network before, the section is definitely for you! Figure 2: Analyzing a few categories from the vegetable image classification dataset.
There are various types of regressions used in data science and machine learning. Figure 1: Types of regression (own graphic) Definition of Simple Linear Regression The dependent variable is continuous. Conclusion This article described regression which is a supervisinglearning approach.
How do you train machine learning algorithms generally for any data set? Then we generalized that for the entire field of supervisedlearning. They’re borderline out of distribution, but they’re definitely errors that shouldn’t be in the dataset. And for any model for binary classification?
How do you train machine learning algorithms generally for any data set? Then we generalized that for the entire field of supervisedlearning. They’re borderline out of distribution, but they’re definitely errors that shouldn’t be in the dataset. And for any model for binary classification?
The model was fine-tuned to reduce false, harmful, or biased output using a combination of supervisedlearning in conjunction to what OpenAI calls Reinforcement Learning with Human Feedback (RLHF), where humans rank potential outputs and a reinforcement learning algorithm rewards the model for generating outputs like those that rank highly.
For instance, something from a factory maybe some uses case where there’s a limited amount of data, then I think the current approach, and especially in the growing field of self-supervisedlearning, is very helpful here. You can actually improve embeddings and train embeddings in a self-supervised way. Any thoughts?
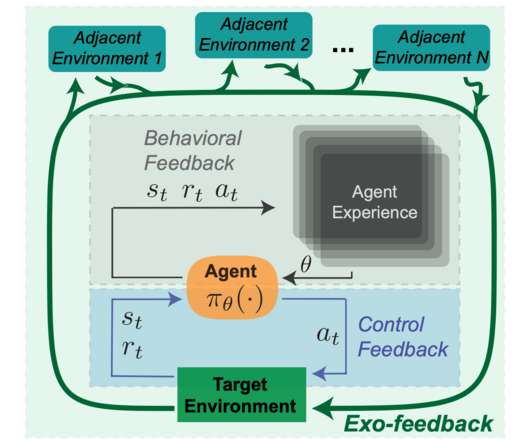
At the same time as the emergence of powerful RL systems in the real world, the public and researchers are expressing an increased appetite for fair, aligned, and safe machine learning systems. Exo-feedback is by definition difficult for a designer to predict.
Complexity in Goal Definition: Requires domain knowledge for accurate goal setting. These agents can be reactive, deliberative, or learning-based, enabling them to perform tasks autonomously, make decisions, and adapt to changing conditions in various applications. How Do AI Agents Learn?
Students learn Maximum Likelihood Estimation, the three M’s of Statistics (Mean, Median, Mode), and critical topics like Central Limit Theorem, Confidence Intervals, Hypothesis Testing, and Linear Regression. The course may be helpful for engineering students who want to learn Statistical methods well.
The downside of overly time-consuming supervisedlearning, however, remains. Classic Methods of Time Series Forecasting Multi-Layer Perceptron (MLP) Univariate models can be used to model univariate time series prediction machine learning problems. In its core, lie gradient-boosted decision trees.
Unsupervised learning has shown a big potential in large language models but high-quality labelled data remains the gold standard for AI systems to be accurate and aligned with human language and understanding. Text labeling has enabled all sorts of frameworks and strategies in machine learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content