This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To upload the dataset Download the dataset : Go to the Shoe Dataset page on Kaggle.com and download the dataset file (350.79MB) that contains the images. To search against the database, you can use a vector search, which is performed using the k-nearestneighbors (k-NN) algorithm.
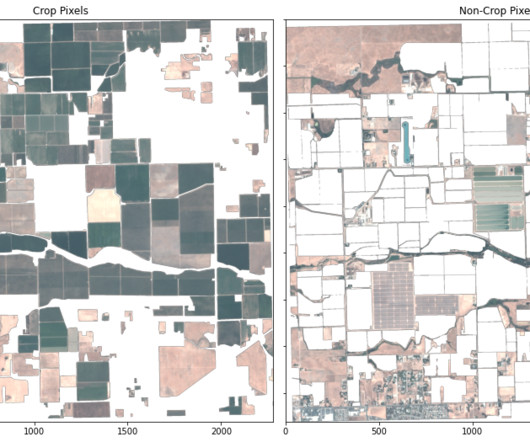
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
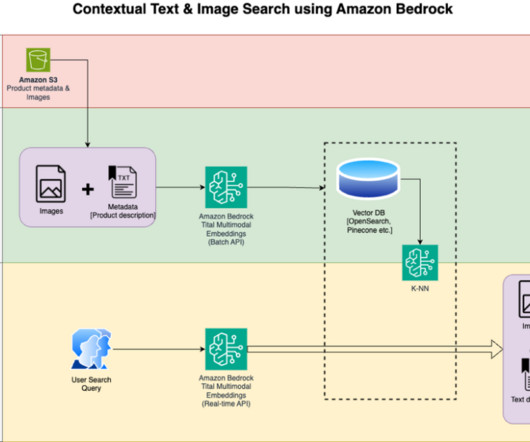
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. You then display the top similar results.
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. This notebook will download a publicly available slide deck , convert each slide into the JPG file format, and upload these to the S3 bucket. We run these notebooks one by one. I need numbers."
We perform a k-nearestneighbor (k=1) search to retrieve the most relevant embedding matching the user query. Setting k=1 retrieves the most relevant slide to the user question. In this notebook, we download the LLaVA-v1.5-7B As per the AI/ML flywheel, what do the AWS AI/ML services provide?
The previous post discussed how you can use Amazon machine learning (ML) services to help you find the best images to be placed along an article or TV synopsis without typing in keywords. Amazon Rekognition automatically recognizes tens of thousands of well-known personalities in images and videos using ML.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. Matthew Rhodes is a Data Scientist I working in the Amazon ML Solutions Lab. About the Authors.
For more information, see Creating connectors for third-party ML platforms. Create an OpenSearch model When you work with machine learning (ML) models, in OpenSearch, you use OpenSearchs ml-commons plugin to create a model. You created an OpenSearch ML model group and model that you can use to create ingest and search pipelines.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. The first step is to download the pre-trained model weighting file, put it into a model.tar.gz You can use CLIP with Amazon SageMaker to perform encoding. file, and upload it to an S3 bucket.
It is a library for array manipulation that has been downloaded hundreds of times per month and stands at over 25,000 stars on GitHub. PyTorch This essential library is an open-source ML framework capable of speeding up research prototyping, allowing companies to enter the production deployment phase.
Run the following command on the terminal to download the sample code from Github: git clone [link] Generate sample posts and compute multimodal embeddings In the code repository, we provide some sample product images (bag, car, perfume, and candle) that were created using the Amazon Titan Image Generator model. Choose Open JupyterLab.
It can also be thought of as the ‘Hello World of ML world. How to perform Face Recognition using KNN In this blog, we will see how we can perform Face Recognition using KNN (K-NearestNeighbors Algorithm) and Haar cascades. So, In this blog, we will see how to implement it.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content