This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
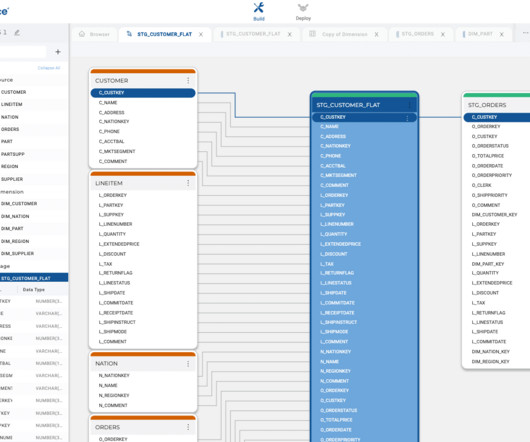
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. Thus, we use an Extract-Transform-Load (ETL) process to ingest the data.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Create and load sample data In this post, we use two sample datasets: a total sales dataset CSV file and a sales target document in PDF format. Choose Next.
This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. Documentation and Disaster Recovery Made Easy Data is the lifeblood of any organization, and losing it can be catastrophic. So why using IaC for Cloud Data Infrastructures?
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like data warehouses. What is ETL? What are ETL Tools?
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud data warehouse like Snowflake. Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code.
Summary: Choosing the right ETL tool is crucial for seamless data integration. At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. What is ETL?
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. Room for improvement!
This tool is designed to connect various data sources, enterprise applications and perform analytics and ETL processes. This ETL integration software allows you to build integrations anytime and anywhere without requiring any coding. Moreover, it allows you to explore the data in SQL and view it in any analytics tool efficiently.
Extraction, Transform, Load (ETL). Redshift is the product for data warehousing, and Athena provides SQL data analytics. It has useful features, such as an in-browser SQL editor for queries and data analysis, various data connectors for easy data ingestion, and automated data prepossessing and ingestion. Master data management.
Fivetran’s automated data movement platform simplifies the ETL (extract, transform, load) process by automating most of the time-consuming tasks of ETL that data engineers would typically do. For more information and examples of the MAR calculation, see the official documentation here.
To learn more, see the documentation. Using Amazon Redshift ML for anomaly detection Amazon Redshift ML makes it easy to create, train, and apply machine learning models using familiar SQL commands in Amazon Redshift data warehouses. To learn more, see the documentation. To learn more, see the documentation.
With numerous approaches and patterns to consider, items and processes to document, target states to plan and architect, all while keeping your current day-to-day processes and business decisions operating smoothly—we understand that migrating an entire data platform is no small task. SQL Server Agent jobs).
Putting the T for Transformation in ELT (ETL) is essential to any data pipeline. They let you create virtual tables from the results of an SQL query. Stored Procedures In any data warehousing solution, stored procedures encapsulate SQL logic into repeatable routines, but Snowflake has some tricks up its sleeve.
SmartSuggestions — In Compose, Alation’s SQL editor, AI-powered suggestions actively show query writers relevant data to use as they query. The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. for the popular database SQL Server. Open Data Quality Initiative.
Here are steps you can follow to pursue a career as a BI Developer: Acquire a solid foundation in data and analytics: Start by building a strong understanding of data concepts, relational databases, SQL (Structured Query Language), and data modeling.
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your data pipelines in a clean and efficient way. Macros can be called in models and then generated into additional SQL snippets or even the entire SQL code.
Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks. Additional Resources For those looking to dive deeper, we recommend exploring the official documentation and tutorials for each tool: Airflow , Feast , dbt , MLflow ) and Amazon ECS.
References : Links to internal or external documentation with background information or specific information used within the analysis presented in the notebook. You could link this section to any other piece of documentation. documentation. In those cases, most of the data exploration and wrangling will be done through SQL.
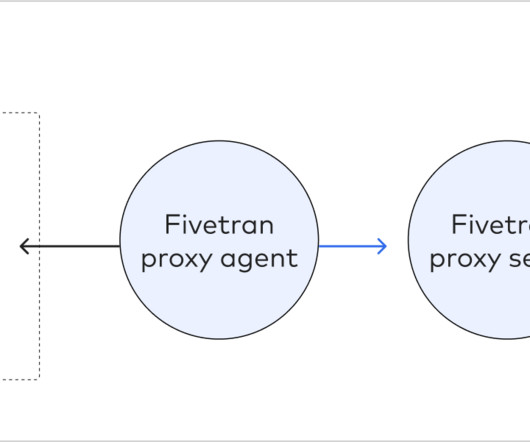
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
Some of the databases supported by Fivetran are: Snowflake Data Cloud (BETA) MySQL PostgreSQL SAP ERP SQL Server Oracle In this blog, we will review how to pull Data from on-premise Systems using Fivetran to a specific target or destination. You can find more information about them in their official documentation.
In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. The following diagram illustrates the architecture and workflow of the proposed solution.
Document Hierarchy Structures Maintain thorough documentation of hierarchy designs, including definitions, relationships, and data sources. This documentation is invaluable for future reference and modifications. Simplify hierarchies where possible and provide clear documentation to help users understand the structure.
While traditional methods of tracking data lineage often involve manual documentation and complex processes, the Snowflake Data Cloud offers a powerful and streamlined solution. Traditional methods for tracking data lineage typically involve manual documentation and reliance on stakeholders’ knowledge.
Reverse ETL tools. The modern data stack is also the consequence of a shift in analysis workflow, fromextract, transform, load (ETL) to extract, load, transform (ELT). A Note on the Shift from ETL to ELT. In the past, data movement was defined by ETL: extract, transform, and load. Extract, load, Transform (ELT) tools.
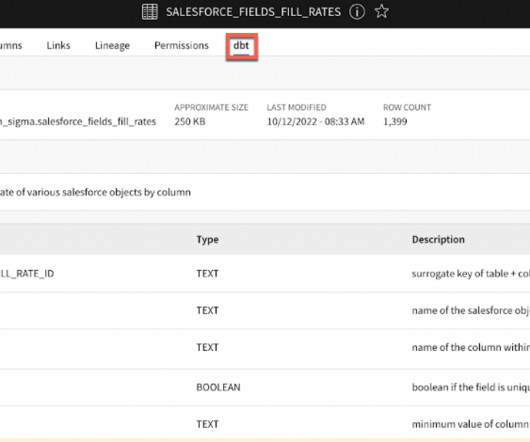
This data transformation tool enables data analysts and engineers to transform, test and document data in the cloud data warehouse. We document these custom models in Alation Data Catalog and publish common queries that other teams can use for operational use cases or reporting needs. How does this help the end user?
Apache Airflow Airflow is an open-source ETL software that is very useful when paired with Snowflake. dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation.
documents and images). This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a data warehouse or data lake. Data can be structured (e.g., databases), semi-structured (e.g.,
Using SQL-centric transformations to model data to be deployed. dbt is also great for data lineage and documentation to empower business analysts to make informed decisions on their data. The focus is on SQL, which is easier to learn but can still prove to be a barrier. It is a compiler and a runner.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. Views Views in GCP BigQuery are virtual tables defined by SQL query that can display the results of a query or be used as the base for other queries.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
They sought documentation to help them locate the source of the data from the warehouse. The developers spent time looking for a tool that could scan all the SQL code and Microsoft SSIS packages because that was the ETL tool being used.
ThoughtSpot is a cloud-based AI-powered analytics platform that uses natural language processing (NLP) or natural language query (NLQ) to quickly query results and generate visualizations without the user needing to know any SQL or table relations. Suppose your business requires more robust capabilities across your technology stack.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. For instance, if the collected data was a text document in the form of a PDF, the data preprocessing—or preparation stage —can extract tables from this document.
Metadata Management can be performed manually by creating spreadsheets and documents notating information about the various datasets. There are tools designed specifically to analyze your data lake files, determine the schema, and allow for SQL statements to be run directly off this data.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. With multiple families in plan, the first release is the Slate family of models, which represent an encoder-only architecture.
Notebooks like Jupyter have also emerged as essential tools by combining documentation, code execution, and visualization in a single interactive interface. Other notebooks like Apache Zeppelin provide similar document-coding capabilities across multiple languages.
Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. It’s not a widely known programming language like Java, Python, or SQL. ECL sounds compelling, but it is a new programming language and has fewer users than languages like Python or SQL.
Document and Communicate Maintain thorough documentation of fact table designs, including definitions, calculations, and relationships. ETL Tools Informatica, Talend, and Apache Airflow enable the extraction of data from source systems, transformation into the desired format, and loading into the dimensional model.
Thankfully there are open-source projects that don’t make you parse SQL into grammars yourself (ain’t nobody got time for that!), SQL Linting saves tons of time and ensures your team is looking for deeper logical issues in the PR instead of basic naming and formatting mistakes. such as SQLFluff. What is a Pattern?
This also means that it comes with a large community and comprehensive documentation. Thanks to its various operators, it is integrated with Python, Spark, Bash, SQL, and more. Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines.
This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Business-Focused Operation Model: Teams can shed countless hours of managing long-running and complex ETL pipelines that do not scale.
Tips When Considering Streamsets Data Collector: As a Snowflake partner, Streamsets includes very intricate documentation on using Data Collector with Snowflake, including this book you can read here. Data Collector also offers replication and Change Data Capture (CDC) to be able to accurately and efficiently get your data into Snowflake.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content