This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
Correcting these issues ensures your analysis is based on clean, reliable data. ExploratoryDataAnalysis (EDA) With clean data in hand, the next step is ExploratoryDataAnalysis (EDA). Do not be afraid to dive deep and explore other techniques.
There are also plenty of data visualization libraries available that can handle exploration like Plotly, matplotlib, D3, Apache ECharts, Bokeh, etc. In this article, we’re going to cover 11 data exploration tools that are specifically designed for exploration and analysis. Output is a fully self-contained HTML application.
Ignoring the business context can lead to analysis irrelevant to the organization’s needs. Hence, a data scientist needs to have a strong business acumen. Not Documenting Your AnalysisDocumentation is crucial to ensure others can understand your analysis and replicate your results.
You can create a new environment for your Data Science projects, ensuring that dependencies do not conflict. Jupyter Notebook is another vital tool for Data Science. It allows you to create and share live code, equations, visualisations, and narrative text documents.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites). Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos).
Data Extraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. Data storage : Store the data in a Snowflake data warehouse by creating a data pipe between AWS and Snowflake.
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through ExploratoryDataAnalysis , imputation, and outlier handling, robust models are crafted. Text feature extraction Objective: Transforming textual data into numerical representations.
At the same time such plant data have very complicated structures and hard to label. And also in my work, have to detect certain values in various formats in very specific documents, in German. Such data are far from general datasets, and even labeling is hard in that case. “Shut up and annotate!”
A typical SDLC has following stages: Stage1: Planning and requirement analysis, defining Requirements Gather requirement from end customer. Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. New developers should learn basic concepts (e.g.
Documenting Objectives: Create a comprehensive document outlining the project scope, goals, and success criteria to ensure all parties are aligned. Making Data Stationary: Many forecasting models assume stationarity. accuracy, precision). Visualization tools can help in understanding these aspects better.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
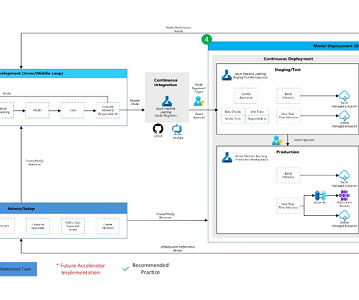
Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow. A typical workflow is illustrated here from data ingestion, EDA (ExploratoryDataAnalysis), experimentation, model development and evaluation, to the registration of a candidate model for production.
Deep Learning : A subset of Machine Learning that uses Artificial Neural Networks with multiple hidden layers to learn from complex, high-dimensional data. ExploratoryDataAnalysis (EDA): Analysing and visualising data to discover patterns, identify anomalies, and test hypotheses.
As an example for catalogue data, it’s important to check if the set of mandatory fields like product title, primary image, nutritional values, etc. are present in the data. So, we need to build a verification layer that runs based on a set of rules to verify and validate data before preparing it for model training.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratorydataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
We first get a snapshot of our data by visually inspecting it and also performing minimal ExploratoryDataAnalysis just to make this article easier to follow through. In a real-life scenario you can expect to do more EDA, but for the sake of simplicity we’ll do just enough to get a sense of the process.
The term “data visualization” refers to the visual representation of data using tables, charts, graphs, maps, and other aids to analyze and interpret information. It is a crucial component of the Exploration DataAnalysis (EDA) stage, which is typically the first and most critical step in any data project.
Exploratorydataanalysis (EDA) is a critical component of data science that allows analysts to delve into datasets to unearth the underlying patterns and relationships within. EDA serves as a bridge between raw data and actionable insights, making it essential in any data-driven project.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content