This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Table of Contents Introduction Working with dataset Creating loss dataframe Visualizations Analysis from Heatmap Overall Analysis Conclusion Introduction In this article, I am going to perform ExploratoryDataAnalysis on the Sample Superstore dataset.
This means that you can use natural language prompts to perform advanced dataanalysis tasks, generate visualizations, and train machine learning models without the need for complex coding knowledge. Code Interpreter ChatGPT Code Interpreter is a part of ChatGPT that allows you to run Python code in a live working environment.
In the increasingly competitive world, understanding the data and taking quicker actions based on that help create differentiation for the organization to stay ahead! It is used to discover trends [2], patterns, relationships, and anomalies in data, and can help inform the development of more complex models [3].
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. in 2022, according to the PYPL Index.
ExploratoryDataAnalysis on Stock Market Data Photo by Lukas Blazek on Unsplash ExploratoryDataAnalysis (EDA) is a crucial step in data science projects. It helps in understanding the underlying patterns and relationships in the data. The dataset can be downloaded from Kaggle.
Figure 3: The required python libraries The problem presented to us is a predictive analysis problem which means that we will be heavily involved in finding patterns and predictions rather than seeking recommendations. One important stage of any dataanalysis/science project is EDA. Figure 5: Code Magic!
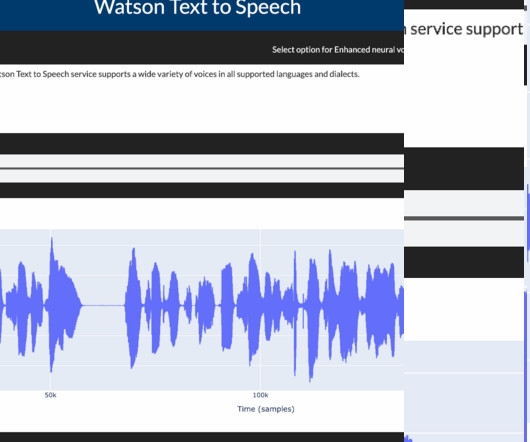
Data Processing and EDA (ExploratoryDataAnalysis) Speech synthesis services require that the data be in a JSON format. To access this service, you can use the Python requests library. Save speech data This audio output can be printed and played in a Python Jupyter Notebook.
ExploratoryDataAnalysis Next, we will create visualizations to uncover some of the most important information in our data. With that in mind, hopefully this perspective can also add fresh insights and improve the robustness of existing models.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
For access to the data used in this benchmark notebook, sign up for the competition here. KG 2 bfaiol.wav nonword_repetition chav KG 3 ktvyww.wav sentence_repetition ring the bell on the desk to get her attention 2 4 htfbnp.wav blending kite KG We'll join these datasets together to help with our exploratorydataanalysis.
Explore your Snowflake tables in SageMaker Data Wrangler, create a ML dataset, and perform feature engineering. Train and test the models using SageMaker Data Wrangler and SageMaker Autopilot. Use a Python notebook to invoke the launched real-time inference endpoint. Basic knowledge of Python, Jupyter notebooks, and ML.
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 4 If you went through our previous blog post on Gradient Boosting, it should be fairly easy for you to grasp XGBoost, as XGBoost is heavily based on the original Gradient Boosting algorithm. kaggle/kaggle.json # download the required dataset from kaggle !kaggle
This is a unique opportunity for data people to dive into real-world data and uncover insights that could shape the future of aviation safety, understanding, airline efficiency, and pilots driving planes. You can download the dataset directly through Desights.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 3: The technical section for the project where Python and pgAdmin4 will be used. Section 4: Reporting data for the project insights. Figure 6: Project’s Dashboard 3. Windows NT 10.0;
Course Content: Basics of AI Applications and transformative impact of AI Ethical issues in AI Hands-on projects and expert insights Machine Learning A-Z Course by Udemy This course covers the full spectrum of Machine Learning, from basic concepts to advanced techniques, using Python and R. Hands-on coding exercises in Python and R.
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 2 In the previous blog post of this series, we briefly covered concepts like decision trees and gradient boosting, before touching up on the concept of XGBoost. Download the code! Looking for the source code to this post?
But I have to say that this data is of great quality because we already converted it from messy data into the Python dictionary format that matches our type of work. ExploratoryDataAnalysis This is one of the fun parts because we get to look into and analyze what’s inside the data that we have collected and cleaned.
Before building our model, we will also see how we can visualize this data with Kangas as part of exploratorydataanalysis (EDA). Getting started with the NLTK library NLTK offers excellent tools for developing Python programs that leverage natural language data.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratorydataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
In this article, you will learn various tools and techniques to visualize different models along with their Python implementation. It is time to learn about some crucial model visualization tools with Python implementation. Moreover, You can download the chart or list of values of any metric you need from Neptune dashboard.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content