This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
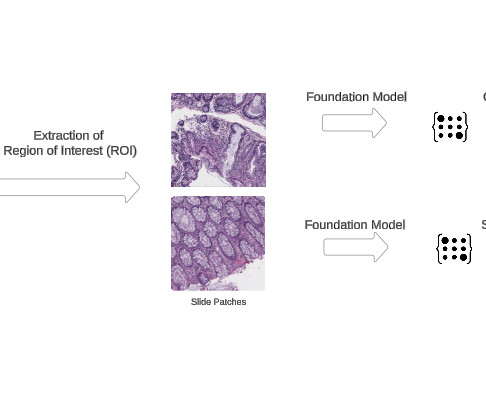
These models are trained using self-supervisedlearning algorithms on expansive datasets, enabling them to capture a comprehensive repertoire of visual representations and patterns inherent within pathology images. script that automatically downloads and organizes the data in your EFS storage.
As a senior data scientist, I often encounter aspiring data scientists eager to learn about machine learning (ML). In this comprehensive guide, I will demystify machine learning, breaking it down into digestible concepts for beginners. The goal is to learn a mapping between the inputs and the corresponding outputs.
We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Download the dataset Download the email_dataset.csv from GitHub and upload the file to the S3 bucket. Set the learning mode hyperparameter to supervised. Prepare the data for the model.
It is a supervisedlearning methodology that predicts if a piece of text belongs to one category or the other. As a machine learning engineer, you start with a labeled data set that has vast amounts of text that have already been categorized. plot(history) Make sure you log the training loss and accuracy metrics to Comet ML.
Amazon SageMaker JumpStart provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning.
The advancement of technology in large language models (LLMs), machine learning (ML), and data science can truly transform industries through insights and predictions. Just click this button and fill out the form to download it. Solutions Looking for Problems Many ML projects are spawned based on external inspiration.
And that’s the power of self-supervisedlearning. But desert, ocean, desert, in this way, I think that’s what the power of self-supervisedlearning is. It’s essentially self -supervisedlearning. Let’s say when we started, it turns out that downloading data from NASA is work.
And that’s the power of self-supervisedlearning. But desert, ocean, desert, in this way, I think that’s what the power of self-supervisedlearning is. It’s essentially self -supervisedlearning. Let’s say when we started, it turns out that downloading data from NASA is work.
Amazon SageMaker provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning.
Creating high-performance machine learning (ML) solutions relies on exploring and optimizing training parameters, also known as hyperparameters. We can revise the hyperparameters and their value ranges based on what we learned and therefore turn this optimization effort into a conversation. We use a Random Forest from SkLearn.
Established in 1987 at the University of California, Irvine, it has become a global go-to resource for ML practitioners and researchers. The global Machine Learning market continues to expand. Datasets are categorised by learning type and domain for easy access. Users can download datasets in formats like CSV and ARFF.
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). The following are a few example RGB images and their labels. The dataset has a size of about 109 GB.
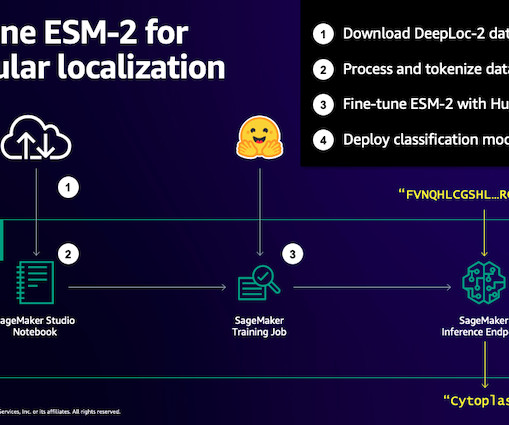
Similarly, pLMs are pre-trained on large protein sequence databases using unlabeled, self-supervisedlearning. We start by downloading a public dataset using Amazon SageMaker Studio. You can also find more examples of using machine learning to predict protein properties in the Awesome Protein Analysis on AWS GitHub repository.
Machine Learning Basics Machine learning (ML) enables AI agents to learn patterns from data without explicit programming. There are three main types: SupervisedLearning: Training a model with labeled data. Unsupervised Learning: Finding hidden structures in unlabeled data.
To get started, download the Anaconda installer from the official Anaconda website and follow the installation instructions for your operating system. Machine Learning with Python Machine Learning is a vital component of Data Science, enabling systems to learn from data and make predictions.
Machine Learning (ML) is a subset of AI that involves using statistical techniques to enable machines to improve their performance on tasks through experience. On the other hand, ML focuses specifically on developing algorithms that allow machines to learn and make predictions or decisions based on data.
That’s why we’re pleased to introduce Prodigy , a downloadable tool for radically efficient machine teaching. You’ll collect more user actions, giving you lots of smaller pieces to learn from, and a much tighter feedback loop between the human and the model. What’s not good is the current technology for creating the examples.
Limited availability of labeled datasets: In some domains, there is a scarcity of datasets with fine-grained annotations, making it difficult to train segmentation networks using supervisedlearning algorithms. kaggle datasets download haziqasajid5122/yolov8-finetuning-dataset-ducks !unzip
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Kuba Cieślik, founder and AI Engineer at tuul.ai , about building visual search engines.
The ability to automate this process using machine learning (ML) techniques allows healthcare professionals to more quickly diagnose certain cancers, coronary diseases, and ophthalmologic conditions. This user-friendly approach eliminates the steep learning curve associated with ML, which frees up clinicians to focus on their patients.
Amazon SageMaker Canvas is a no-code workspace that enables analysts and citizen data scientists to generate accurate machine learning (ML) predictions for their business needs. Download the classic Titanic dataset to your local computer. This flexibility can provide more robust and insightful model development.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content