This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
Intelligent documentprocessing (IDP) is transforming the way businesses manage their documentation and data management processes. By harnessing the power of emerging technologies, organizations can automate the extraction and handling of data from various document types, significantly enhancing operational workflows.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. This substantial reduction in processing time not only accelerates workflows but also minimizes the risk of manual errors.
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. For the detailed list of pre-set values, refer to the SDK documentation.
Machine learning (ML) has emerged as a powerful tool to help nonprofits expedite manual processes, quickly unlock insights from data, and accelerate mission outcomesfrom personalizing marketing materials for donors to predicting member churn and donation patterns. For a full list of custom model types, check out this documentation.
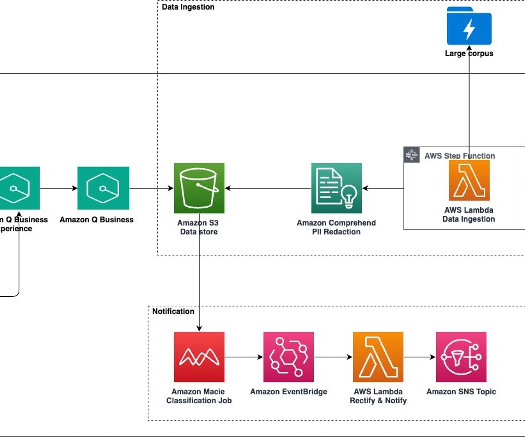
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. The Process Data Lambda function redacts sensitive data through Amazon Comprehend.
The platform helped the agency digitize and process forms, pictures, and other documents. Using the platform, which uses Amazon Textract , AWS Fargate , and other services, the agency gained a four-fold productivity improvement by streamlining and automating labor-intensive manual processes.
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. To learn more, refer to the API documentation. Both models support a context window of 32,000 tokens, which is roughly 50 pages of text.
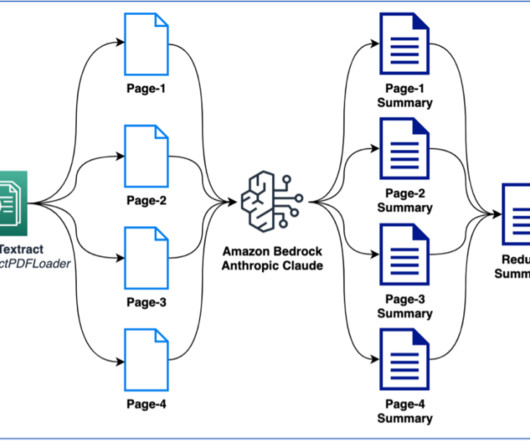
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional documentprocessing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations.
Both have the potential to transform the way organizations operate, enabling them to streamline processes, improve efficiency, and drive business outcomes. However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. What is machine learning (ML)?
In India, the KYC verification usually involves identity verification through identification documents for Indian citizens, such as a PAN card or Aadhar card, address verification, and income verification. They have developed a solution that fully automates the customer onboarding, KYC verification, and credit underwriting process.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Enterprises seek to harness the potential of Machine Learning (ML) to solve complex problems and improve outcomes. Until recently, building and deploying ML models required deep levels of technical and coding skills, including tuning ML models and maintaining operational pipelines.
With the ability to analyze a vast amount of data in real-time, identify patterns, and detect anomalies, AI/ML-powered tools are enhancing the operational efficiency of businesses in the IT sector. Why does AI/ML deserve to be the future of the modern world? Let’s understand the crucial role of AI/ML in the tech industry.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data.
LLM companies are businesses that specialize in developing and deploying Large Language Models (LLMs) and advanced machine learning (ML) models. It has also risen as a dominant player in the LLM space, leading the changes within the landscape of naturallanguageprocessing and AI-driven solutions.
Mortgage processing is a complex, document-heavy workflow that demands accuracy, efficiency, and compliance. Recent industry surveys indicate that only about half of borrowers express satisfaction with the mortgage process, with traditional banks trailing non-bank lenders in borrower satisfaction. Why agentic IDP?
Moreover, interest in small language models (SLMs) that enable resource-constrained devices to perform complex functionssuch as naturallanguageprocessing and predictive automationis growing. These documents are chunked by the application and are sent to the embedding model.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering naturallanguage questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2
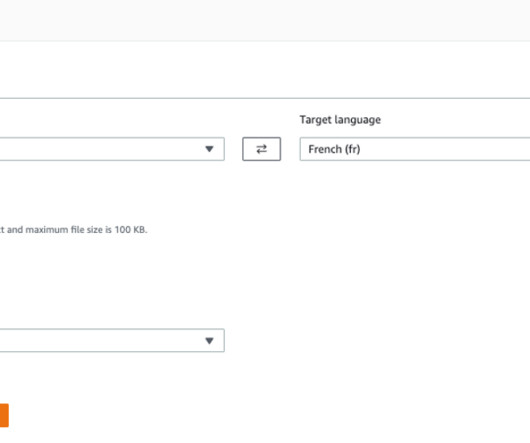
Now, Amazon Translate offers real-time document translation to seamlessly integrate and accelerate content creation and localization. This feature eliminates the wait for documents to be translated in asynchronous batch mode. This feature eliminates the wait for documents to be translated in asynchronous batch mode.
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. Amazon Bedrock Data Automation is expanding to additional Regions, so be sure to check the documentation for the latest updates. billion in 2025 to USD 66.68
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
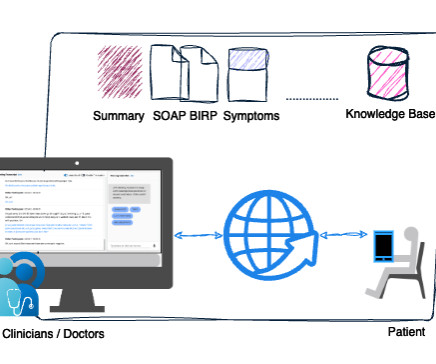
Today, physicians spend about 49% of their workday documenting clinical visits, which impacts physician productivity and patient care. By using the solution, clinicians don’t need to spend additional hours documenting patient encounters. This blog post focuses on the Amazon Transcribe LMA solution for the healthcare domain.
The second approach is using SageMaker JumpStart, a machine learning (ML) hub, with foundation models (FMs), built-in algorithms, and pre-built ML solutions. This resource includes integration examples, API documentation, and programming samples. You can deploy pre-trained models using either the Amazon SageMaker console or SDK.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters. python3.11-pip jars/livy-repl_2.12-0.7.1-incubating.jar
Hyper automation, which uses cutting-edge technologies like AI and ML, can help you automate even the most complex tasks. It’s also about using AI and ML to gain insights into your data and make better decisions. ML algorithms enable systems to identify patterns, make predictions, and take autonomous actions.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. For queries earning negative feedback, less than 1% involved answers or documentation deemed irrelevant to the original question.
As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for naturallanguageprocessing tasks. Lets say you are able to successfully serve 10 requests users in parallel with one ML instance.
Extracts of AEP documentation, describing each Measure type covered, its input and output types, and how to use it. His career has focused on naturallanguageprocessing, and he has experience applying machine learning solutions to various domains, from healthcare to social media.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
The following example shows how prompt optimization converts a typical prompt for a summarization task on Anthropics Claude Haiku into a well-structured prompt for an Amazon Nova model, with sections that begin with special markdown tags such as ## Task, ### Summarization Instructions , and ### Document to Summarize.
GPUs: The versatile powerhouses Graphics Processing Units, or GPUs, have transcended their initial design purpose of rendering video game graphics to become key elements of Artificial Intelligence (AI) and Machine Learning (ML) efforts. However, it’s not time to discard your GPUs just yet.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow.
What sets Amazon Q Business apart is its support of enterprise requirements from its ability to integrate with company documentation to its adaptability with specific business terminology and context-aware responses. You can access the Amazon Q Business documentprocessing features from the Word context menu when you highlight text.
In the recent past, using machine learning (ML) to make predictions, especially for data in the form of text and images, required extensive ML knowledge for creating and tuning of deep learning models. Today, ML has become more accessible to any user who wants to use ML models to generate business value.
For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. You can follow the steps provided in the Deleting a stack on the AWS CloudFormation console documentation to delete the resources created for this solution.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models.
AI in marketing refers to the use of machine learning (ML), naturallanguageprocessing (NLP), and predictive analytics to automate, optimize, and personalize campaigns at scale. Pro Tip “Treat AI like a new hiretrain it with clean data, document its decisions, and supervise its work.”
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content