This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
Layered System: REST API should be designed in a layered systemarchitecture, where each layer has a specific role and responsibility. The layered systemarchitecture helps to promote scalability, reliability, and flexibility. The uniform interface helps to simplify the API and promotes reusability.
For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer questions relevant to a particular business or use case. Generate a grounded response to the original question based on the retrieved documents.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. One more embellishment is to use a graph neural network (GNN) trained on the documents. Chunk your documents from unstructured data sources, as usual in GraphRAG. at Facebook—both from 2020.
Understanding systemarchitecture A killswitch engineer at OpenAI would be responsible for more than just pulling a plug. The role necessitates a deep understanding of systemarchitecture, including the layers of hardware and software that run AI models like upcoming GPT-5.
To generate a useful response, the chat would need to reference different data sources, including the unstructured documents in your knowledge base (such as policy documentation about what causes an account suspension) and structured data such as transaction history and real-time account activity.
I’ll start with a simple task: classify if an image is a real paper document, or it’s an image of a screen with some document on it. Real document Screen And this one is pretty straightforward. Not a document Here is the structure of our dataset: dataset/├── documents/│ ├── img_1.jpgU+007C.│ jpg│.│ └── img_100.jpg├──
To use Automated Reasoning checks, you first create an Automated Reasoning policy by encoding a set of logical rules and variables from available source documentation. Automated Reasoning checks deliver deterministic verification of model outputs against documented rules, complete with audit trails and mathematical proof of policy adherence.
We present our experience in making design decisions about the model and systemarchitecture for CodeCompose that addresses these challenges. We discuss unique challenges in terms of user experience and metrics that arise when deploying such tools in large-scale industrial settings. million suggestions were made by CodeCompose.
Let’s transition to exploring solutions and architectural strategies. Approaches to researcher productivity To translate our strategic planning into action, we developed approaches focused on refining our processes and systemarchitectures. No one writes any code manually.
A Highlight in Simplicity: The Looker Dashboard After investing significant time and effort into designing a robust systemarchitecture and ensuring top-tier security, it was somewhat surprising to see what garnered the most attention within the organization: a Looker dashboard.
They must grasp how decentralized applications integrate into this ecosystem while ensuring they craft algorithms that prioritize security and efficacy alongside maintaining node operationsall tailored towards accommodating specific scale parameters and performance goals within a given systemsarchitecture.
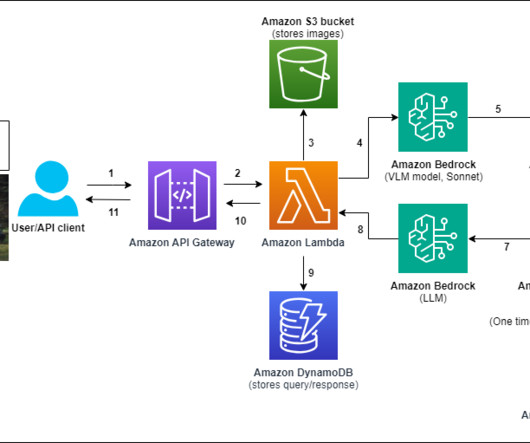
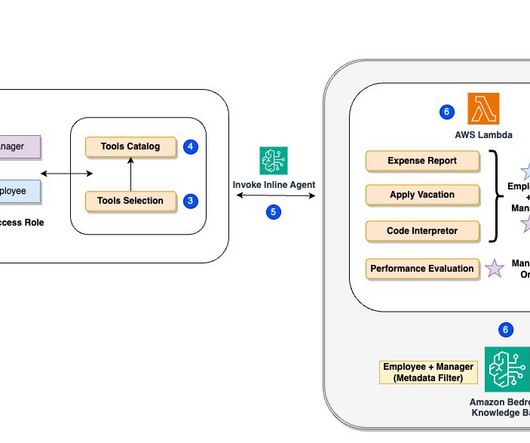
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. To understand how this dynamic role-based functionality works under the hood, lets examine the following systemarchitecture diagram.
This session explores how multimodal agents can interpret complex inputslike documents or visual dataand respond intelligently, enabling use cases far beyond simple text-based tasks. Agentic AI in Action: Build Autonomous Multi-Agent Systems (Hands-On inPython) Edward Donner, Co-founder and CTO of Nebula.io
Flash to build a RAG system that understands both text and images enabling accurate answers from charts, tables, and visuals inside PDFs. 📉The Problem: Traditional RAGs Visual Blindspot Traditional Retrieval-Augmented Generation (RAG) systems rely on text embeddings to retrieve information from documents.
These steps are encapsulated in a prologue script and are documented step-by-step under the Fine-tuning section. This approach minimizes the complexity of identifying optimal distributed training configurations and provides a simple way to properly size your workloads with the best price-performance architecture on AWS.
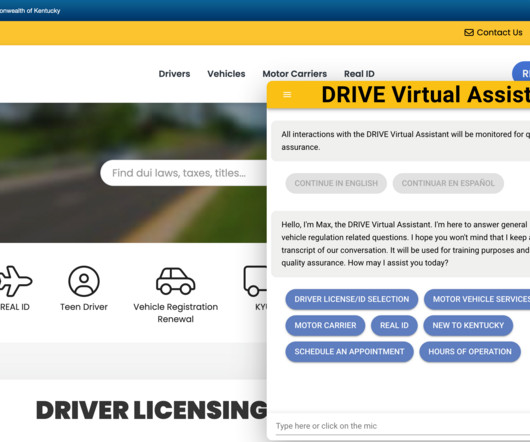
You configure curated answers to frequently asked questions using an integrated content management system that supports rich text and rich voice responses optimized for each channel. You can expand the solution’s knowledge base to include searching existing documents and webpage content using Amazon Kendra.
MBSE brings complex systems to life with visual models, moving away from the paperwork-heavy traditional methods. In other words, MBSE elevates systems engineering by using models.
The following diagram illustrates the complete architecture you have built after completing these steps. Implement training job resiliency with the job auto resume functionality Ray is designed with robust fault tolerance mechanisms to provide resilience in distributed systems where failures are inevitable.
Establish interconnectivity between multiple systems to speed up order delivery A siloed IT systemarchitecture often leads to inefficient business processes, making it difficult to quickly identify risks and resulting in lengthy order delivery cycles.
Use cases over complex data types such as PDF documents gain priority as our customers have the right tools, like Snorkel Flow, to tackle them. Because frequent patching required a lot of our time and didn’t always deliver the results we hoped for, we decided it was better to rebuild the system from the ground up.
Use cases over complex data types such as PDF documents gain priority as our customers have the right tools, like Snorkel Flow, to tackle them. Because frequent patching required a lot of our time and didn’t always deliver the results we hoped for, we decided it was better to rebuild the system from the ground up.
Use cases over complex data types such as PDF documents gain priority as our customers have the right tools, like Snorkel Flow, to tackle them. Because frequent patching required a lot of our time and didn’t always deliver the results we hoped for, we decided it was better to rebuild the system from the ground up.
It involves transforming textual data into numerical form, known as embeddings, representing the semantic meaning of words, sentences, or documents in a high-dimensional vector space. Caption : RAG systemarchitecture. Embedding creation and management Creating and managing embeddings is a key process in LLMOps.
For example, GDPR requires your organization to collect and keep track of metadata about the datasets and to document and report how the resulting model(s) from experiments work. Once you understand your backend architecture, you can also follow domain-driven design principles to build a frontend architecture.
In the meantime, recent Large Language Models (LLMs) excel at understanding scientific documents and generating high-quality code. Inspired by this, we introduce PaperCoder, a multi-agent LLM framework that transforms machine learning papers into functional code repositories.
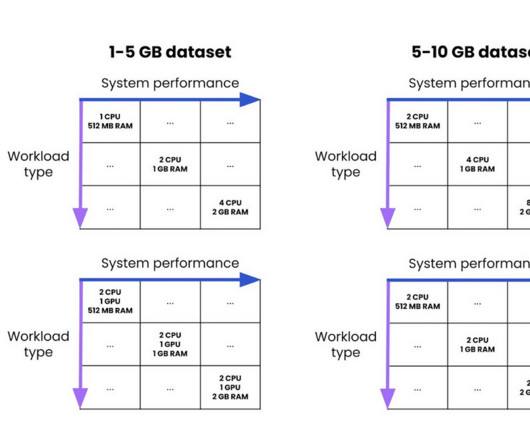
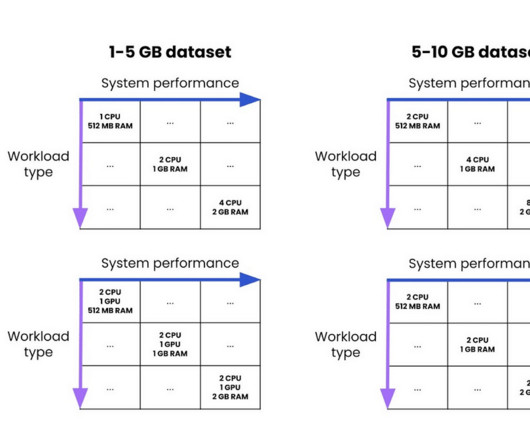
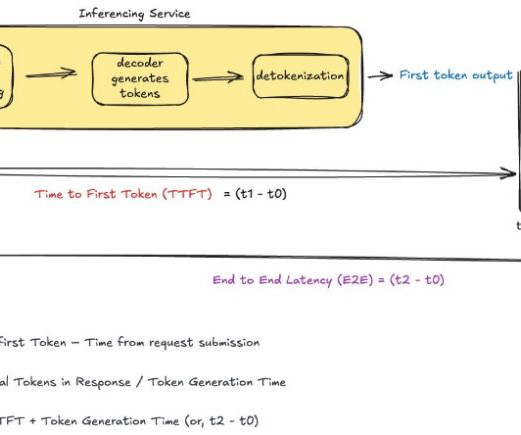
In this section, we explore how different system components and architectural decisions impact overall application responsiveness. Systemarchitecture and end-to-end latency considerations In production environments, overall system latency extends far beyond model inference time.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content