This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Linear regression is widely used in numerous fields such as economics, finance, social sciences, engineering, and natural sciences for tasks such as prediction, trend analysis, and hypothesistesting. It forms the basis for more multifaceted regression techniques and is a fundamental concept in both statistics and machine learning.
We apply the Bonferroni correction to account for multiple hypothesistesting. Since new design biases could be introduced in this process, we recommend following the practice of documenting the demographics of annotators to record a dataset’s positionality. Example Annotation.
It provides functions for descriptive statistics, hypothesistesting, regression analysis, time series analysis, survival analysis, and more. These packages allow for text preprocessing, sentiment analysis, topic modeling, and document classification.
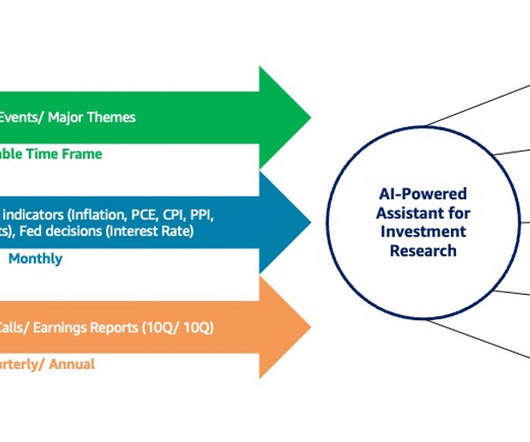
Through thorough research, analysts come up with a hypothesis, test the hypothesis with data, and understand the effect before portfolio managers make decisions on investments as well as mitigate risks associated with their investments. Runtime processing – Embed user queries into vectors.
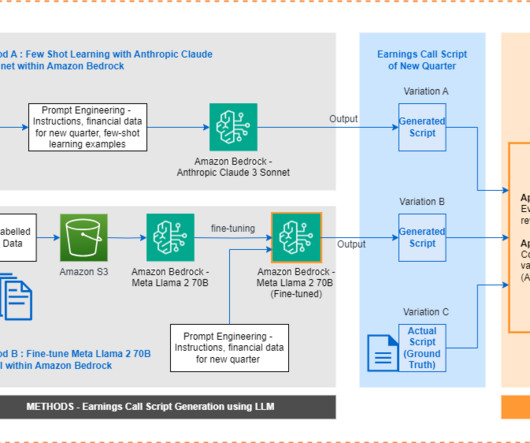
2) The fine-tuning process generally takes longer compared to few-shot prompt engineering based on the same documents. (3) 4) If a new document is added, the whole fine-tuned model needs to be updated by going through the same fine-tuning process. (1)
As 2023 dawns and 2024 begins, future prospective business applications, bi-weekly data science intensive explorations, and hypothesistesting can be found through Ocean Data Challenges. We look forward to seeing how creative and innovative you can be in this interactive research and testing.
Statistics Understand descriptive statistics (mean, median, mode) and inferential statistics (hypothesistesting, confidence intervals). It allows you to create and share live code, equations, visualisations, and narrative text documents. These concepts help you analyse and interpret data effectively.
HypothesisTesting : Statistical Models help test hypotheses by analysing relationships between variables. These models help in hypothesistesting and determining the relationships between variables. Bayesian models and hypothesistests (like t-tests or chi-square tests) are examples of inferential models.
Concepts such as probability distributions, hypothesistesting , and Bayesian inference enable ML engineers to interpret results, quantify uncertainty, and improve model predictions. Documentation Best Practices Proper documentation of ML models, experiments, and workflows is vital for reproducibility and collaboration.
HypothesisTesting and its Ties to Machine Learning Machine learning can easily become a tool for p-hacking, where we torture the data-finding patterns that are coincidental rather than meaningful. When your data consists of various patient chart document types (e.g. What is the P-Value?
Academic Quantitative Analysis represents the next chapter in zip code analysis; this form of analysis focuses on the interplay between variables after they have been operationalized, allowing the analyst to study and measure outcomes ( Quantitative and statistical research methods: from hypothesis to results , Bridgmon & Martin, 2006.).
Integration via Jupyter Notebooks Jupyter Notebooks offer a powerful environment for running Python in the same document, thanks to the support for multiple kernels. This ensures not only high-performing models but also well-documented, statistically sound results.
This community-driven approach ensures that there are plenty of useful analytics libraries available, along with extensive documentation and support materials. Statsmodels Allows users to explore data, estimate statistical models, and perform statistical tests. It is particularly useful for regression analysis and hypothesistesting.
Additionally, statistics and its various branches, including analysis of variance and hypothesistesting, are fundamental in building effective algorithms. Additionally, Python’s easy-to-learn syntax and extensive documentation make it an attractive choice for beginners in the field of machine learning.
Clean and Prepare Data: Ensure that your datasets are clean, well-organized, and properly documented. To glean useful information from the data, they employ statistical techniques including hypothesistesting, regression analysis, clustering, and time series analysis.
Accordingly, it is possible for the Python users to ask for help from Stack Overflow, mailing lists and user-contributed code and documentation. Accordingly, you need to make sense of the data that you derive from the various sources for which knowledge in probability, hypothesistesting, regression analysis is important.
Inferential Statistics: A branch of statistics that makes inferences about a population based on a sample, allowing for hypothesistesting and confidence intervals. J Jupyter Notebook: An open-source web application that allows users to create and share documents containing live code, equations, visualisations, and narrative text.
Play with this project live For more: See the full model registry overview in the documentation Selecting the best evaluation metrics Evaluation Metrics help us to decide the performance of a version of the algorithm. are captured and compared by formulating a hypothesistest to conclude with statistical significance.
If you’re thinking of a less formal internal assessment, the influential Closing the AI Accountability Gap puts forward a solid framework with worked documentation examples. t -, x 2 -, binomial z -, or Fisher’s exact tests). Disclaimer: I am a co-author of that document. Being a law firm, BNH.AI
Documentation: Keeping a record of the rejected outliers is essential for transparency. Nonparametric hypothesistesting Employing nonparametric tests reduces sensitivity to outliers, providing reliable results even when data distributions are skewed.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content