This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Table of Contents Introduction Working with dataset Creating loss dataframe Visualizations Analysis from Heatmap Overall Analysis Conclusion Introduction In this article, I am going to perform ExploratoryDataAnalysis on the Sample Superstore dataset.
ChatGPT can also use Wolfram Language to perform more complex tasks, such as simulating physical systems or training machinelearning models. Deploy machinelearning Models: You can use the plugin to train and deploy machinelearning models.
Performing exploratorydataanalysis to gain insights into the dataset’s structure. Whether you’re a data scientist aiming to deepen your expertise in NLP or a machinelearning engineer interested in domain-specific model fine-tuning, this tutorial will equip you with the tools and insights you need to get started.
Exploratoryanalysis and data storytelling on global forest loss Prompting GPT-4 for exploratorydataanalysis and storytelling are an essential tool to add to your data science toolbox. Click on the download icon to download the file. In the new directory there will be a few files.
Building an End-to-End MachineLearning Project to Reduce Delays in Aggressive Cancer Care. Figure 3: The required python libraries The problem presented to us is a predictive analysis problem which means that we will be heavily involved in finding patterns and predictions rather than seeking recommendations.
On November 30, 2021, we announced the general availability of Amazon SageMaker Canvas , a visual point-and-click interface that enables business analysts to generate highly accurate machinelearning (ML) predictions without having to write a single line of code.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
Because answering these questions requires understanding complex relationships between many different factors—often changing and dynamic—one powerful tool we have at our disposal is machinelearning (ML), which can be deployed to analyze, predict, and solve these complex quantitative problems. The dataset is updated periodically.
Familiarity with basic programming concepts and mathematical principles will significantly enhance your learning experience and help you grasp the complexities of DataAnalysis and MachineLearning. Linear algebra is vital for understanding MachineLearning algorithms and data manipulation.
Summary: Explore a range of top AI and MachineLearning courses that cover fundamental to advanced concepts, offering hands-on projects and industry insights. Introduction Artificial Intelligence (AI) and MachineLearning are revolutionising industries by enabling smarter decision-making and automation.
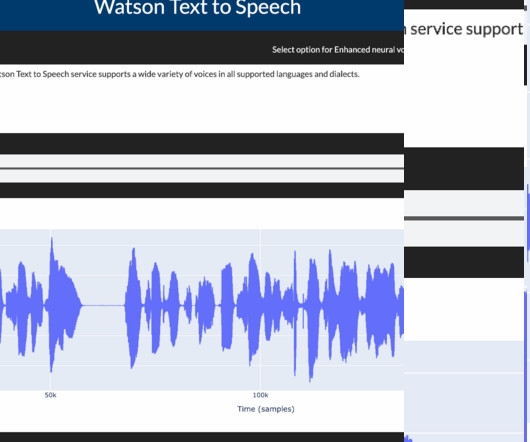
Text to Speech Dash app IBM Watson’s text-to-speech model is built using machinelearning techniques and deep neural networks, trained on large amounts of speech and text data. To learn more about using the s ingle-container TTS service you can see here. Those characters must be replaced in the text.
For access to the data used in this benchmark notebook, sign up for the competition here. This competition invites participants to develop machinelearning models that can automatically and accurately score these audio-based literacy tasks. Let's get started! In [5]: df = labels. shape } " ) df. KG 2 bfaiol.wav 1.0
Through each exercise, you’ll learn important data science skills as well as “best practices” for using pandas. By the end of the tutorial, you’ll be more fluent at using pandas to correctly and efficiently answer your own data science questions. Read the Data The first step is to get the data and load it to memory.
MACHINELEARNING | ARTIFICIAL INTELLIGENCE | PROGRAMMING T2E (stands for text to exam) is a vocabulary exam generator based on the context of where that word is being used in the sentence. Data Collection and Cleaning This step is about preparing the dataset to train, test, and validate our machinelearning on.
Once you have downloaded the dataset, you can upload it to the Watson Studio instance by going to the Assets tab and then dropping the data files as shown below. Add Data You can access the data from the notebook once it has been added to the Watson Studio project. Dataframe head 2.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machinelearning (ML) workflows without writing any code.
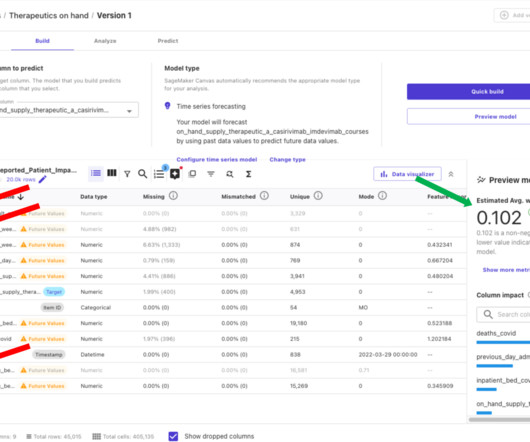
ExploratoryDataAnalysis Next, we will create visualizations to uncover some of the most important information in our data. At the same time, the number of rows decreased slightly to 160,454, a result of duplicate removal.
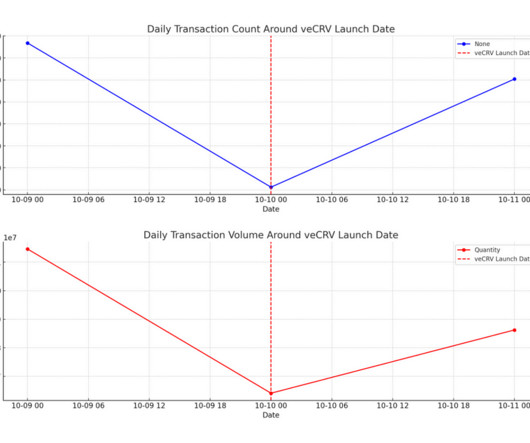
Inside these pages covered a spectrum of topics from ExploratoryDataAnalysis (EDA), to the impact of veCRV on the protocol's governance and machinelearning models. Key findings, indicators, and leading metrics are presented below in corresponding order to the data challenge hosted November — December 2023.
This report took the data set provided in the challenge, as well as external data feeds and alternative sources. In the link above, you will find great detail in data visualization, script explanation, use of neural networks, and several different iterations of predictive analytics for each category of NFL player.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machinelearning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 4 If you went through our previous blog post on Gradient Boosting, it should be fairly easy for you to grasp XGBoost, as XGBoost is heavily based on the original Gradient Boosting algorithm. kaggle/kaggle.json # download the required dataset from kaggle !kaggle
This is a unique opportunity for data people to dive into real-world data and uncover insights that could shape the future of aviation safety, understanding, airline efficiency, and pilots driving planes. These AI/ML models become invaluable tools for aviation operations and safety by harnessing the extensive historical METAR data.
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machinelearning (ML), retail, and data and analytics. You can either download the report or view it online.
Objectives The challenge embraced several dataanalysis dimensions: from data cleaning and exploratorydataanalysis (EDA) to insightful data visualization and predictive modeling.
In this article, we will explore the essential steps involved in training LLMs, including data preparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 2 In the previous blog post of this series, we briefly covered concepts like decision trees and gradient boosting, before touching up on the concept of XGBoost. . Download the code! Looking for the source code to this post?
Learn NLP data processing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet MachineLearning Platform Photo by Stephen Phillips — Hostreviews.co.uk Many data we analyze as data scientists consist of a corpus of human-readable text.
Source: Author MachineLearning Visualization is the art and science of representing machinelearning models, data, and their relationships through graphical or interactive means. Visualization is crucial to any machinelearning project to understand complex data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content