This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To overcome these limitations, we propose a solution that combines RAG with metadata and entity extraction, SQL querying, and LLM agents, as described in the following sections. Typically, these analytical operations are done on structured data, using tools such as pandas or SQL engines.
Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL. But why is SQL, or Structured Query Language , so important to learn? Let’s start with the first clause often learned by new SQL users, the WHERE clause.
Data processing and SQL analytics Analyze, prepare, and integrate data for analytics and AI using Amazon Athena, Amazon EMR, AWS Glue, and Amazon Redshift. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. Under Quick setup settings , for Name , enter a name (for example, demo).
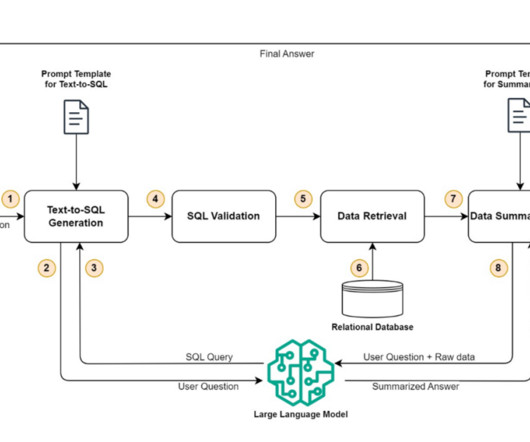
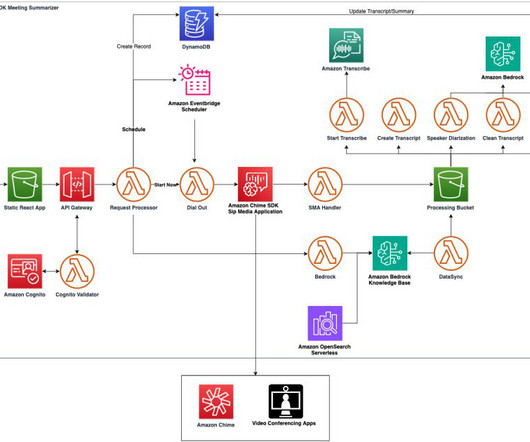
From a broad perspective, the complete solution can be divided into four distinct steps: text-to-SQL generation, SQL validation, data retrieval, and data summarization. A pre-configured prompt template is used to call the LLM and generate a valid SQL query. The following diagram illustrates this workflow.
Basic knowledge of a SQL query editor. A provisioned or serverless Amazon Redshift data warehouse. For this post we’ll use a provisioned Amazon Redshift cluster. A SageMaker domain. A QuickSight account (optional). Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster.
The prompts are managed through Lambda functions to use OpenSearch Service and Anthropic Claude 2 on Amazon Bedrock to search the client’s database and generate an appropriate response to the client’s business analysis, including the response in plain English, the reasoning, and the SQL code.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
They demo the tool and help people in the sales process see if their tool is the right fit. I’ve always been more toward the “end of the stack” That said, SQL and Python. I was a solutions engineer prior, which led into this type of work. Awesome, do you speak at conferences and meetups too?
In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database. Run the Streamlit demo Now that you have the components in place and the invoices processed using Amazon Bedrock, it’s time to deploy the Streamlit application. or python -m streamlit run review-invoice-data.py
Finally, Tuesday is the first day of the AI Expo and Demo Hall , where you can connect with our conference partners and check out the latest developments and research from leading tech companies. This will also be the last day to connect with our partners in the AI Expo and Demo Hall.
For the last Sprint Demos, we featured some exciting updates: Personal Access Token impersonation, auto-disabling Webhooks, new Webhooks payload for Slack, and JupyterLab integration for the Hyper API. You can run your SQL queries and check the results without having to write a complete program around Hyper API. . It will indeed!
Now, as MongoDB is a NoSQL Database, we have to create a Database first (unlike Schema for SQL Databases, although the concept is same), then inside the Database we have to create a collection, in which we can store documents (It is like creating a table inside a Database). 70B Instruct models for this demo.
Topics include python fundamentals, SQL for data science, statistics for machine learning, and more. Deep Learning with Tensorflow 2 and Pytorch Originally recorded as a live training, this session serves as a primer on deep learning theory that will bring the revolutionary machine learning approach to life with hands-on demos.
Confirmed sessions include: An Introduction to Data Wrangling with SQL with Sheamus McGovern, Software Architect, Data Engineer, and AI expert Programming with Data: Python and Pandas with Daniel Gerlanc, Sr. Mini-Bootcamp and VIP Pass holders will have access to four live virtual sessions on data science fundamentals.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Enter a stack name, such as Demo-Redshift. This is the maximum allowed number of domains in each supported Region.
With it, both business and IT teams can start working with events and defining business scenarios without writing code or being an expert in SQL. View the webinar to learn more about unlocking the value of transaction data flowing across your organization.
This Week Sentence Transformers txtai: AI-Powered Search Engine Fine-tuning Custom Datasets Data API Endpoint With SQL It’s LIT ? Data API Endpoint With SQL If you like SQL and you like data, Port 5432 is open… Splitgraph allows users to connect to more than 40K datasets via a PostgreSQL client. ? Broadcaster Stream API Fast.ai
The VizQL Data Service was first demoed at Tableau Conference 2023 and allows users to make programmatic (API) requests for data from published data sources in Tableau. It is essentially a translator of SQL queries that traditionally return numbers and tables into an effortless visual analysis.” What is VizQL Data Service?
Looking forward If you’re interested in learning more about machine learning, Then check out ODSC East 2023 , where there will be a number of sessions as part of the machine & deep learning track that will cover the tools, strategies, platforms, and use cases you need to know to excel in the field.
It exposes new interfaces for development in Python , Scala, or Java to supplement Snowflake’s original SQL interface. SQL is, of course, the lingua franca for data, but there are many applications and development teams that rely heavily on other languages. What’s New with Snowpark? ” Of course! conda create -n snowpark python=3.8
It exposes new interfaces for development in Python , Scala, or Java to supplement Snowflake’s original SQL interface. SQL is, of course, the lingua franca for data, but there are many applications and development teams that rely heavily on other languages. What’s New with Snowpark? ” Of course! conda create -n snowpark python=3.8
If you’re interested in learning more about machine learning, Then check out ODSC East 2023 , where there will be a number of sessions as part of the machine & deep learning track that will cover the tools, strategies, platforms, and use cases you need to know to excel in the field.
Over the last month, we’ve been heavily focused on adding additional support for SQL translations to our SQL Translations tool. Specifically, we’ve been introducing fixes and features for our Microsoft SQL Server to Snowflake translation. This is where the SQL Translation tool can be a massive accelerator for your migration.
Alation BI Bake Off Demo. Alation catalogs and crawls all of your data assets, whether it is in a traditional relational data set (MySQL, Oracle, etc), a SQL on Hadoop system (Presto, SparkSQL,etc), a BI visualization or something in a file system, such as HDFS or AWS S3. Learn more by watching the full demo of Alation’s BI Bake Off.
From there, ChatGPT generates a SQL query which is then executed in the Snowflake Data Cloud , and the results are brought back into the application in a table format. In this case, after the SQL query is executed on Snowflake, it is converted into a Python dataframe, and basic graphic code is executed to generate the image.
IBM has created an intuitive, low code tool designed to empower less technical stakeholders to work with business events and make better decisions, without having to write code or be an expert in SQL. This helps businesses quickly expand into new use cases and derive actionable insights that maximize revenue potential.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
And if you want to see demos of some of this functionality, be sure to join us for the livestream of the Citus 12.0 If you skip one of these steps, performance might be poor due to network overhead, or you might run into distributed SQL limitations. SQL requirement for single node queries Use a single distributed schema per query.
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. This allowed them to focus on SQL-based query optimization to the nth degree. What is Presto? EMA Technical Case Study, sponsored by Ahana.
Going one step deeper, Cortex powers LLM (and traditional ML) functionality that can be called using Snowflake SQL. Copilot outputs SQL queries and provides buttons to add that SQL to your Snowflake worksheet and run the query. We talked a lot about it after Summit 2023, but the demos from Snowday made us even more excited.
With the help of SQL and R, this tool analyzes your data and turns it into pretty interactive dashboards within minutes. You can add time-based and custom filters, write SQL, get charts, and share dashboards with the team. Its analytics can integrate with different SQL databases and different data warehouses. Yellowfin BI.
We’ve been focusing on two key areas: Microsoft SQL Server to Snowflake Data Cloud SQL translations and our new Advisor tool within the phData Toolkit. SQL Translation Updates When customers are looking to migrate between platforms, there’s always a challenge in migrating existing code. Let’s dive in.
Pre-Bootcamp On-Demand Training Before the conference, you’ll have access to on-demand, self-paced training on core skills like Python, SQL, and more from some of our acclaimed instructors. Day 1 will focus on introducing fundamental data science and AI skills.
Snorkel Flow + Databricks Snorkel is further streamlining the machine learning development process for organizations that rely on Databricks with the new Databricks SQL connector built directly into the platform interface. Here’s how it works: Select “Databricks SQL”’ as a data source when creating a new dataset in Snorkel Flow.
Snorkel Flow + Databricks Snorkel is further streamlining the machine learning development process for organizations that rely on Databricks with the new Databricks SQL connector built directly into the platform interface. Here’s how it works: Select “Databricks SQL”’ as a data source when creating a new dataset in Snorkel Flow.
Other companies implement decision rules, but do it by writing their own Python, Java or SQL. Check out the demo on the Decision Intelligence Flows web page or request a live demo personalized just for you. Request a Demo. Go Beyond Predictions, Automate and Scale Your Decisions.
You’ll also have the chance to learn about the tradeoffs of building AI from scratch or buying it from a third party at the AI Expo and Demo Hall, where Microsoft, neo4j, HPCC, and many more will be showcasing their products and services.
SQL Databases might sound scary, but honestly, they’re not all that bad. And much of that is thanks to SQL (Structured Query Language). Believe it or not, SQL is about to celebrate its fiftieth birthday next year as it was first developed in 1974 as part of IBM’s System R Project. Learning is learning.
In this demo, an outbound call is made using the CreateSipMediaApplicationCall API. In this demo, the prompts are designed using Anthropic Claude Sonnet as the LLM. Output: Adam: Have you experienced SQL injections in the past? Because this demo supports multiple meeting types, the invitation must be parsed. Court: Yes.
Snowflake Cortex has removed all that hassle by self-hosting the models and allowing you access to the models using a simple Python or SQL command. Our first video will walk you through the data set we have mocked up for this demo. Closing In this demo, we learned how to organize CRM data in Snowflake.
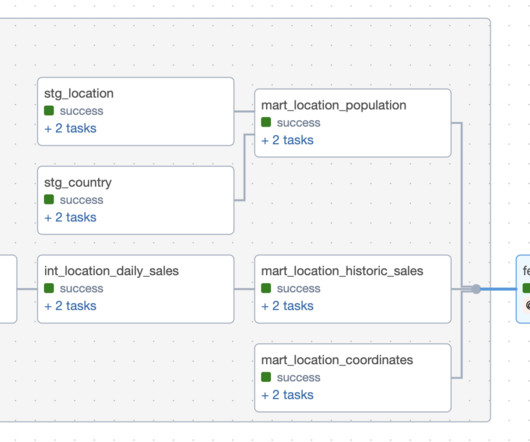
Setup The demo is available in this repo. Using dbt to transform data into features allows engineers to take advantage of the expressibility of SQL without worrying about data lineage. For this demo, location_id is the entity we have features for; this is the column we will tell our feature store to identify as the entity.
I highly recommend anyone coming from a Machine Learning or Deep Learning modeling background who wants to learn about deploying models (MLOps) on a cloud platform to take this exam or an equivalent; the exam also includes topics on SQL data ingestion with Azure and Databricks, which is also a very important skill to have in Data Science.
The Modern Data Stack: Apache Spark, Google Bigquery, Oracle Database, Microsoft SQL Server, Snowflake The modern data stack continues to have a big impact, and data analytics roles are no exception. SQL excels with big data and statistics, making it important in order to query databases.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content