This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Their impact on ML tasks has made them a cornerstone of AI advancements. It allows ML models to work with data but in a limited manner. Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning.
Large language models A large language model refers to any model that undergoes training on extensive and diverse datasets, typically through self-supervisedlearning at a large scale, and is capable of being fine-tuned to suit a wide array of specific downstream tasks. The highest scoring response is returned.
There are various types of machine learning algorithms, including supervisedlearning, unsupervised learning, and reinforcement learning. In supervisedlearning, the model learns from labeled examples, where the input data is paired with corresponding target labels.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
Their impact on ML tasks has made them a cornerstone of AI advancements. It allows ML models to work with data but in a limited manner. Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning.
Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. An FM-driven solution can also provide rationale for outputs, whereas a traditional classifier lacks this capability.
Types of Machine Learning Algorithms Machine Learning has become an integral part of modern technology, enabling systems to learn from data and improve over time without explicit programming. The goal is to learn a mapping from inputs to outputs, allowing the model to make predictions on unseen data.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Machine learning applications in healthcare are revolutionizing the way we approach disease prevention and treatment Machine learning is broadly classified into three categories: supervisedlearning, unsupervised learning, and reinforcement learning.
Additionally, the elimination of human loop processes has made it possible for AI/ML to construct training data for data annotation and labeling, which has a major influence on geospatial data. This function can be improved by AI and ML, which allow GIS to produce insights, automate procedures, and learn from data.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
ML teams have a very important core purpose in their organizations - delivering high-quality, reliable models, fast. With users’ productivity in mind, at DagHub we aimed for a solution that will provide ML teams with the whole process out of the box and with no extra effort.
It is a supervisedlearning methodology that predicts if a piece of text belongs to one category or the other. As a machine learning engineer, you start with a labeled data set that has vast amounts of text that have already been categorized. Make sure you have your API key from your Comet ML’s account then create a ~/.comet.yml.
The advancement of technology in large language models (LLMs), machine learning (ML), and data science can truly transform industries through insights and predictions. AI and ML initiatives without a strategy have a tendency to fail , but they don’t always fail in the same way. What are the Benefits of Building an AI Strategy?
Rapid, model-guided iteration with New Studio for all core ML tasks. Enhanced studio experience for all core ML tasks. Prompt LF Builder: Explore and label data through natural language prompts using FM knowledge and translate it into labeling functions for your weakly supervisedlearning use cases. Advanced SDK tools.
Self-supervision: As in the Image Similarity Challenge , all winning solutions used self-supervisedlearning and image augmentation (or models trained using these techniques) as the backbone of their solutions. Image models are also less computationally intensive, making it easier to satisfy the resource constraint.
Text classification is essential for applications like web searches, information retrieval, ranking, and document classification. Set the learning mode hyperparameter to supervised. BlazingText has both unsupervised and supervisedlearning modes. Our use case is text classification, which is supervisedlearning.
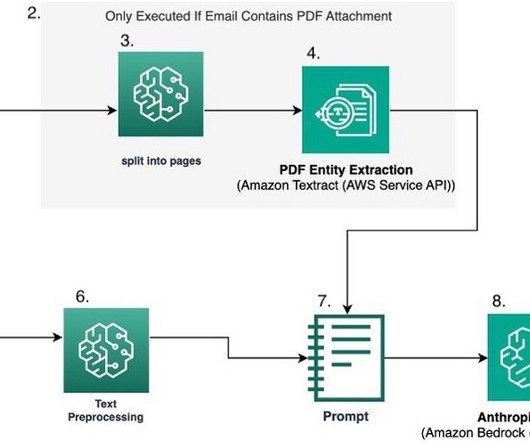
This includes formats like emails, PDFs, scanned documents, images, audio, video, and more. While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. Solution overview In this post, we work with a PDF documentation dataset— Amazon Bedrock user guide.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance. As we move into 2024, understanding the key algorithms that drive Machine Learning is essential for anyone looking to work in this field.
Creating high-performance machine learning (ML) solutions relies on exploring and optimizing training parameters, also known as hyperparameters. We can revise the hyperparameters and their value ranges based on what we learned and therefore turn this optimization effort into a conversation. We use a Random Forest from SkLearn.
We want to, first and foremost, label these documents. Typically, you let the experts read some articles, label them, and then use them as training data and train the supervisedlearning model. To address all these problems, we looked into weak supervisedlearning. But this is not a scalable approach.
We want to, first and foremost, label these documents. Typically, you let the experts read some articles, label them, and then use them as training data and train the supervisedlearning model. To address all these problems, we looked into weak supervisedlearning. But this is not a scalable approach.
As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale. Supporting the operations of data scientists and ML engineers requires you to reduce—or eliminate—the engineering overhead of building, deploying, and maintaining high-performance models.
Machine Learning Basics Machine learning (ML) enables AI agents to learn patterns from data without explicit programming. There are three main types: SupervisedLearning: Training a model with labeled data. Unsupervised Learning: Finding hidden structures in unlabeled data.
supervisedlearning and time series regression). Note: the DataRobot platform supports both supervised and unsupervised learning. Configuring an ML project. To begin training your model, just hit the Start button and let the DataRobot platform train ML models for you. Generate Model Compliance Documentation.
Project Tailwind also made use of early research prototypes of MakerSuite to develop features to help writers and researchers explore ideas and improve their prose; its AI-first notebook prototype used PaLM 2 to allow users to ask questions of the model grounded in documents they define. Med-PaLM 2 achieved 86.5% performance on U.S.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. Best AI models can be used in healthcare to improve diagnosis and treatment.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. Best AI models can be used in healthcare to improve diagnosis and treatment.
At the beginning of my machine learning journey, I was convinced that creating an ML model always looks similar. But most real-world machine learning (ML) projects are not like that. These problems keep many ML practitioners awake at night. If you’re part of this group, continual learning is exactly what you need.
It allows you to create and share live code, equations, visualisations, and narrative text documents. Machine Learning with Python Machine Learning is a vital component of Data Science, enabling systems to learn from data and make predictions. Jupyter Notebook is another vital tool for Data Science.
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). Machine Learning Engineer at AWS. In her free time, Laura enjoys exploring new places by bike.
Application mapping, also known as application topology mapping, is a process that involves identifying and documenting the functional relationships between software applications within an organization. It provides a detailed view of how different applications interact, depend on each other, and contribute to the business processes.
" } In general cases, we always have data in the form of paragraphs and documents. Even though traditional datasets are always in the form of a series of documents of either text files or word files, The problem with it is we can not feed it directly to LLM models as it requires data in a specific format.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. And in supervisedlearning, it has to be labeled data.
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. And in supervisedlearning, it has to be labeled data.
Evaluation Techniques for Large Language Models Rajiv Shah, PhD | Machine Learning Engineer | Hugging Face Selecting the right LLM for your needs has become increasingly complex. During this tutorial, you’ll learn about the practical tools and best practices for evaluating and choosing LLMs.
Data Labelling is the process of adding meaning to different datasets ensuring that it can be used properly to train a Machine Learning model. Labeled data in Machine Learning is typically used in the case of SupervisedLearning where the labeled data is input to a model. How does Data Labelling Work?
Abhishek Ratna, in AI ML marketing, and TensorFlow developer engineer Robert Crowe, both from Google, spoke as part of a panel entitled “Practical Paths to Data-Centricity in Applied AI” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. And in supervisedlearning, it has to be labeled data.
We will discuss how models such as ChatGPT will affect the work of software engineers and ML engineers. Will ChatGPT replace ML Engineers? A similar approach was used in “ Exploring the limits of transfer learning with a unified text-to-text transformer ” which introduced a model called T5. Why is ChatGPT so effective?
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning? Self-supervisedlearning is a kind of machine learning that creates labels directly from the input data. Find out in the guide below.
At the same time as the emergence of powerful RL systems in the real world, the public and researchers are expressing an increased appetite for fair, aligned, and safe machine learning systems. However the unique ability of RL systems to leverage temporal feedback in learning complicates the types of risks and safety concerns that can arise.
Analysis and synthesis tasks, like crafting new documents or emails from a few sentences of guidance, or partnering with people to jointly write software together. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























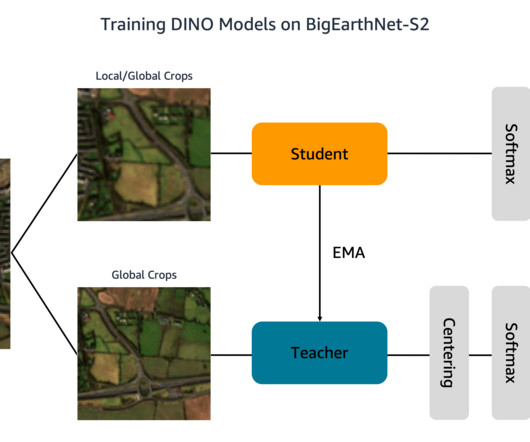










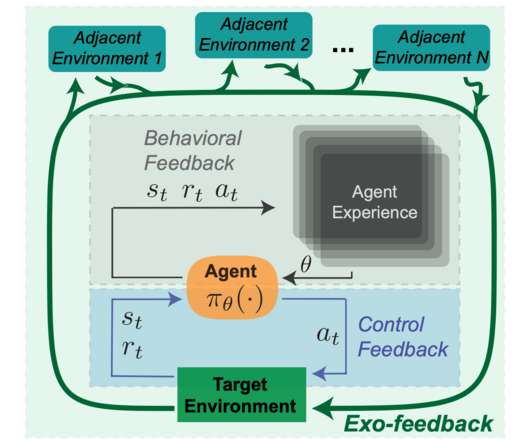







Let's personalize your content