This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While language models in generative AI focus on textual data, vision language models (VLMs) bridge the gap between textual and visual data. Understanding vision language models VLMs combine computer vision (CV) and naturallanguageprocessing (NLP), enabling them to understand and connect visual information with textual data.
AI’s remarkable language capabilities, driven by advancements in NaturalLanguageProcessing (NLP) and Large Language Models (LLMs) like ChatGPT from OpenAI, have contributed to its popularity. In 2023, Artificial Intelligence (AI) is a hot topic, captivating millions of people worldwide.
Use metadata query language to filter output ( $eq , $ne , $in , $nin , $and , and $or ). The example queries in Python demonstrate how you can retrieve a list of records associated with Customer A from the Pinecone database. The response only cites sources that are relevant to the query.
This written tutorial will guide you through the process of building an AI-powered dental assistant in Python, using AssemblyAI for speech-to-text, OpenAI for generating responses, and ElevenLabs for voice synthesis. NaturalLanguageProcessing (NLP): OpenAI's language models generate intelligent, context-aware responses.
Watch this video demo for a step-by-step guide. You can customize the retry behavior using the AWS SDK for Python (Boto3) Config object. Once you are ready to import the model, use this step-by-step video demo to help you get started. The restoration time varies depending on the on-demand fleet size and model size.
It has an official website from which you can access the premium version of Quivr by clicking on the button ‘Try demo.’ You should also have the official, and the latest version of Python preinstalled on your device. Text and multimedia are two common types of unstructured content.
How to save a trained model in Python? Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects. For saving the ML models used as a pickle file, you need to use the Pickle module that already comes with the default Python installation. Now let’s see how we can save our model.
Training AI-Powered Algorithmic Trading with Python Dr. Yves J. Hilpisch | The AI Quant | CEO The Python Quants & The AI Machine, Adjunct Professor of Computational Finance This session will cover the essential Python topics and skills that will enable you to apply AI and Machine Learning (ML) to Algorithmic Trading.
It is used for machine learning, naturallanguageprocessing, and computer vision tasks. It is similar to TensorFlow, but it is designed to be more Pythonic. For example, PyTorch was used by OpenAI to develop its GPT-3 language model. Scikit-learn Scikit-learn is an open-source machine learning library for Python.
Photo by Kunal Shinde on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.09.20 Where are those commonsense reasoning demos? Research Work on methods that address the challenges of low-resource languages. Forge Where are we? What is the state of NLP? So… where are we….
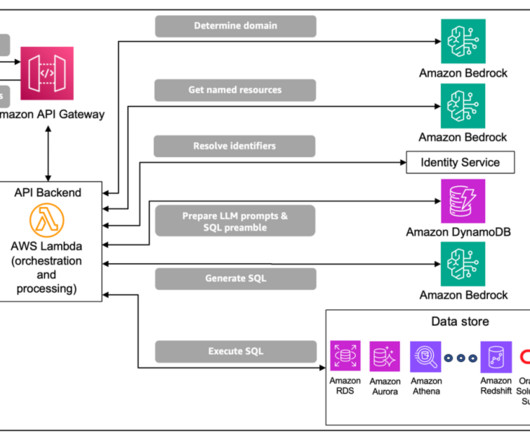
This can be implemented using naturallanguageprocessing (NLP) or LLMs to apply named entity recognition (NER) capabilities to drive the resolution process. This optional step has the most value when there are many named resources and the lookup process is complex.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. client( service_name='bedrock', region_name='us-west-2', ) bedrock_runtime = boto3.client(
Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing. This is widely used in NaturalLanguageProcessing (NLP), where it plays a pivotal role in pre-processing unstructured textual data. The below flow diagram illustrates this process.
An open-source, low-code Python wrapper for easy usage of the Large Language Models such as ChatGPT, AutoGPT, LLaMa, GPT-J, and GPT4All An introduction to “ pychatgpt_gui” — A GUI-based APP for LLM’s with custom-data training and pre-trained inferences. It is an open-source python package. The code below illustrates the same.
Today, we are excited to unveil three generative AI demos, licensed under MIT-0 license : Amazon Kendra with foundational LLM – Utilizes the deep search capabilities of Amazon Kendra combined with the expansive knowledge of LLMs. Having the right setup in place is the first step towards a seamless deployment of the demos. Python 3.6
The DJL is a deep learning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. Our data scientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. For this reason, many DJL users also use it for inference only. With v0.21.0
We use Streamlit for the sample demo application UI. For all the supported parameters, refer to Streaming Python configuration. Because it’s part of the common data formats supported for inference , we can use the default deserializer provided by the SageMaker Python SDK to deserialize the JSON lines data.
That too in a language that is simple and easy for us to comprehend. This is where NaturalLanguageProcessing (NLP) makes its entrance. Naturallanguage — the language that humans use to communicate with each other. Python, Java, C++, C, etc., are all examples of programming languages.
Amazon Comprehend is a natural-languageprocessing (NLP) service that provides pre-trained and custom APIs to derive insights from textual data. For the demo, we use simulated bank statements like the following example. To start the state machine, run the following Python code: import boto3 stepfunctions_client = boto3.client('stepfunctions')
T5 reframes naturallanguageprocessing (NLP) tasks into a unified text-to-text-format, in contrast to BERT -style models that can only output either a class label or a span of the input. medium 2vCPU+4GiB notebook instance with a Python 3 kernel. We use an ml.t3.medium pip install nest-asyncio==1.5.5 --quiet !pip
We also demonstrate how you can engineer prompts for Flan-T5 models to perform various naturallanguageprocessing (NLP) tasks. Task Prompt (template in bold) Model output Summarization Briefly summarize this paragraph: Amazon Comprehend uses naturallanguageprocessing (NLP) to extract insights about the content of documents.
Photo by adrianna geo on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.23.20 A toolkit that allows the developer to dig deep into language models, in addition to dataset visualization. I tend to view LIT as an ML demo on steroids for prototyping. Fury What a week.
Photo by Will Truettner on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 07.26.20 Instead of building a model from… github.com NERtwork Awesome new shell/python script that graphs a network of co-occurring entities from plain text! The demo is for building/training an NER LSTM model.
Currently, published research may be spread across a variety of different publishers, including free and open-source ones like those used in many of this challenge's demos (e.g. He also boasts several years of experience with NaturalLanguageProcessing (NLP). On the server side, we opted for Python.
To explore this possibility, we developed Code as Policies (CaP), a robot-centric formulation of language model-generated programs executed on physical systems. CaP extends our prior work , PaLM-SayCan , by enabling language models to complete even more complex robotic tasks with the full expression of general-purpose Python code.
Watch this video demo for a step-by-step guide. You can customize the retry behavior using the AWS SDK for Python (Boto3) Config object. Once you are ready to import the model, use this step-by-step video demo to help you get started. The restoration time varies depending on the on-demand fleet size and model size.
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. Note that this integration is only available in us-east-1 and us-west-2 , and you will be using us-east-1 for the duration of the demo. Choose Manage.
PyTorch For tasks like computer vision and naturallanguageprocessing, Using the Torch library as its foundation, PyTorch is a free and open-source machine learning framework that comes in handy. Anomalib Anomalib is a Python library that helps users to detect anomalies in time-series data.
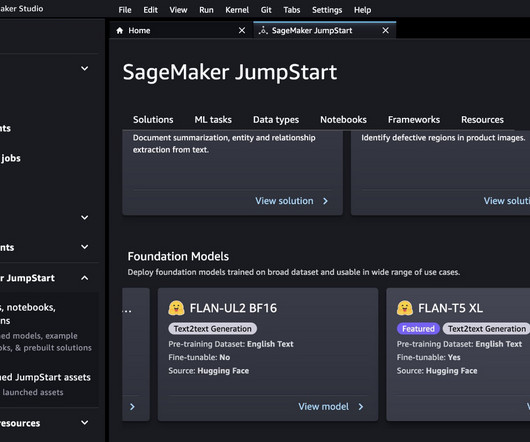
In this post, we provide an overview of how to deploy and run inference with the Stable Diffusion upscaler model in two ways: via JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK. The following examples contain code snippets.
For the purposes of the demo, you will have two different users in Amazon Cognito belonging to two different departments. At a high level, you need to perform the following steps to enable this demo: Set up an S3 bucket data source with the appropriate documents and folder structure. sessionAttributes”.”idtokenjwt” slot name”.”value”.”interpretedValue”
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art naturallanguageprocessing (NLP) model to find useful signals in text. When running this notebook on Studio, you should make sure the Python 3 (PyTorch 1.10 Demo notebook. CPU Optimized) image/kernel is used.
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. It is the latest in the research lab’s lineage of large language models using Generative Pre-trained Transformer (GPT) technology. Like its predecessors, ChatGPT generates text in a variety of styles, for a variety of purposes.
This is a guest post by Wah Loon Keng , the author of spacy-nlp , a client that exposes spaCy ’s NLP text parsing to Node.js (and other languages) via Socket.IO. NaturalLanguageProcessing and other AI technologies promise to let us build applications that offer smarter, more context-aware user experiences.
If you’re in the field of NaturalLanguageProcessing, you’ve probably heard about Hugging Face. Hugging Face is a library that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. Hugging Face Hub is a platform with models, datasets, and demo applications.
Generative language models have proven remarkably skillful at solving logical and analytical naturallanguageprocessing (NLP) tasks. We demonstrate the approach using batch inference on Amazon Bedrock: We access the Amazon Bedrock Python SDK in JupyterLab on an Amazon SageMaker notebook instance. whl | head -1) !pip
Fine-tune FLAN-T5 using a Python notebook Our example notebook shows how to use Jumpstart and SageMaker to programmatically fine-tune and deploy a FLAN T5 XL model. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. It can be run in Studio or locally.
We benchmark the results with a metric used for evaluating summarization tasks in the field of naturallanguageprocessing (NLP) called Recall-Oriented Understudy for Gisting Evaluation (ROUGE). Evaluating LLMs is an undervalued part of the machine learning (ML) pipeline. It is time-consuming but, at the same time, critical.
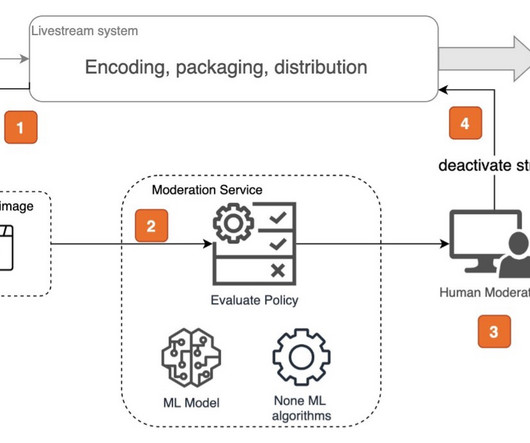
The following code snippet demonstrates how to call the Amazon Rekognition DetectModerationLabel API to moderate images within an AWS Lambda function using the Python Boto3 library: import boto3 # Initialize the Amazon Rekognition client object rekognition = boto3.client('rekognition') The following diagram illustrates this architecture.
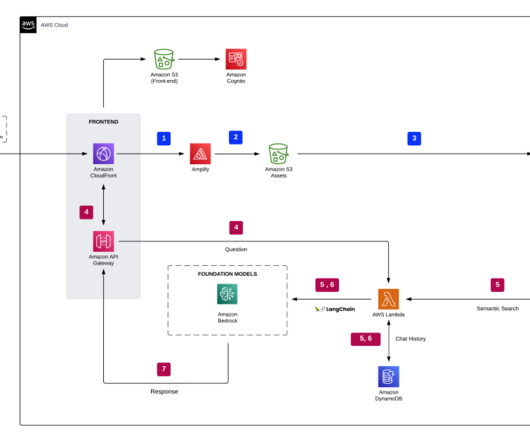
With Knowledge Bases for Amazon Bedrock, you can access detailed information through simple, natural queries. Build a knowledge base for Amazon Bedrock In this section, we demo the process of creating a knowledge base for Amazon Bedrock via the console. For more information, refer to Model access.
Comet allows data scientists to track their machine learning experiments at every stage, from training to production, while Gradio simplifies the creation of interactive model demos and GUIs with just a few lines of Python code. Gradio is an open-source Python library that simplifies the creation of interactive ML interfaces.
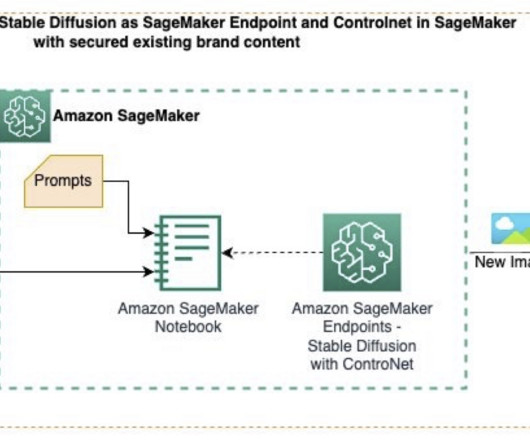
With these techniques, marketing, advertisement, and other creative agencies can use generative AI tools to augment their ad creatives process. To dive deeper into the solution and code shown in this demo, check out the GitHub repo. The following is a snippet from inference.py
The model excels at tasks ranging from naturallanguageprocessing to coding, making it an invaluable resource for researchers, developers, and businesses. model, but the same process can be followed for the Mistral-7B-instruct-v0.3 sets a new standard for user-friendly and powerful AI tools.
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK , and JumpStart’s user interface (UI) in Amazon SageMaker Studio. Furthermore, we run inference on the deployed endpoint, all using the SageMaker Python SDK.
Through multi-round dialogues, we highlight the capabilities of instruction-oriented zero-shot and few-shot vision languageprocessing, emphasizing its versatility and aiming to capture the interest of the broader multimodal community. The demo implementation code is available in the following GitHub repo. box_threshold=0.5,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content