This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services.
Drag and drop tools have revolutionized the way we approach machine learning (ML) workflows. Gone are the days of manually coding every step of the process – now, with drag-and-drop interfaces, streamlining your ML pipeline has become more accessible and efficient than ever before. H2O.ai H2O.ai
You will also see a hands-on demo of implementing vector search over the complete Wikipedia dataset using Weaviate. Part 3: Challenges of Industry ML/AI Applications at Scale with Vector Embeddings Scaling AI and ML systems in the modern technological world presents unique and complex challenges.
From an enterprise perspective, this conference will help you learn to optimize business processes, integrate AI into your products, or understand how ML is reshaping industries. Machine Learning & Deep Learning Advances Gain insights into the latest ML models, neural networks, and generative AI applications.
The previous parts of this blog series demonstrated how to build an ML application that takes a YouTube video URL as input, transcribes the video, and distills the content into a concise and coherent executive summary. Before proceeding, you may want to have a look at the resulting demo or the code hosted on Hugging Face U+1F917 Spaces.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale. For example: input = "How is the demo going?" Refer to demo-model-builder-huggingface-llama2.ipynb output = "Comment la démo va-t-elle?"
But again, stick around for a surprise demo at the end. ? This format made for a fast-paced and diverse showcase of ideas and applications in AI and ML. In just 3 minutes, each participant managed to highlight the core of their work, offering insights into the innovative ways in which AI and ML are being applied across various fields.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
With a goal to help data science teams learn about the application of AI and ML, DataRobot shares helpful, educational blogs based on work with the world’s most strategic companies. Data Scientists of Varying Skillsets Learn AI – ML Through Technical Blogs. Watch a demo. See DataRobot in Action. Bureau of Labor Statistics.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
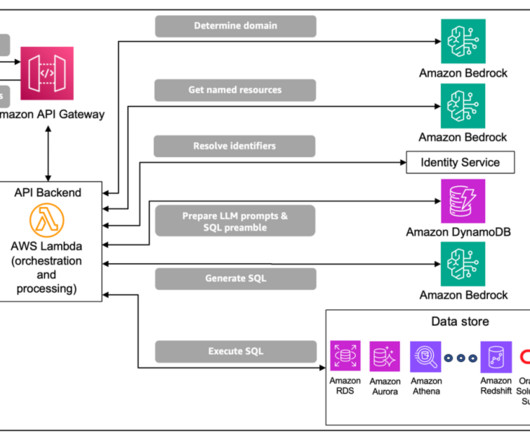
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
Model server overview A model server is a software component that provides a runtime environment for deploying and serving machine learning (ML) models. The primary purpose of a model server is to allow effortless integration and efficient deployment of ML models into production systems. For MMEs, each model.py The full model.py
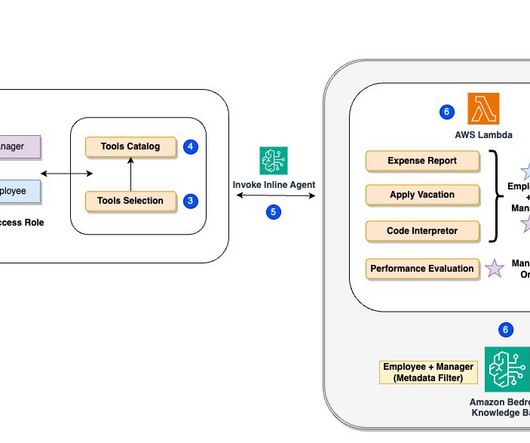
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. To get started, explore our GitHub repo and HR assistant demo application , which demonstrate key implementation patterns and best practices.
The demo code is available in the GitHub repository. About the authors Renuka Kumar is a Senior Engineering Technical Lead at Cisco, where she has architected and led the development of Ciscos Cloud Security BUs AI/ML capabilities in the last 2 years, including launching first-to-market innovations in this space.
The answer to this dilemma is Arize AI, the team leading the charge on ML observability and evaluation in production. In this blog, we will walk you through the highlights of the series that focuses on real-world examples, hands-on demos using Arize Pheonix, and practical techniques to build your AI agents. Lets dive in.
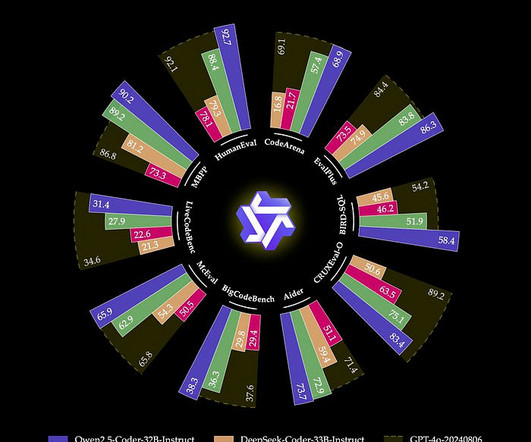
coder:32b The latest series of Code-Specific Qwen models, with significant improvements in code generation, code reasoning, and… ollama.com You can also try out the model on the demo page of Hugging Face: Qwen2.5 Coder Demo – a Hugging Face Space by Qwen Discover amazing ML apps made by the community huggingface.co
Watch this video demo for a step-by-step guide. Once you are ready to import the model, use this step-by-step video demo to help you get started. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. For more information, see Handling ModelNotReadyException.
🧰 The dummy data While Spark is famous for its ability to work with big data, for demo purposes, I have created a small dataset with an obvious duplicate issue. We will use this table to demo and test our custom functions. Do you notice that the two ID fields, ID1 and ID2, do not form a primary key? distinct().count()
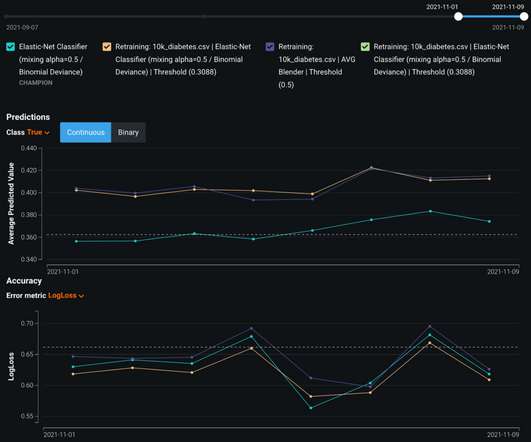
You can now retrain machine learning (ML) models and automate batch prediction workflows with updated datasets in Amazon SageMaker Canvas , thereby making it easier to constantly learn and improve the model performance and drive efficiency. An ML model’s effectiveness depends on the quality and relevance of the data it’s trained on.
The high-level steps are as follows: For our demo , we use a web application UI built using Streamlit. About the authors Praveen Chamarthi brings exceptional expertise to his role as a Senior AI/ML Specialist at Amazon Web Services, with over two decades in the industry. The user enters the credentials and logs in. Brandon Rooks Sr.
Developing web interfaces to interact with a machine learning (ML) model is a tedious task. With Streamlit , developing demo applications for your ML solution is easy. Streamlit is an open-source Python library that makes it easy to create and share web apps for ML and data science. sh setup.sh is modified on disk.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. Eventual and Daft bridge that gap, making ML/AI workloads easy to run alongside traditional tabular workloads. This is more compute than Frontier, the world's largest supercomputer!
Come and be part of ODSC West’s AI Expo & Demo Hall ! Vessl AI: Built for MLOps teams, Vessl AI simplifies ML workflows from model training to deployment, improving efficiency. Meet a few of our top-tier AI partners and learn about the tools and insights to drive your AI initiatives forward.
AWS provides a robust framework for responsible AI development with Amazon SageMaker, a fully managed service that brings together a broad set of tools to build, train, and deploy generative AI and machine learning (ML) models. Our relationship with AWS helps organizations around the globe accelerate the demo-to-production pipeline.
The cloud DLP solution from Gamma AI has the highest data detection accuracy in the market and comes packed with ML-powered data classification profiles. For a free initial consultation call, you can email sales@gammanet.com or click “Request a Demo” on the Gamma website ([link] Go to the Gamma.AI How to use Gamme AI?
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. These models are then pushed to an Amazon Simple Storage Service (Amazon S3) bucket using DVC, a version control tool for ML models. Thirdly, there are improvements to demos and the extension for Spark.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. Under Quick setup settings , for Name , enter a name (for example, demo). Choose Continue.
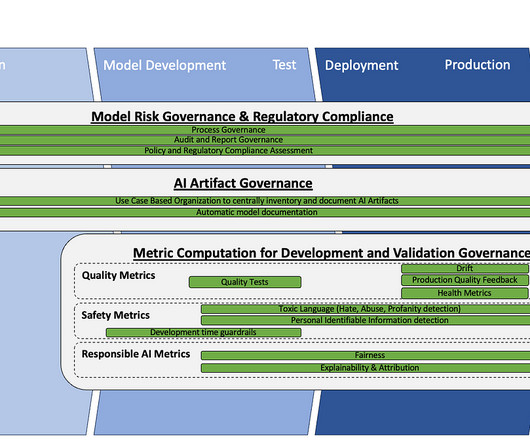
This works for both Predictive ML and LLMs. For Predictive ML, both development and runtime metrics can be monitored for any model including quality metrics, drift, and fairness monitoring. Each of these calculations can be done for any vendor at development time. Details in our documentation here.)
For data science practitioners, productization is key, just like any other AI or ML technology. Successful demos alone just won’t cut it, and they will need to take implementation efforts into consideration from the get-go, and not just as an afterthought. AI/ML Predictions for the New Year appeared first on Iguazio.
Learn more about how Disparate-Impact Remover works and check out an AIF360 code demo. Learn more about how Learning Fair Representations works and check out an AIF360 code demo. Learn more about how Optimized Pre-Processing works and check out an AIF360 code demo. What about other bias-mitigation methods?
AI efforts, whether generative AI or predictive ML, are organized into use cases. This creates a central inventory to document AI and ML efforts, including the ability to assign an overall risk score for each use case. AI Artifact Governance This portion of watsonx.governance is about documentation.
Explore the top 10 machine learning demos and discover cutting-edge techniques that will take your skills to the next level. It has a large and active community of users and developers who can provide support and help. It is open-source, so it is free to use and modify. It is a cloud-based platform, so it can be accessed from anywhere.
– Application layer: This layer emphasizes the potential of FinGPT in the financial industry by showcasing real-world applications and demos. Don’t forget to join our 23k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AI research news, cool AI projects, and more.
Azure ML Model Catalog Within the Azure model catalog , you can effortlessly locate the Llama 2 model developed by Meta. This demo provides a non-technical audience with the opportunity to submit queries and toggle between chat modes, simplifying the experience of interacting with Llama 2’s generative abilities.
IDC 2 predicts that by 2024, 60% of enterprises would have operationalized their ML workflows by using MLOps. The same is true for your ML workflows – you need the ability to navigate change and make strong business decisions. Request a Demo. 1 IDC, MLOps – Where ML Meets DevOps, doc #US48544922, March 2022.
Amazon SageMaker Studio offers a comprehensive set of capabilities for machine learning (ML) practitioners and data scientists. These include a fully managed AI development environment with an integrated development environment (IDE), simplifying the end-to-end ML workflow.
Today, we are excited to unveil three generative AI demos, licensed under MIT-0 license : Amazon Kendra with foundational LLM – Utilizes the deep search capabilities of Amazon Kendra combined with the expansive knowledge of LLMs. Having the right setup in place is the first step towards a seamless deployment of the demos.
Grab one for access to Keynote Talks, Demo Talks, the AI Expo and Demo Hall, and Extra Events. Find Your AI Solutions at the ODSC West AI Expo Learn about the best AI solutions for your organization at the ODSC West AI Expo & Demo Hall during these Demo Theater sessions! Attend in-person or virtually!
Composable ML. This past summer, DataRobot announced the addition of Composable ML to our AI Cloud platform. However, with the advent of Composable ML, I now have access to built-in sentiment analysis tasks in DataRobot to preprocess the lyrics for me. See DataRobot Composable ML in Action. Request a demo.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
In the machine learning (ML) and artificial intelligence (AI) domain, managing, tracking, and visualizing model training processes is a significant challenge due to the scale and complexity of managed data, models, and resources. Use the plugin by installing it with pip install flytekitplugins-neptune. contact-us.
Business challenge Businesses today face numerous challenges in effectively implementing and managing machine learning (ML) initiatives. Customers have built their own ML architectures on bare metal machines using open source solutions such as Kubernetes, Slurm, and others.
TL;DR Using CI/CD workflows to run ML experiments ensures their reproducibility, as all the required information has to be contained under version control. The compute resources offered by GitHub Actions directly are not suitable for larger-scale ML workloads. ML experiments are, by nature, full of uncertainty and surprises.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content