This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
app downloads, DeepSeek is growing in popularity with each passing hour. DeepSeek AI is an advanced AI genomics platform that allows experts to solve complex problems using cutting-edge deep learning, neural networks, and naturallanguageprocessing (NLP). With numbers estimating 46 million users and 2.6M
Source: Author The field of naturallanguageprocessing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce naturallanguage, NLP opens up a world of research and application possibilities.
This ability to understand long-range dependencies helps transformers better understand the context of words and achieve superior performance in naturallanguageprocessing tasks. As I write this, the bert-base-uncasedmodel on HuggingFace has been downloaded over 53 million times in the last month alone!
Photo by Brooks Leibee on Unsplash Introduction Naturallanguageprocessing (NLP) is the field that gives computers the ability to recognize human languages, and it connects humans with computers. SpaCy is a free, open-source library written in Python for advanced NaturalLanguageProcessing.
The integration of modern naturallanguageprocessing (NLP) and LLM technologies enhances metadata accuracy, enabling more precise search functionality and streamlined document management. When processing is triggered, endpoints are automatically initialized and model artifacts are downloaded from Amazon S3.
Learn NLP data processing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk on Unsplash At its core, the discipline of NaturalLanguageProcessing (NLP) tries to make the human language “palatable” to computers.
This cutting-edge tool integrates AI technologies such as NaturalLanguageProcessing (NLP), Machine Learning (ML), and Computer Vision (CV) to provide an unparalleled video creation experience. Simply type in your text, add images or videos, and choose a template.
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts. features['label'].namesnum_labels
It has also risen as a dominant player in the LLM space, leading the changes within the landscape of naturallanguageprocessing and AI-driven solutions. The company’s latest achievement in this domain is PaLM 2, an advanced language model that excels in various complex tasks. The MPT-7B version has garnered over 3.3
Naturallanguageprocessing (NLP) and deep learning are used by Eightify AI to analyze the audio and video of any YouTube video and extract the most crucial details. The summary is subsequently produced using naturallanguage generation (NLG) to convey the main points of the movie in a comprehensible and understandable manner.
This code utilizes the OpenAI language model for naturallanguageprocessing, FAISS database for efficient similarity search, PyPDF2 for reading PDF files, and Streamlit for creating a web application interface. Text Splitting Using a Text Splitter can also help improve the results from vector store searches, as eg.
Aleph Alpha is Europe’s answer to global AI advancements, aiming to establish a pioneering presence in artificial intelligence ( Image credit ) Aleph Alpha stands tall on the foundation of pioneering research, setting its sights on the frontiers of naturallanguageprocessing, computer vision, and machine learning.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning algorithms. You can download Pegasus using pip with simple instructions.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning. You can download Pegasus using pip with simple instructions.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning. You can download Pegasus using pip with simple instructions.
Can machines understand human language? These questions are addressed by the field of NaturalLanguageprocessing, which allows machines to mimic human comprehension and usage of naturallanguage. Last Updated on March 3, 2025 by Editorial Team Author(s): SHARON ZACHARIA Originally published on Towards AI.
Complete the following steps: Download the CloudFormation template and deploy it in the source Region ( us-east-1 ). Download the CloudFormation template to deploy a sample Lambda and CloudWatch log group. For this example, we create a bot named BookHotel in the source Region ( us-east-1 ).
With advancements in NaturalLanguageProcessing (NLP) and the introduction of models like ChatGPT, chatbots have become increasingly popular and powerful tools for automating conversations. In this article, we will explore the process of creating a simple chatbot using Python and NLP techniques.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark. jpg") or doc.endswith(".png"))
Amazon Comprehend is a fully, managed service that uses naturallanguageprocessing (NLP) to extract insights about the content of documents. This file needs to be download and converted to a non-compressed format. You can download an object from the data folder or S3 bucket using the Amazon S3 console.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. Dataset Size and Format The Pile dataset comprises over 800GB of text data, making it one of the largest publicly available datasets for naturallanguageprocessing.
’ If someone wants to use Quivr without any limitations, then they can download it locally on their device. It also helps in generating information and producing more data with the help of the NaturalLanguageProcessing technique. There is a proper procedure for the installation of Quivr.
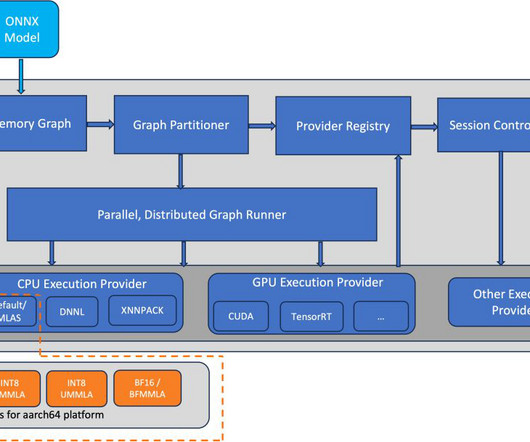
Bfloat16 accelerated SGEMM kernels and int8 MMLA accelerated Quantized GEMM (QGEMM) kernels in ONNX have improved inference performance by up to 65% for fp32 inference and up to 30% for int8 quantized inference for several naturallanguageprocessing (NLP) models on AWS Graviton3-based Amazon Elastic Compute Cloud (Amazon EC2) instances.
This model can be easily accessed and downloaded from GitHub or via a 13.4-gigabyte Some of the common works in each field are mentioned below: NaturalLanguageProcessing (NLP): Machine translation, text summarization, question answering, and sentiment analysis. gigabyte torrent, emphasizing accessibility.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Download the free, unabridged version here.
Researching, collecting data, and processing everything they find can be labor-intensive. Partnered with naturallanguageprocessing (NLP), AI software can pull relevant information from sets of unstructured data. Risk Management. For Non-Tech Users.
Developed by OpenAI, this AI-powered chatbot brings the power of naturallanguageprocessing right to your fingertips. Download the app. ” Download the official application. ChatGPT India made its grand debut in November 2022, marking a significant milestone in the world of artificial intelligence.
This method is generally much faster, with the model typically downloading in just a couple of minutes from Amazon S3. However, this method tends to be slower and can take significantly longer to download the model compared to using Amazon S3. In his free time, he enjoys playing chess and traveling. You can find Pranav on LinkedIn.
In our test environment, we observed 20% throughput improvement and 30% latency reduction across multiple naturallanguageprocessing models. These models are serving intent detection, text clustering, creative insights, text classification, smart budget allocation, and image download services.
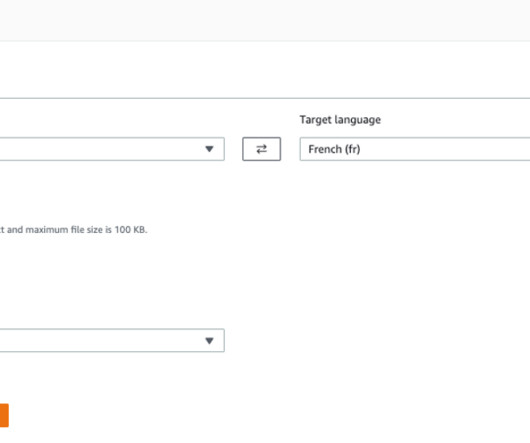
The translated file is automatically saved to your browser’s downloaded folder, usually to Downloads. The target language code will be prefixed to the translated file’s name. For example, if your source file name is lang.txt and your target language is French ( fr ), then the translated file will be named fr.lang.txt.
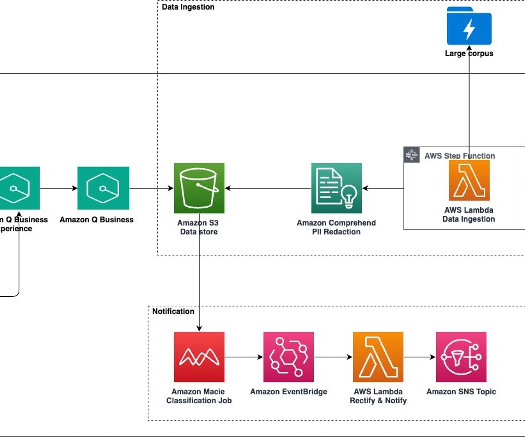
The Process Data Lambda function redacts sensitive data through Amazon Comprehend. Amazon Comprehend provides real-time APIs, such as DetectPiiEntities and DetectEntities , which use naturallanguageprocessing (NLP) machine learning (ML) models to identify text portions for redaction.
Suits the following users: Producers: Bypass creative blocks with unique, one-click tracks and downloadable high-resolution stems. And while you can enjoy limited features as a free user, a subscription unlocks a treasure trove of limitless downloads. The golden ticket of unlimited downloads awaits subscribers.
Question Answering is the task in NaturalLanguageProcessing that involves answering questions posed in naturallanguage. candidate in Machine Learning & NaturalLanguageProcessing at UKP Lab in TU Darmstadt, supervised by Prof. Don’t worry, you’re not alone! Haritz Puerto is a Ph.D.
SageMaker Canvas supports multiple ML modalities and problem types, catering to a wide range of use cases based on data types, such as tabular data (our focus in this post), computer vision, naturallanguageprocessing, and document analysis. To download a copy of this dataset, visit.
Word2vec is useful for various naturallanguageprocessing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Otherwise, it’s sent to the customer’s inbox.
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. indexify server -d (These are two separate lines.)
With this tool, users can create their own comic panels using a variety of pre-trained AI models, including the Meta’s Llama-2 70b language model for naturallanguageprocessing tasks and the widely-used base SDXL 1.0 image generation model.
This diverse gathering represented experts in fields ranging from large language models to astrophysics, medicine, quantum computing, and naturallanguageprocessing. The company’s CUDA parallel programming platform enjoys substantial popularity, with an estimated 40,000 monthly downloads in India.
Here’s the core proposition of Google Gemma AI: Accessibility : Google Gemma AI models can function within various environments, including laptops, workstations, and cloud platforms like Google Cloud Performance : These models demonstrate impressive capabilities across diverse naturallanguageprocessing tasks Responsible AI : Google backs Gemma (..)
We download the documents and store them under a samples folder locally. Generate metadata Using naturallanguageprocessing, you can generate metadata for the paper to aid in searchability. Load data We use example research papers from arXiv to demonstrate the capability outlined here.
Sentiment analysis is a naturallanguageprocessing (NLP) ready-to-use model that analyzes text for sentiments. Download the sample product reviews datasets: sample_product_reviews.csv – Contains 2,000 synthesized product reviews and is used for sentiment analysis and Text Analysis predictions. Set up SageMaker Canvas.
Complete the following steps for manual deployment: Download these assets directly from the GitHub repository. Deploy the infrastructure Although this demonstrates using a CloudFormation template for quick deployment, you can also set up the components manually. The assets (JavaScript and CSS files) are available in our GitHub repository.
First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. For detailed guidance of downloading models and the argument of the preprocessing script, refer to Download LlamaV2 dataset and tokenizer. Next, compile the model: sbatch --nodes 4 compile.slurm./llama_7b.sh
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content