This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Download and configure the 1.78-bit Ollama is a lightweight server for running large language models locally. Install it on an Ubuntu distribution using the following commands: apt-get update apt-get install pciutils -y curl -fsSL [link] | sh Step 2: Download and Run the Model Run the 1.78-bit
No Python environment setup, no manual coding, no switching between tools. While most people associate workflow automation with business processes like email marketing or customer support, n8n can also assist with automating data science tasks that traditionally require custom scripting.
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on June 9, 2025 in Python Image by Author | Ideogram Have you ever spent several hours on repetitive tasks that leave you feeling bored and… unproductive? But you can automate most of this boring stuff with Python. I totally get it. Let’s get started.
Awesome Python: The Ultimate Python Resource List Link: vinta/awesome-python Here is a comprehensive list of Python frameworks, libraries, software, and resources that have been around for at least 10 years and are still actively maintained.
By Iván Palomares Carrascosa , KDnuggets Technical Content Specialist on July 4, 2025 in Python Image by Author | Ideogram Principal component analysis (PCA) is one of the most popular techniques for reducing the dimensionality of high-dimensional data.
By Abid Ali Awan , KDnuggets Assistant Editor on June 17, 2025 in Language Models Image by Author I was first introduced to Modal while participating in a Hugging Face Hackathon, and I was genuinely surprised by how easy it was to use. First, install the Modal Python client. pip install modal Next, set up Modal on your local machine.
py # (Optional) to mark directory as Python package You can leave the __init.py__ file empty, as its main purpose is simply to indicate that this directory should be treated as a Python package. Tools Required(requirements.txt) The necessary libraries required are: PyPDF : A pure Python library to read and write PDF files.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Make Sense of a 10K+ Line GitHub Repos Without Reading the Code No time to read huge GitHub projects?
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter AI Agents in Analytics Workflows: Too Early or Already Behind? Here, SQL stepped in.
Today, we’re exploring an awesome tool called SaveTWT that solves a common challenge: how to download video from Twitter. But we’ll go beyond just the “how-to” we’ll also discover exciting ways machine learning enthusiasts can use these downloaded videos for cool projects.
Photo by Brooks Leibee on Unsplash Introduction Naturallanguageprocessing (NLP) is the field that gives computers the ability to recognize human languages, and it connects humans with computers. One can build NLP projects in different ways, and one of those is by using the Python library S paCy. What is spaCy?
With advancements in NaturalLanguageProcessing (NLP) and the introduction of models like ChatGPT, chatbots have become increasingly popular and powerful tools for automating conversations. In this article, we will explore the process of creating a simple chatbot using Python and NLP techniques.
Harrison Chase’s brainchild, LangChain, is a Python library designed to help you leverage the power of LLMs to build custom NLP applications. PyPDF2: Python library used to read and manipulate PDF files. langchain: a framework for developing applications powered by language models. This is where LangChain comes into play!
Source: Author The field of naturallanguageprocessing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce naturallanguage, NLP opens up a world of research and application possibilities.
Although rapid generative AI advancements are revolutionizing organizational naturallanguageprocessing tasks, developers and data scientists face significant challenges customizing these large models. Familiarity with Python and PyTorch for distributed training and model customization. Wait for the space to be ready.
Business challenge Today, many developers use AI and machine learning (ML) models to tackle a variety of business cases, from smart identification and naturallanguageprocessing (NLP) to AI assistants. Call the SageMaker control plane API using the SageMaker Python SDK for model training. environment. An AWS account.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning algorithms. Pegasus Transformer This is a part of the Transformers library available in Python 3.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning. Pegasus Transformer This is a part of the Transformers library available in Python 3.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning. Pegasus Transformer This is a part of the Transformers library available in Python 3.
Learn NLP data processing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk on Unsplash At its core, the discipline of NaturalLanguageProcessing (NLP) tries to make the human language “palatable” to computers.
You can customize the retry behavior using the AWS SDK for Python (Boto3) Config object. Raj specializes in Machine Learning with applications in Generative AI, NaturalLanguageProcessing, Intelligent Document Processing, and MLOps. The restoration time varies depending on the on-demand fleet size and model size.
As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for naturallanguageprocessing tasks. In this application, we install or update a few libraries for running Llama.cpp in Python. This removes the need to untar large files.
’ If someone wants to use Quivr without any limitations, then they can download it locally on their device. You should also have the official, and the latest version of Python preinstalled on your device. It also helps in generating information and producing more data with the help of the NaturalLanguageProcessing technique.
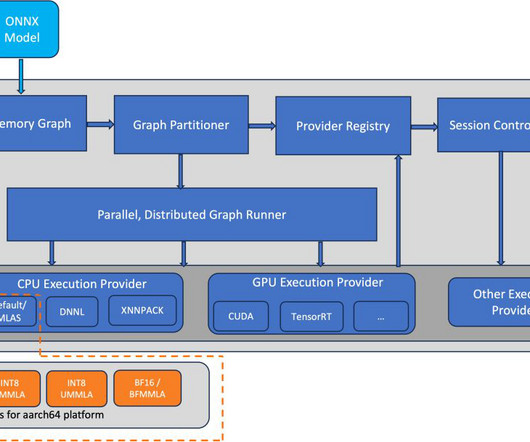
Bfloat16 accelerated SGEMM kernels and int8 MMLA accelerated Quantized GEMM (QGEMM) kernels in ONNX have improved inference performance by up to 65% for fp32 inference and up to 30% for int8 quantized inference for several naturallanguageprocessing (NLP) models on AWS Graviton3-based Amazon Elastic Compute Cloud (Amazon EC2) instances.
How to save a trained model in Python? Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects. For saving the ML models used as a pickle file, you need to use the Pickle module that already comes with the default Python installation. Now let’s see how we can save our model.
The translated file is automatically saved to your browser’s downloaded folder, usually to Downloads. The target language code will be prefixed to the translated file’s name. For example, if your source file name is lang.txt and your target language is French ( fr ), then the translated file will be named fr.lang.txt.
Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to uncover insights and relationships in unstructured data, with no managing infrastructure or ML experience required. Download the SageMaker Data Wrangler flow. Review the SageMaker Data Wrangler flow. Add a destination node.
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. Vision models. You can access the Meta Llama 3.2
the optimizations are available in torch Python wheels and AWS Graviton PyTorch deep learning container (DLC). the optimizations are available in the torch Python wheels and AWS Graviton DLC. the optimizations are available in the torch Python wheel and in AWS Graviton PyTorch DLC. Starting with PyTorch 2.3.1, Instance: c7g.4xl
The following are necessary steps to use ChatGPT APIs in Python: configure your Python environment, get an API key from OpenAI, write Python code to create API calls, and modify the results to fit the needs of your application. Use naturallanguageprocessing to its maximum ability to improve your projects.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Download the free, unabridged version here.
Word2vec is useful for various naturallanguageprocessing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Otherwise, it’s sent to the customer’s inbox.
Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing. This is widely used in NaturalLanguageProcessing (NLP), where it plays a pivotal role in pre-processing unstructured textual data. The below flow diagram illustrates this process.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing with their ability to understand and generate humanlike text. medium instance with a Python 3 (ipykernel) kernel. This blog post is co-written with Moran beladev, Manos Stergiadis, and Ilya Gusev from Booking.com.
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. indexify server -d (These are two separate lines.)
For instance, today’s machine learning tools are pushing the boundaries of naturallanguageprocessing, allowing AI to comprehend complex patterns and languages. PyTorch PyTorch, a Python-based machine learning library, stands out among its peers in the machine learning tools ecosystem.
The success of PyTorch is attributed to its simplicity, first-class Python integration, and imperative style of programming. Jump Right To The Downloads Section What’s New in PyTorch 2.0? is available as a Python pip package. Start by accessing the “Downloads” section of this tutorial to retrieve the source code.
This article will show how to integrate a pre-built sentiment analysis model into a dbt pipeline using Snowpark Python. The result will be a sentiment analysis model that can be queried by end users in the final layer of the data transformation process. What is Snowpark Python? Why Does it Matter? What is Sentiment Analysis?
First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py Next, compile the model: sbatch --nodes 4 compile.slurm./llama_7b.sh
Historically, naturallanguageprocessing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
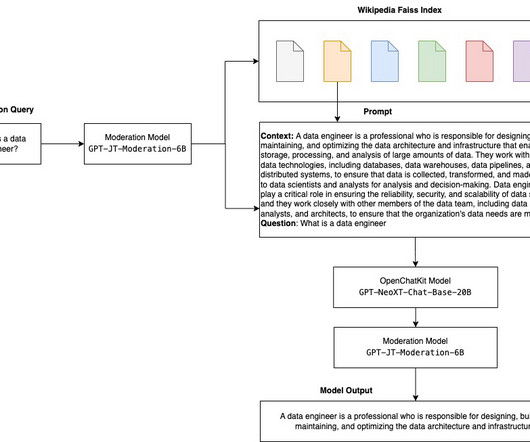
Open-source LLMs provide transparency to the model architecture, training process, and training data, which allows researchers to understand how the model works and identify potential biases and address ethical concerns. Download the OpenChatKit model First, we download the OpenChatKit base model.
AWS and Hugging Face have a partnership that allows a seamless integration through SageMaker with a set of AWS Deep Learning Containers (DLCs) for training and inference in PyTorch or TensorFlow, and Hugging Face estimators and predictors for the SageMaker Python SDK. and requirements.txt files and save it as model.tar.gz : !
Building a multi-hop retrieval is a key challenge in naturallanguageprocessing (NLP) and information retrieval because it requires the system to understand the relationships between different pieces of information and how they contribute to the overall answer. indexify server -d (These are two separate lines.)
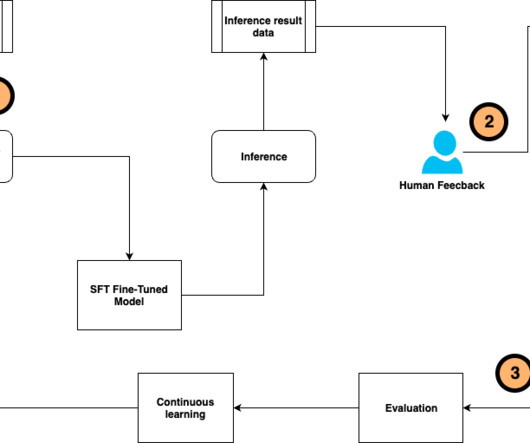
In this post, we introduce the continuous self-instruct fine-tuning framework and its pipeline, and present how to drive the continuous fine-tuning process for a question-answer task as a compound AI system. Examples are similar to Python dictionaries but with added utilities such as the dspy.Prediction as a return value.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content