This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
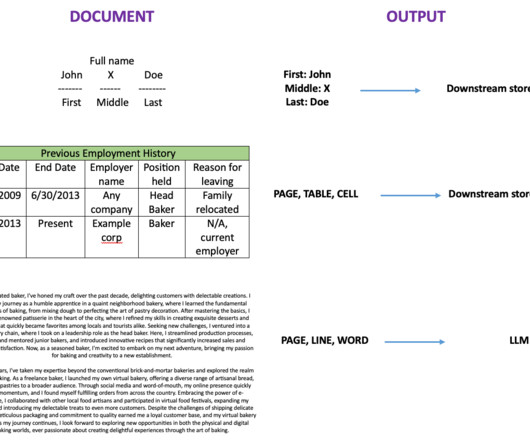
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
Data classification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. FMs are transforming the way you can solve traditionally complex document processing workloads.
It pitted established male EDA experts against two young female Google computer scientists, and the underlying argument had already led to the firing of one Google researcher. But that’s increasingly the case as EDA vendors such as Cadence and Synopsys go all in on AI-assisted chip design.)
Exploratory Data Analysis (EDA) With clean data in hand, the next step is Exploratory Data Analysis (EDA). Techniques for EDA Descriptive Statistics: Start by calculating average shot distance, conversion rates, and shot success inside vs. outside the penalty area. Do not be afraid to dive deep and explore other techniques.
Becoming a real-time enterprise Businesses often go on a journey that traverses several stages of maturity when they establish an EDA. Event Endpoint Management produces valid AsyncAPI documents based on event schemas or sample messages. It provides a catalog for publishing event interfaces for others to discover.
ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. These tools will help make your initial data exploration process easy.
All you need to do is import them to where they are needed, like below - my-project/ - EDA-demo.ipynb - spark_utils.py # then in EDA-demo.ipynbimport spark_utils as sut I plan to share these helpful pySpark functions in a series of articles. Let’s get started. 🤠 🔗 All code and config are available on GitHub.
Since closed competitions do not offer automatic scoring of predictions and models, this option works best when you have an assignment idea in need of cleaned and well-documented data. On request, we can make a custom leaderboard just for your class or for different sections of your class.
Not Documenting Your Analysis Documentation is crucial to ensure others can understand your analysis and replicate your results. Your analysis may be difficult to understand without proper documentation, and others may have difficulty using your work. Hence, a data scientist needs to have a strong business acumen.
Event-driven architecture (EDA) has become more crucial for organizations that want to strengthen their competitive advantage through real-time data processing and responsiveness. and EEM 11.2), you can now generate and import a new AsyncAPI document from a configured event endpoint management instance into API Connect in a single step.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
And also in my work, have to detect certain values in various formats in very specific documents, in German. And annotations would be an effective way for exploratory data analysis (EDA) , so I recommend you to immediately start annotating about 10 random samples at any rate. “Shut up and annotate!”
Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos). Exploring the Data (Exploratory Data Analysis – EDA) Digging into the cleaned data to understand its basic characteristics, find patterns, identify trends, and visualize relationships.
In order to accomplish this, we will perform some EDA on the Disneyland dataset, and then we will view the visualization on the Comet experimentation website or platform. Principles of MLOps — by Tioluwani Oyedele Machine Learning Operations (MLOps) are the aspects of ML that deal with the creation and advancement of these models.
It allows you to create and share live code, equations, visualisations, and narrative text documents. Perform exploratory Data Analysis (EDA) using Pandas and visualise your findings with Matplotlib or Seaborn. You can create a new environment for your Data Science projects, ensuring that dependencies do not conflict.
Data Extraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. Data Extraction, Preprocessing & EDA : Extract & Pre-process the data using Python and perform basic Exploratory Data Analysis.
It leads to gaps in communicating the requirements, which are neither understood well nor documented properly. EDA, as it is popularly called, is the pivotal phase of the project where discoveries are made. They use Jira for sprint tracking, AHA for product management visibility, and confluence for project documentation.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Exploratory Data Analysis (EDA) EDA is a crucial preliminary step in understanding the characteristics of the dataset. Feature Engineering : Creating or transforming new features to enhance model performance.
EDA, imputation, encoding, scaling, extraction, outlier handling, and cross-validation ensure robust models. Example: Using techniques like TF-IDF (Term Frequency-Inverse Document Frequency) to convert text data into features suitable for Machine Learning models. Steps of Feature Engineering 1.
Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. A typical SDLC has following stages: Stage1: Planning and requirement analysis, defining Requirements Gather requirement from end customer. Then software development phases are planned to deliver the software.
Documenting Objectives: Create a comprehensive document outlining the project scope, goals, and success criteria to ensure all parties are aligned. Exploratory Data Analysis (EDA): Conduct EDA to identify trends, seasonal patterns, and correlations within the dataset. accuracy, precision).
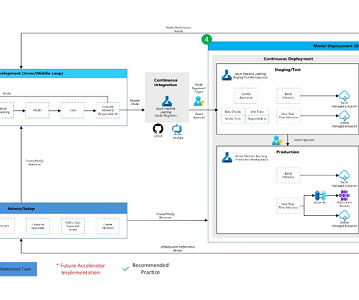
A typical workflow is illustrated here from data ingestion, EDA (Exploratory Data Analysis), experimentation, model development and evaluation, to the registration of a candidate model for production. Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow.
Exploratory Data Analysis (EDA): Analysing and visualising data to discover patterns, identify anomalies, and test hypotheses. J Jupyter Notebook: An open-source web application that allows users to create and share documents containing live code, equations, visualisations, and narrative text.
It is also essential to evaluate the quality of the dataset by conducting exploratory data analysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text. Help and Documentation: The UI should provide clear documentation and help options to assist users in navigating and using the LLMs.
Exploratory data analysis The purpose of having an EDA layer is to find out any obvious error or outlier in the data. Play with this project live For more: See the full model registry overview in the documentation Selecting the best evaluation metrics Evaluation Metrics help us to decide the performance of a version of the algorithm.
I’ve worked in the data analytics space for 15+ years but did not have prior knowledge of medical documents or the medical industry. For each query, an embeddings query identifies the list of best matching documents. Building on the previous point on study design, not all documents are of equal value.
In a real-life scenario you can expect to do more EDA, but for the sake of simplicity we’ll do just enough to get a sense of the process. We first get a snapshot of our data by visually inspecting it and also performing minimal Exploratory Data Analysis just to make this article easier to follow through.
It is a crucial component of the Exploration Data Analysis (EDA) stage, which is typically the first and most critical step in any data project. Unstructured data can include text documents, images, audio recordings, video files, social media posts, emails, and other forms of data that do not naturally fit into a tabular structure.
Exploratory data analysis (EDA) is a critical component of data science that allows analysts to delve into datasets to unearth the underlying patterns and relationships within. EDA serves as a bridge between raw data and actionable insights, making it essential in any data-driven project. What is exploratory data analysis (EDA)?
A streamlined process should include steps to ensure that events are promptly detected, prioritized, acted upon, and documented for future reference and compliance purposes, enabling efficient operational event management at scale. It contains the latest AWS documentation on selected topics.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content