This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning applications in healthcare are rapidly advancing, transforming the way medical professionals diagnose, treat, and prevent diseases. In this rapidly evolving field, machinelearning is poised to drive significant advancements in healthcare, improving patient outcomes and enhancing the overall healthcare experience.
Imagine a tool so versatile that it can compose music, generate legal documents, assist in developing vaccines, and even create artwork that seems to have sprung from the brush of a Renaissance master. SupervisedLearning: The AI learns from a dataset that has predefined labels.
Summary: MachineLearning algorithms enable systems to learn from data and improve over time. Introduction MachineLearning algorithms are transforming the way we interact with technology, making it possible for systems to learn from data and improve over time without explicit programming.
Classification in machinelearning involves the intriguing process of assigning labels to new data based on patterns learned from training examples. Machinelearning models have already started to take up a lot of space in our lives, even if we are not consciously aware of it. 0 or 1, yes or no, etc.).
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning? temperature, salary).
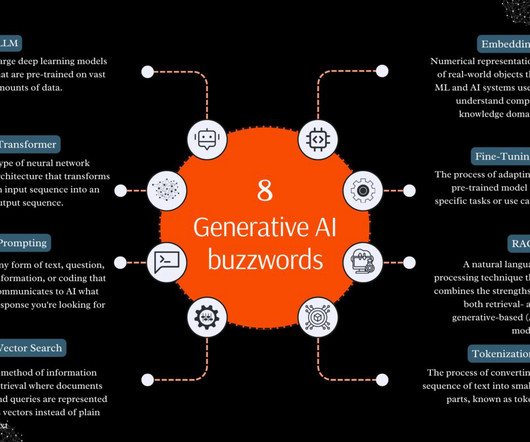
Large language models A large language model refers to any model that undergoes training on extensive and diverse datasets, typically through self-supervisedlearning at a large scale, and is capable of being fine-tuned to suit a wide array of specific downstream tasks. The highest scoring response is returned.
Created by the author with DALL E-3 R has become very ideal for GIS, especially for GIS machinelearning as it has topnotch libraries that can perform geospatial computation. R has simplified the most complex task of geospatial machinelearning. Advantages of Using R for MachineLearning 1.
With the emergence of ARCGISpro which will replace ArcMap by 2026 mainly focusing on data science and machinelearning, all the signs that machinelearning is the future of GIS and you might have to learn some principles of data science, but where do you start, let us have a look. GIS Random Forest script.
Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machinelearning (ML) that involves training algorithms using a labeled dataset. An FM-driven solution can also provide rationale for outputs, whereas a traditional classifier lacks this capability.
But what exactly is distributed learning in machinelearning? In this article, we will explore the concept of distributed learning and its significance in the realm of machinelearning. Why is it so important? This process is often referred to as training or model optimization.
The competition for best algorithms can be just as intense in machinelearning and spatial analysis, but it is based more objectively on data, performance, and particular use cases. Community & Support: Verify the availability of documentation and the level of community support.
Summary: MachineLearning is categorised into four main types: supervised, unsupervised, semi-supervised, and Reinforcement Learning. Introduction MachineLearning is revolutionising industries by enabling machines to learn from data and make decisions without explicit programming.
Application mapping, also known as application topology mapping, is a process that involves identifying and documenting the functional relationships between software applications within an organization. It provides a detailed view of how different applications interact, depend on each other, and contribute to the business processes.
Summary: This blog highlights ten crucial MachineLearning algorithms to know in 2024, including linear regression, decision trees, and reinforcement learning. Introduction MachineLearning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion in 2022 and is expected to grow to USD 505.42
Moving across the typical machinelearning lifecycle can be a nightmare. Machinelearning platforms are increasingly looking to be the “fix” to successfully consolidate all the components of MLOps from development to production. What is a machinelearning platform? That’s where this guide comes in!
Summary: Entropy in MachineLearning quantifies uncertainty, driving better decision-making in algorithms. It optimises decision trees, probabilistic models, clustering, and reinforcement learning. This concept, pivotal in understanding data structures and communication systems, plays a significant role in MachineLearning.
Familiarity with basic programming concepts and mathematical principles will significantly enhance your learning experience and help you grasp the complexities of Data Analysis and MachineLearning. Basic Programming Concepts To effectively learn Python, it’s crucial to understand fundamental programming concepts.
Summary: Support Vector Machine (SVM) is a supervisedMachineLearning algorithm used for classification and regression tasks. Introduction MachineLearning has revolutionised various industries by enabling systems to learn from data and make informed decisions.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Inability to learn: RPA cannot learn from past experiences or adapt to new situations without human intervention. What is machinelearning (ML)?
Let’s first take a look at the process of supervisedlearning as motivation. Supervisedlearning The term supervisedlearning describes, at a high-level, one paradigm in which data can be used to train an AI model. They can summarize documents, translate between languages, answer questions, and more.
Photo by Robo Wunderkind on Unsplash In general , a data scientist should have a basic understanding of the following concepts related to kernels in machinelearning: 1. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearning algorithm used for classification and regression analysis.
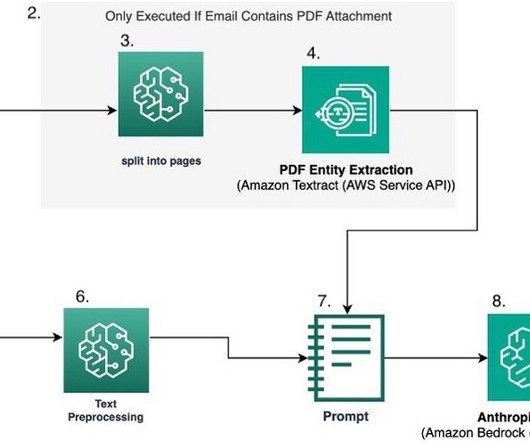
This includes formats like emails, PDFs, scanned documents, images, audio, video, and more. While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. Solution overview In this post, we work with a PDF documentation dataset— Amazon Bedrock user guide.
Ramcharan12345 is looking to collaborate with AI devs who can leverage spaCy for NLP, utilize scikit-learn for supervisedlearning on historical data for symptom mapping, and implement TensorFlow/Keras for neural network-based risk prediction. Keep an eye on this section, too — we share cool opportunities every week!
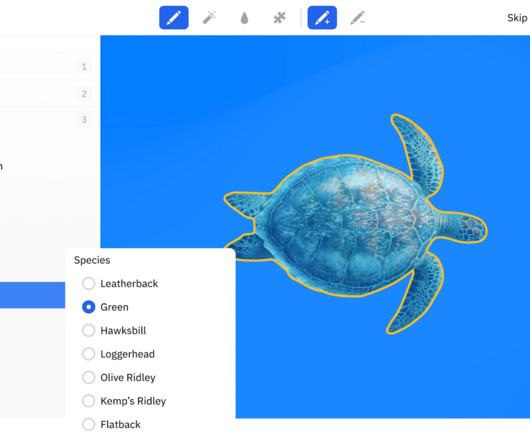
Image labeling and annotation are the foundational steps in accurately labeling the image data and developing machinelearning (ML) models for the computer vision task. In this article, you will learn about the importance of image annotation and what you should know for annotating image files for machinelearning at scale.
Recently, I became interested in machinelearning, so I was enrolled in the Yandex School of Data Analysis and Computer Science Center. Machinelearning is my passion and I often participate in competitions. The semi-supervisedlearning was repeated using the gemma2-9b model as the soft labeling model.
Semi-Supervised Sequence Learning As we all know, supervisedlearning has a drawback, as it requires a huge labeled dataset to train. Having used multiple source documents, there have been duplicates and resulted in a huge set, which is impossible to train a model on, due to lack of processing power.
Self-supervision: As in the Image Similarity Challenge , all winning solutions used self-supervisedlearning and image augmentation (or models trained using these techniques) as the backbone of their solutions. Our strong interest on deep metric learning motivated us to compete in this challenge.
Word2vec is useful for various natural language processing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. Text classification is essential for applications like web searches, information retrieval, ranking, and document classification. Set the learning mode hyperparameter to supervised.
A non-parametric, supervisedlearning classifier, the K-Nearest Neighbors (k-NN) algorithm uses proximity to classify or predict how a single data point will be grouped. It is among the most widely used and straightforward regression and classification classifiers in machinelearning today. What is K Nearest Neighbor?
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machinelearning. The core process is a general technique known as self-supervisedlearning , a learning paradigm that leverages the inherent structure of the data itself to generate labels for training.
Artificial intelligence, machinelearning, natural language processing, and other related technologies are paving the way for a smarter “everything.” Within NLP, data labeling allows machinelearning models to isolate finance-related variables in different datasets. How Does Data Labeling Work in Finance?
Using such data to train a model is called “supervisedlearning” On the other hand, pretraining requires no such human-labeled data. This process is called “self-supervisedlearning”, and is identical to supervisedlearning except for the fact that humans don’t have to create the labels.
Summary: Data annotation is crucial for training MachineLearning models by adding meaningful labels to raw data. Introduction Data annotation is the process of adding meaningful labels, tags, or metadata to raw data to provide context and structure for MachineLearning algorithms.
MachineLearning is becoming increasingly popular in the current tech-savvy era. the application of MachineLearning is everywhere from image recognition to complex forecast models. However, the most complex and expensive type of MachineLearning trend in use is Labelled Data. How does Data Labelling Work?
Photo by Clay Banks on Unsplash Let’s learn about David! link] David Mezzetti is the founder of NeuML, a data analytics and machinelearning company that develops innovative products backed by machinelearning. For each query, an embeddings query identifies the list of best matching documents.
Unlike traditional software programs, AI agents use machinelearning models to adapt their behavior based on data. MachineLearning Basics Machinelearning (ML) enables AI agents to learn patterns from data without explicit programming. Youd use supervisedlearning with labeled email datasets.
It’s the underlying engine that gives generative models the enhanced reasoning and deep learning capabilities that traditional machinelearning models lack. They can also perform self-supervisedlearning to generalize and apply their knowledge to new tasks.
A definition from the book ‘Data Mining: Practical MachineLearning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Classification. Regression. Common Applications.
AI-powered Time Series Forecasting may be the most powerful aspect of machinelearning available today. supervisedlearning and time series regression). The machinelearning life cycle always starts with the dataset. Generate Model Compliance Documentation. Setting up a Time Series Project.
Robotic process automation vs machinelearning is a common debate in the world of automation and artificial intelligence. Inability to learn: RPA cannot learn from past experiences or adapt to new situations without human intervention. What is machinelearning (ML)?
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machinelearning and deep learning. Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence.
By understanding crucial concepts like MachineLearning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content