This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NaturalLanguageProcessing (NLP) is revolutionizing the way we interact with technology. By enabling computers to understand and respond to human language, NLP opens up a world of possibilitiesfrom enhancing user experiences in chatbots to improving the accuracy of search engines.
The post Latent Semantic Analysis and its Uses in NaturalLanguageProcessing appeared first on Analytics Vidhya. Textual data, even though very important, vary considerably in lexical and morphological standpoints. Different people express themselves quite differently when it comes to […].
Introduction DocVQA (Document Visual Question Answering) is a research field in computer vision and naturallanguageprocessing that focuses on developing algorithms to answer questions related to the content of a document, like a scanned document or an image of a text document.
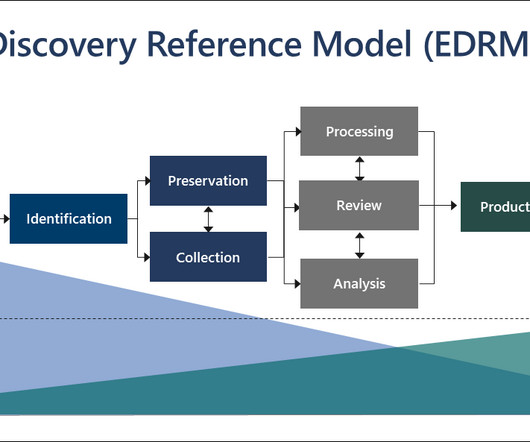
Anyhow, with the exponential growth of digital data, manual document review can be a challenging task. Hence, AI has the potential to revolutionize the eDiscovery process, particularly in document review, by automating tasks, increasing efficiency, and reducing costs.
Introduction A highly effective method in machinelearning and naturallanguageprocessing is topic modeling. A corpus of text is an example of a collection of documents. This technique involves finding abstract subjects that appear there.
In this paper we present a new method for automatic transliteration and segmentation of Unicode cuneiform glyphs using NaturalLanguageProcessing (NLP) techniques. Cuneiform is one of the earliest known writing system in the world, which documents millennia of human civilizations in the ancient Near East.
10+ Python packages for NaturalLanguageProcessing that you can’t miss, along with their corresponding code.Foto di Max Duzij su Unsplash NaturalLanguageProcessing is the field of Artificial Intelligence that involves text analysis. It combines statistics and mathematics with computational linguistics.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
In the field of software development, generative AI is already being used to automate tasks such as code generation, bug detection, and documentation. Bug detection: OpenAI’s machinelearning models can be used to detect bugs and errors in code. Prompt: "Generate documentation for the following function."
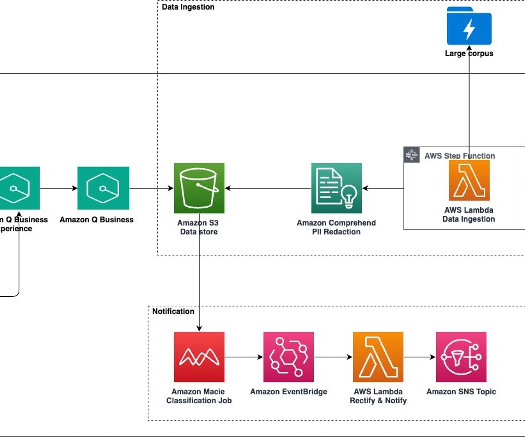
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. The Process Data Lambda function redacts sensitive data through Amazon Comprehend.
Over the past few years, a shift has shifted from NaturalLanguageProcessing (NLP) to the emergence of Large Language Models (LLMs). Transformers, a type of Deep Learning model, have played a crucial role in the rise of LLMs.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
Classification in machinelearning involves the intriguing process of assigning labels to new data based on patterns learned from training examples. Machinelearning models have already started to take up a lot of space in our lives, even if we are not consciously aware of it.
Here are some key ways data scientists are leveraging AI tools and technologies: 6 Ways Data Scientists are Leveraging Large Language Models with Examples Advanced MachineLearning Algorithms: Data scientists are utilizing more advanced machinelearning algorithms to derive valuable insights from complex and large datasets.
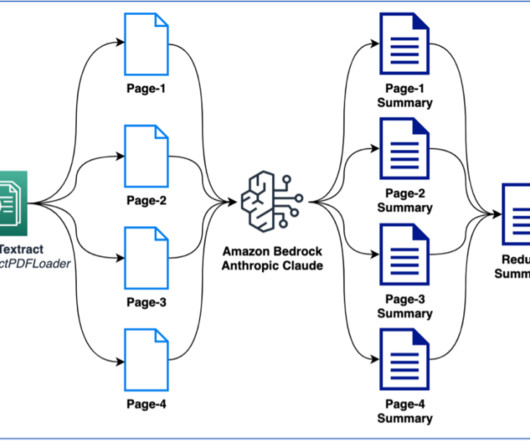
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
This is significant for medical professionals who need to process millions to billions of patient notes without straining computing budgets. You can try out the models with SageMaker JumpStart, a machinelearning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
Embeddings are a key building block of large language models. They are used to represent words as vectors of numbers, which can then be used by machinelearning models to understand the meaning of text. This can make it difficult for machinelearning models to learn the correct meaning of words.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. Confidence scores and human review Maintaining data accuracy and quality is paramount in any documentprocessing solution.
I work on machinelearning for naturallanguageprocessing, and I’m particularly interested in few-shot learning, lifelong learning, and societal and health applications such as abuse detection, misinformation, mental ill-health detection, and language assessment. Data science is a broad field.
In the recent past, using machinelearning (ML) to make predictions, especially for data in the form of text and images, required extensive ML knowledge for creating and tuning of deep learning models. These capabilities include pre-trained models for image, text, and document data types.
Key components include machinelearning, which allows systems to learn from data, and naturallanguageprocessing, enabling machines to understand and respond to human language. Legal: AI improves document analysis, streamlining legal research.
Healthcare system faces persistent challenges due to its heavy reliance on manual processes and fragmented communication. Providers struggle with the administrative burden of documentation and coding, which consumes 2531% of total healthcare spending and detracts from their ability to deliver quality care.
For example, imagine a consulting firm that manages documentation for multiple healthcare providerseach customers sensitive patient records and operational documents must remain strictly separated. Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional documentprocessing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations.
After completion of the program, Precise achieved Advanced tier partner status and was selected by a federal government agency to create a machinelearning as a service (MLaaS) platform on AWS. The platform helped the agency digitize and process forms, pictures, and other documents.
The new age focus uses naturallanguageprocessing to help businesses create more effective marketing messages. Its platform can analyze customer data and generate language that resonates with specific audiences. Its platform uses machinelearning to analyze ad data and provide insights and recommendations.
For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. You can follow the steps provided in the Deleting a stack on the AWS CloudFormation console documentation to delete the resources created for this solution.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
GPT-4 with Vision combines naturallanguageprocessing capabilities with computer vision. It could be a game-changer in digitizing written or printed documents by converting images of text into a digital format. Object Detection GPT-4V has superior object detection capabilities.
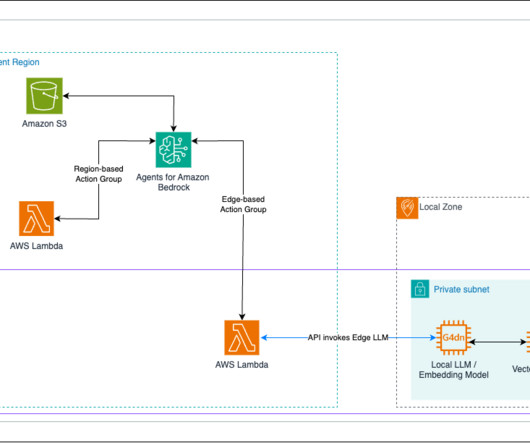
Moreover, interest in small language models (SLMs) that enable resource-constrained devices to perform complex functionssuch as naturallanguageprocessing and predictive automationis growing. These documents are chunked by the application and are sent to the embedding model.
Examples of such tools include intelligent business process management, decision management, and business rules management AI and machinelearning tools that enhance the capabilities of automation. Additionally, organizations can extend the power of automation by incorporating AI and machinelearning in different ways.
Ever-growing volumes of unstructured data stored in countless document formats significantly complicate data processing and timely access to relevant …
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machinelearning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Extracts of AEP documentation, describing each Measure type covered, its input and output types, and how to use it. An in-context learning technique that includes semantically relevant solved questions and answers in the prompt. About the Authors Javier Beltrn is a Senior MachineLearning Engineer at Aetion.
Data understanding Next, machinelearning techniques are leveraged to recognize patterns within the data. Document structuring Once key topics are identified, a structured outline for the document is created. This foundational step is crucial for determining what information will be included in the generated content.
In this two-part series, we introduce the abstracted layer of the SageMaker Python SDK that allows you to train and deploy machinelearning (ML) models by using the new ModelTrainer and the improved ModelBuilder classes. For the detailed list of pre-set values, refer to the SDK documentation. amazonaws.com/pytorch-training:2.0.0-cpu-py310"
Pinecone is a vector database that is designed for machinelearning applications. It is fast, scalable, and supports a variety of machinelearning algorithms. They are used in a variety of AI applications, such as image search, naturallanguageprocessing, and recommender systems.
The rise of large language models (LLMs) and foundation models (FMs) has revolutionized the field of naturallanguageprocessing (NLP) and artificial intelligence (AI). You can find instructions on how to do this in the AWS documentation for your chosen SDK. He is passionate about cloud and machinelearning.
Merlin is a comprehensive AI-powered assistant designed to enhance productivity by integrating advanced naturallanguageprocessing (NLP) models like GPT-4 and Claude-3 into everyday tasks. While the process was smooth, we found that the output wasn’t entirely accurate based on our input.
Machinelearning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. Inference experiment: Real-time document understanding with LayoutLM Inference, as opposed to training, is a continuous, unbounded workload that doesn’t have a defined completion point.
Translating naturallanguage into vectors reduces the richness of the information, potentially leading to less accurate answers. Also, end-user queries are not always aligned semantically to useful information in provided documents, leading to vector search excluding key data points needed to build an accurate answer.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content