This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
14, 2025InFlux Technologies (Flux), a decentralized technology company specializing in cloud infrastructure, AI and decentralized cloud computing services, has launched FluxINTEL, an advanced document intelligence engine designed to help businesses analyze critical data with greater speed and insight. CAMBRIDGE, UK Feb.
Current text embedding models, like BERT, are limited to processing only 512 tokens at a time, which hinders their effectiveness with long documents. This limitation often results in loss of context and nuanced understanding.
Introduction LlamaParse is a document parsing library developed by Llama Index to efficiently and effectively parse documents such as PDFs, PPTs, etc. The nature of […] The post Simplifying Document Parsing: Extracting Embedded Objects with LlamaParse appeared first on Analytics Vidhya.
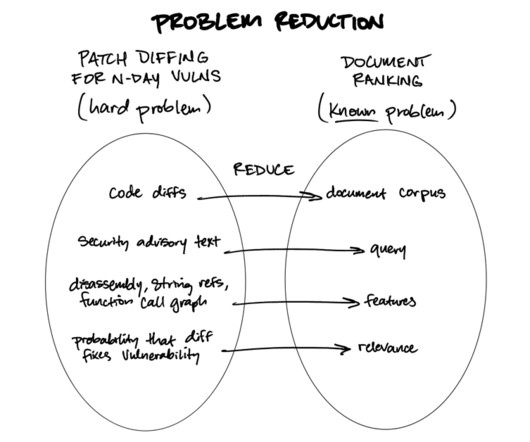
There are two claims I’d like to make: LLMs can be used effectively1 for listwise document ranking. Some complex problems can (surprisingly) be solved by transforming them into document ranking problems.
Documents are the backbone of enterprise operations, but they are also a common source of inefficiency. From buried insights to manual handoffs, document-based workflows can quietly stall decision-making and drain resources. 🛣️ Strategic Roadmapping: Build and execute a realistic AI implementation plan.
We recently announced our AI-generated documentation feature, which uses large language models (LLMs) to automatically generate documentation for tables and columns in Unity.
Digital documents have long presented a dual challenge for both human readers and automated systems: preserving rich structural nuances while converting content into machine-processable formats. appeared first on Analytics Vidhya.
We introduce SmolDocling, an ultra-compact vision-language model targeting end-to-end document conversion. Our model comprehensively processes entire pages by generating DocTags, a new universal markup format that captures all page elements in their full context with location.
This is where the term frequency-inverse document frequency (TF-IDF) technique in Natural Language Processing (NLP) comes into play. Introduction Understanding the significance of a word in a text is crucial for analyzing and interpreting large volumes of data. appeared first on Analytics Vidhya.
models include: A new vision language model (VLM) for document understanding tasks that IBM said demonstrates performance that matches or exceeds that of significantly larger models IBM (NYSE: IBM) today announced additions to its Granite portfolio of large language models intended to deliver small, efficient enterprise AI.
A large portion of that information is found in text narratives stored in various document formats such as PDFs, Word files, and HTML pages. Some information is also stored in tables (such as price or product specification tables) embedded in those same document types, CSVs, or spreadsheets.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
Imagine trying to navigate through hundreds of pages in a dense document filled with tables, charts, and paragraphs. Finding a specific figure or analyzing a trend would be challenging enough for a human; now imagine building a system to do it.
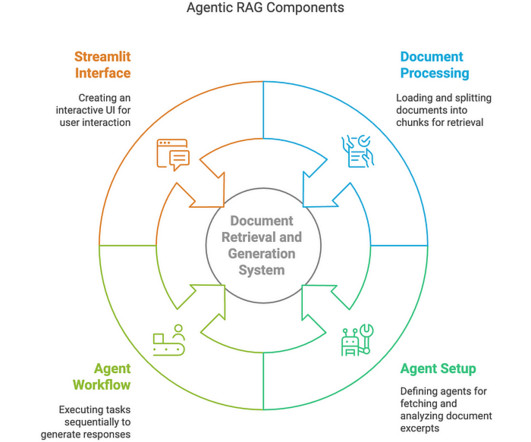
In my previous blog, I explored building a Retrieval-Augmented Generation (RAG) chatbot using DeepSeek and Ollama for privacy-focused document interactions on a local machine here. Image generated using napkin.ai Now, Im elevating that concept with an Agentic RAG approach powered by CrewAI.
Handling documents is no longer just about opening files in your AI projects, its about transforming chaos into clarity. Retrieving structured content from these documents has become a big task today. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size.
Victims choose one: Documented loss payment, up to $10,000. Cash fund payment, prorated with no documentation. Documented loss payment This option reimburses verifiable outofpocket expenses connected to the breach, capped at $10,000 per person. Select Documented Loss or Cash Fund. Choose your payment type.
Retrieval-Augmented Generation, or RAG, has been hailed as a way to make large language models more reliable by grounding their answers in real documents. Even the safest models, paired with safe documents, became noticeably more dangerous when using RAG. Adding more retrieved documents only worsened the problem.
Have you ever been curious about what powers some of the best Search Applications such as Elasticsearch and Solr across use cases such e-commerce and several other document retrieval systems that are highly performant? Apache Lucene is a powerful search library in Java and performs super-fast searches on large volumes of data.
It is one thing to detect text on images on documents and another thing when the text is in an image on a person’s T-shirt. Scene text recognition (STR) continues challenging researchers due to the diversity of text appearances in natural environments.
RAG combines the power of document retrieval with the […] The post Top 13 Advanced RAG Techniques for Your Next Project appeared first on Analytics Vidhya. And how do we keep it from confidently spitting out incorrect facts? These are the kinds of challenges that modern AI systems face, especially those built using RAG.
The solution ensures that AI models are developed using secure, compliant, and well-documented data. Alation Inc., the data intelligence company, launched its AI Governance solution to help organizations realize value from their data and AI initiatives.
Document Summarization LLaMA 3.1 Also learn about AI-powered document search Language Translation Services Translation services can use Llama 3.1 to translate complex legal documents, ensuring that the translated text maintains its original meaning and legal accuracy. For instance, a healthcare provider can use a LLaMA 3.1-powered
For years, businesses, governments, and researchers have struggled with a persistent problem: How to extract usable data from Portable Document Format (PDF) files.
Imagine an AI that can write poetry, draft legal documents, or summarize complex research papersbut how do we truly measure its effectiveness? As Large Language Models (LLMs) blur the lines between human and machine-generated content, the quest for reliable evaluation metrics has become more critical than ever.
Introduction Microsoft Research has introduced a groundbreaking Document AI model called Universal Document Processing (UDOP), which represents a significant leap in AI capabilities.
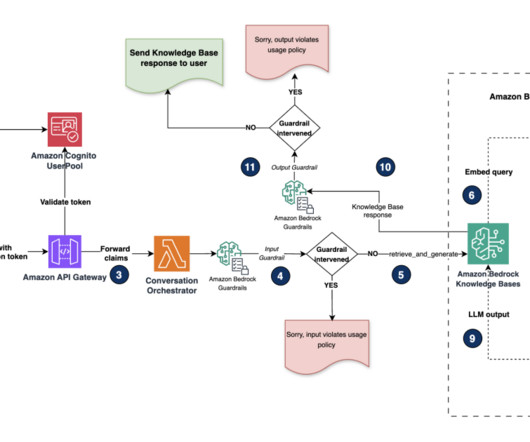
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
This process is typically facilitated by document loaders, which provide a “load” method for accessing and loading documents into the memory. This involves splitting lengthy documents into smaller chunks that are compatible with the model and produce accurate and clear results.
They can act as a signature for the printer that law enforcement uses as document forensic evidence (like in. The layout of the dots are different between printer brands and some dont leave any at all. Information like serial number and sometime the print time is encoded in these dots.
This new Audio Overview feature can turn documents, slides, charts and more into engaging two-party discussions with one click. Here is a an example of a wild new experimental feature from Google called NotebookLM. Two AI hosts start up a lively “deep dive” discussion based on your sources.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
Evaluation ensures the RAG pipeline retrieves relevant documents, generates […] The post A Guide to Evaluate RAG Pipelines with LlamaIndex and TRULens appeared first on Analytics Vidhya. Over the past few months, I’ve fine-tuned my RAG pipeline and learned that effective evaluation and continuous improvement are crucial.
Over the years, organizations have amassed a vast amount of unstructured text data—documents, reports, and emails—but extracting meaningful insights has remained a challenge.
The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. These languages might not be supported out of the box by existing document extraction software.
RAG workflow: Converting data to actionable knowledge RAG consists of two major steps: Ingestion Preprocessing unstructured data, which includes converting the data into text documents and splitting the documents into chunks. Document chunks are then encoded with an embedding model to convert them to document embeddings.
It combines document processing and web search integration to simplify information retrieval and analysis. With so much happening in the Generative AI space, the need for tools that can efficiently process and retrieve information has never been greater.
Chat with Multiple Documents using Gemini LLM is the project use case on which we will build this RAG pipeline. Introduction Retriever is the most important part of the RAG(Retrieval Augmented Generation) pipeline. In this article, you will implement a custom retriever combining Keyword and Vector search retriever using LlamaIndex.
The data is converted into a simple document format that is easy for LlamaIndex to process. Our example code will illustrate the development of a PDF Q&A chatbot that incorporates the OpenAI language model, VectorStoreIndex for document indexing and Streamlit for user interface design.
For example, imagine a consulting firm that manages documentation for multiple healthcare providerseach customers sensitive patient records and operational documents must remain strictly separated. Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
We have implemented a simple RAG pipeline using them to generate responses to user’s questions on ingested documents. Introduction In the previous article, we experimented with Cohere’s Command-R model and Rerank model to generate responses and rerank doc sources.
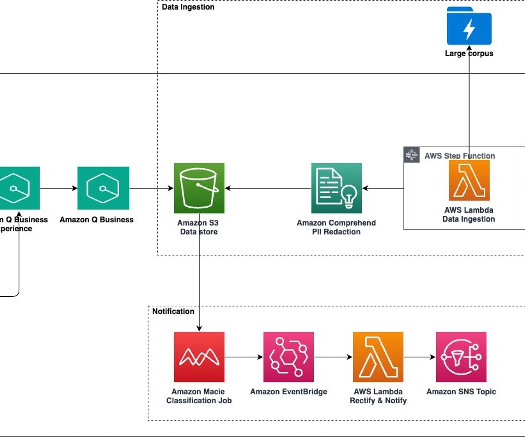
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
This post is divided into five parts: Understanding the RAG architecture Building the Document Indexing System Implementing the Retrieval System Implementing the Generator Building the Complete RAG System An RAG system consists of two main components: Retriever: Responsible for finding relevant documents or passages from a knowledge base given (..)
Get a group of primary care physicians together, and there’s a pretty good chance they will start talking about the potential of AI scribes to reduce documentation burden and improve the clinician-patient office interaction.
Models like Sentence Transformers map words, sentences, or documents into high-dimensional vectors. To find relevant text, you compare vectors using metrics like cosine similarity, retrieving documents whose embeddings are closest to the query embedding. It scores documents based on: 1. My workbook is here: [link] 5.2
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content