This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Jump Right To The Downloads Section Introduction to Approximate NearestNeighbor Search In high-dimensional data, finding the nearestneighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machinelearning.
Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. To upload the dataset Download the dataset : Go to the Shoe Dataset page on Kaggle.com and download the dataset file (350.79MB) that contains the images.
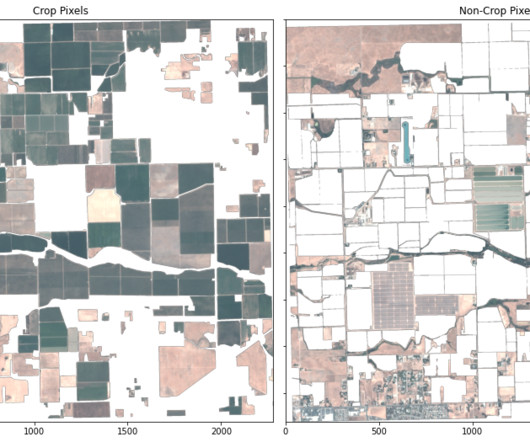
In this post, we illustrate how to use a segmentation machinelearning (ML) model to identify crop and non-crop regions in an image. In this analysis, we use a K-nearestneighbors (KNN) model to conduct crop segmentation, and we compare these results with ground truth imagery on an agricultural region.
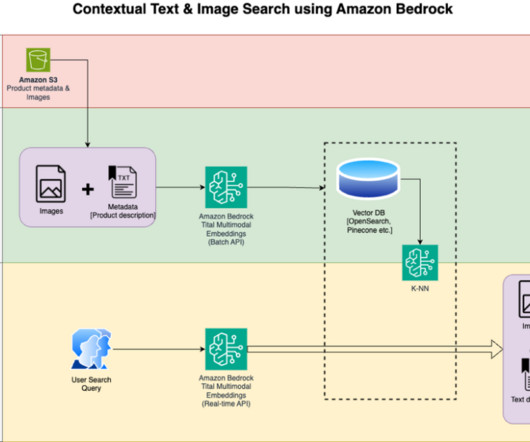
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. You then display the top similar results.
In today’s blog, we will see some very interesting Python MachineLearning projects with source code. This list will consist of Machinelearning projects, Deep Learning Projects, Computer Vision Projects , and all other types of interesting projects with source codes also provided.
Machinelearning techniques can help you discover such images. “ The previous post discussed how you can use Amazon machinelearning (ML) services to help you find the best images to be placed along an article or TV synopsis without typing in keywords.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machinelearning (ML). The following diagram illustrates the complete architecture implemented as part of this series.
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. This notebook will download a publicly available slide deck , convert each slide into the JPG file format, and upload these to the S3 bucket. We run these notebooks one by one. I need numbers."
We perform a k-nearestneighbor (k=1) search to retrieve the most relevant embedding matching the user query. Setting k=1 retrieves the most relevant slide to the user question. In this notebook, we download the LLaVA-v1.5-7B An OpenSearch vector search is performed using these embeddings. The model.tar.gz
machinelearning, statistics, probability, and algebra) are used to achieve this. machinelearning, statistics, probability, and algebra) are employed to recommend our popular daily applications. This is where machinelearning, statistics, and algebra come into play. These engines utilize user data (e.g.,
This lesson is the last in a 2-part series on Mastering Approximate NearestNeighbor Search : Implementing Approximate NearestNeighbor Search with KD-Trees Approximate NearestNeighbor with Locality Sensitive Hashing (LSH) (this tutorial) To learn how to implement LSH for approximate nearestneighbor search, just keep reading.
It is a library for array manipulation that has been downloaded hundreds of times per month and stands at over 25,000 stars on GitHub. What makes it popular is that it is used in a wide variety of fields, including data science, machinelearning, and computational physics. What’s next for me and these top Python libraries?
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machinelearning (ML) models. The first step is to download the pre-trained model weighting file, put it into a model.tar.gz You can use CLIP with Amazon SageMaker to perform encoding.
Run the following command on the terminal to download the sample code from Github: git clone [link] Generate sample posts and compute multimodal embeddings In the code repository, we provide some sample product images (bag, car, perfume, and candle) that were created using the Amazon Titan Image Generator model. Choose Open JupyterLab.
Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? For instance, if a user who typically accesses the network during business hours suddenly logs in at midnight and starts downloading large amounts of data, this behavior would be considered anomalous.
Create an OpenSearch model When you work with machinelearning (ML) models, in OpenSearch, you use OpenSearchs ml-commons plugin to create a model. Yaliang Wu is a Software Engineering Manager at AWS, focusing on OpenSearch projects, machinelearning, and generative AI applications.
These samples can provide a good basis for machinelearning , which can determine (with some probability) the type of unknown files using a model built on the different distributions. To implement our automated download system, we used Selenium in Python to control the browser using a Firefox driver.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content