This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Intelligent document processing (IDP) is a technology that uses artificial intelligence (AI) and machinelearning (ML) to automatically extract information from unstructured documents such as invoices, receipts, and forms.
While it is true that MachineLearning today isn’t ready for prime time in many business cases that revolve around Document Analysis, there are indeed scenarios where a pure ML approach can be considered.
This article will provide you with a hands-on implementation on how to deploy an ML model in the Azure cloud. If you are new to Azure machinelearning, I would recommend you to go through the Microsoft documentation that has been provided in the […].
Google’s researchers have unveiled a groundbreaking achievement – Large Language Models (LLMs) can now harness MachineLearning (ML) models and APIs with the mere aid of tool documentation.
Ready to revolutionize the way you deploy machinelearning? Look no further than ML Ops – the future of ML deployment. MachineLearning (ML) has become an increasingly valuable tool for businesses and organizations to gain insights and make data-driven decisions. What is ML Ops?
Lack of diversity in data collection has caused significant failures in machinelearning (ML) applications. While ML developers perform post-collection interventions, these are time intensive and rarely comprehensive. Our process includes (1) Pre-Collection Planning, to reflexively prompt and document…
This year, generative AI and machinelearning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Ready to revolutionize the way you deploy machinelearning? Look no further than MLOps – the future of ML deployment. MachineLearning (ML) has become an increasingly valuable tool for businesses and organizations to gain insights and make data-driven decisions. What is MLOps?
If you’re diving into the world of machinelearning, AWS MachineLearning provides a robust and accessible platform to turn your data science dreams into reality. Introduction Machinelearning can seem overwhelming at first – from choosing the right algorithms to setting up infrastructure.
Machinelearning applications in healthcare are rapidly advancing, transforming the way medical professionals diagnose, treat, and prevent diseases. In this rapidly evolving field, machinelearning is poised to drive significant advancements in healthcare, improving patient outcomes and enhancing the overall healthcare experience.
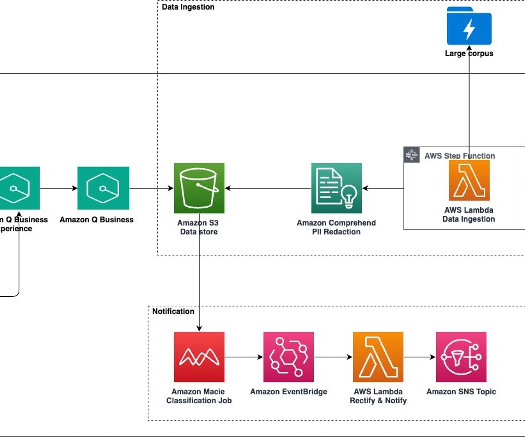
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
Machinelearning is the way of the future. Discover the importance of data collection, finding the right skill sets, performance evaluation, and security measures to optimize your next machinelearning project. Five tips for machinelearning projects – Data Science Dojo Let’s dive in.
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. For the detailed list of pre-set values, refer to the SDK documentation.
Model cards are becoming an essential part of the machinelearning landscape. As AI technologies continue to evolve and impact various sectors, the need for clear, standardized documentation about machinelearning models grows ever more critical. What are model cards?
Our work further motivates novel directions for developing and evaluating tools to support human-ML interactions. Model explanations have been touted as crucial information to facilitate human-ML interactions in many real-world applications where end users make decisions informed by ML predictions.
After completion of the program, Precise achieved Advanced tier partner status and was selected by a federal government agency to create a machinelearning as a service (MLaaS) platform on AWS. The platform helped the agency digitize and process forms, pictures, and other documents.
But what exactly is distributed learning in machinelearning? In this article, we will explore the concept of distributed learning and its significance in the realm of machinelearning. Why is it so important? This process is often referred to as training or model optimization.
Summary: Hydra simplifies process configuration in MachineLearning by dynamically managing parameters, organising configurations hierarchically, and enabling runtime overrides. It enhances scalability, experimentation, and reproducibility, allowing ML teams to focus on innovation.
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machinelearning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
ML models have grown significantly in recent years, and businesses increasingly rely on them to automate and optimize their operations. However, managing ML models can be challenging, especially as models become more complex and require more resources to train and deploy. What is MLOps?
AI for IT operations (AIOps) is the application of AI and machinelearning (ML) technologies to automate and enhance IT operations. They are commonly used to document repetitive tasks, troubleshooting steps, and routine maintenance.
You can try out the models with SageMaker JumpStart, a machinelearning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. To learn more, refer to the API documentation. The notebook includes example code and instructions for both.
Summary: MachineLearning algorithms enable systems to learn from data and improve over time. Introduction MachineLearning algorithms are transforming the way we interact with technology, making it possible for systems to learn from data and improve over time without explicit programming.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
Machinelearning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
Challenges in deploying advanced ML models in healthcare Rad AI, being an AI-first company, integrates machinelearning (ML) models across various functions—from product development to customer success, from novel research to internal applications. Rad AI’s ML organization tackles this challenge on two fronts.
Amazon Lookout for Vision , the AWS service designed to create customized artificial intelligence and machinelearning (AI/ML) computer vision models for automated quality inspection, will be discontinuing on October 31, 2025.
Let us delve into machinelearning-powered change detection, where innovative algorithms and spatial analysis combine to completely revolutionize how we see and react to our ever-changing surroundings. Why Using Change detection ML is important for Spatial Analysis.
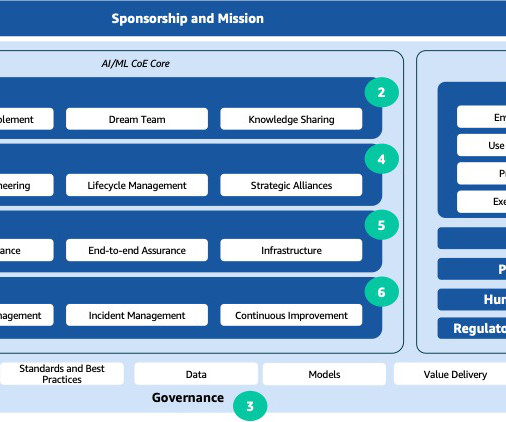
The rapid advancements in artificial intelligence and machinelearning (AI/ML) have made these technologies a transformative force across industries. An effective approach that addresses a wide range of observed issues is the establishment of an AI/ML center of excellence (CoE). What is an AI/ML CoE?
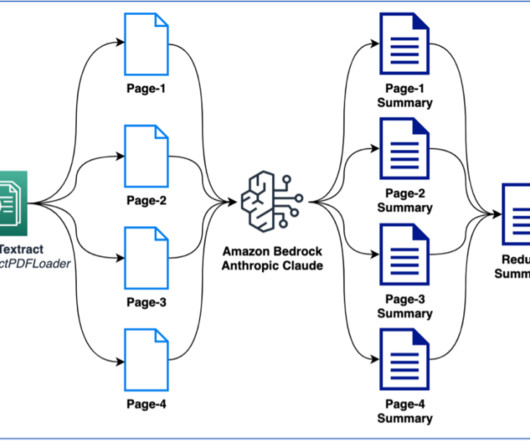
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
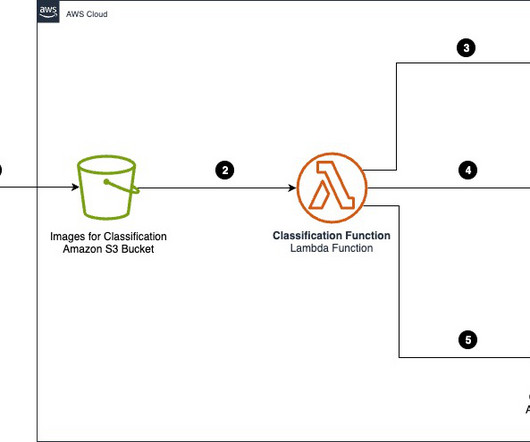
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
R has become ideal for GIS, especially for GIS machinelearning as it has topnotch libraries that can perform geospatial computation. R has simplified the most complex task of geospatial machinelearning and data science. Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
See Best practices for data source connector configuration in Amazon Q Business to understand best practices To improve retrieved results and customize the end user chat experience, use Amazon Q to map document attributes from your data sources to fields in your Amazon Q index. Select the data source to edit its configurations under Actions.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
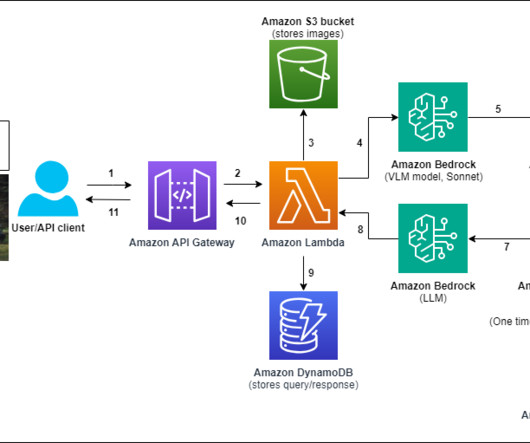
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment. The documentation can be in a variety of formats.
Generative MachineLearning models have been well documented as being able to produce explicit adult content, including child sexual abuse material (CSAM) as well as to alter benign imagery of a cl.
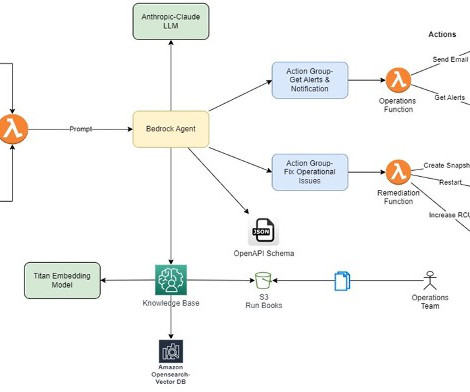
For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer questions relevant to a particular business or use case. Generate a grounded response to the original question based on the retrieved documents.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machinelearning (ML) services for a mortgage underwriting use case.
Artificial intelligence and machinelearning are no longer the elements of science fiction; they’re the realities of today. With the ability to analyze a vast amount of data in real-time, identify patterns, and detect anomalies, AI/ML-powered tools are enhancing the operational efficiency of businesses in the IT sector.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
Heres how embeddings power these advanced systems: Semantic Understanding LLMs use embeddings to represent words, sentences, and entire documents in a way that captures their semantic meaning. The process enables the models to find the most relevant sections of a document or dataset, improving the accuracy and relevance of their outputs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content