This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference. Previously, data scientists often found themselves juggling multiple tools to support SQL in their workflow, which hindered productivity.
One of the biggest issues is with managing the tables in their SQL servers. Renaming Tables is Important for SQL Server Management. There are a lot of issues that you have to face when trying to manage an SQL database. In this article, you will see how to rename tables in SQL Server. You can do so like this.
Whether you are experienced or thinking about getting your hands on Apache Spark, this Apache Spark tutorial will guide you through: downloading and running Spark launching Spark’s consoles Spark’s basic architecture Spark’s language APIs DataFrames and SQL Spark’s Toolset What is Apache Spark?
The SQL language, or Structured Query Language, is essential for managing and manipulating relational databases. Introduction to SQL language SQL language stands for Structured Query Language. The primary purpose of the SQL language is to enable easy interaction with a Database Management System (DBMS).
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL.
This entails using SQL servers appropriately. One of the things that you need to understand while running a data-driven company is how to use drop tables with SQL servers. This article shows how you can drop tables in SQL Server using a variety of different methods and applications. Creating a Dummy Database.
In this post, we demonstrate the process of fine-tuning Meta Llama 3 8B on SageMaker to specialize it in the generation of SQL queries (text-to-SQL). Solution overview We walk through the steps of fine-tuning an FM with using SageMaker, and importing and evaluating the fine-tuned FM for SQL query generation using Amazon Bedrock.
Without specialized structured query language (SQL) knowledge or Retrieval Augmented Generation (RAG) expertise, these analysts struggle to combine insights effectively from both sources. Download all three sample data files. Use Amazon Athena SQL queries to provide insights.
To manage queries, a special language called Structured Query Language (SQL) is used. Understand the database dilemma of SQL vs NoSQL MySQL enables storing and processing information, especially crucial when dealing with large amounts of data. What is SQL? Here’s an SQL crash course for a beginner to explore.
To manage queries, a special language called Structured Query Language (SQL) is used. Understand the database dilemma of SQL vs NoSQL MySQL enables storing and processing information, especially crucial when dealing with large amounts of data. What is SQL? Here’s an SQL crash course for a beginner to explore.
Amazon S3 bucket Download the sample file 2020_Sales_Target.pdf in your local environment and upload it to the S3 bucket you created. you might need to edit the connection. Verify the data load by running a select statement: select count (*) from sales.total_sales_data; This should return 7,991 rows.
Data processing and SQL analytics Analyze, prepare, and integrate data for analytics and AI using Amazon Athena, Amazon EMR, AWS Glue, and Amazon Redshift. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. In the next cell, switch the connection type from PySpark to SQL.
This post shows a way to do this using Snowflake as the data source and by downloading the data directly from Snowflake into a SageMaker Training job instance. We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket.
Collecting SQL from various databases is often a challenging and time-consuming process since schemas and syntaxes pretty much always vary across different databases. To solve this challenge, we’ve revamped our phData Toolkit CLI automation tooling to include a SQL collection solution that simplifies collecting SQL across databases.
Install Java and Download Kafka: Install Java on the EC2 instance and download the Kafka binary: 4. Spark provides APIs for SQL queries (Spark SQL), real-time stream processing (Spark Streaming), machine learning (MLlib), and graph processing (GraphX). Next, we run an SQL query to extract the data.
Developed by Microsoft in 1992, ODBC allows applications to execute SQL queries and retrieve results regardless of the underlying database system. This process involves several components: Application: The program that calls ODBC functions and submits SQL statements. Data Source : The actual database being accessed.
For this post, we use a dataset called sql-create-context , which contains samples of natural language instructions, schema definitions and the corresponding SQL query. It contains 78,577 examples of natural language queries, SQL CREATE TABLE statements, and SQL queries answering the question using the CREATE statement as context.
Basic knowledge of a SQL query editor. You can now view the predictions and download them as CSV. A provisioned or serverless Amazon Redshift data warehouse. For this post we’ll use a provisioned Amazon Redshift cluster. A SageMaker domain. A QuickSight account (optional). Deploy the Cloudformation template to your account.
In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database. After uploading, you can set up a regular batch job to process these invoices, extract key information, and save the results in a JSON file. Defaults to "". endswith('.pdf'):
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQL Database connector and an Azure Data Lake Storage Gen2 connector. Azure SQL Database. Many customers rely on Azure SQL Database as a managed, cloud-hosted version of SQL Server. Kristin Adderson. March 30, 2021.
In this blog, you’ll learn all about our Automated Testing tool including how to leverage it to automatically rerun any number of SQL scripts you’ve written in Matillion to ensure your workflows are working properly. It’s available in the Matillion Exchange portal, which you can download for free. We’re happy to help!
In this scenario, we will use the latter type, specifically, the SQL Database Agent. This agent is designed to interact with SQL databases, from describing a table schema, retrieving data from queries, and even recovering from errors. We will download it, and stored on a database for our use.
To that end, I started picking up more responsibilities such as managing databases both SQL and NoSQL. He mentioned that his team was trying to download business reports. The majority of the downloads were failing, or downloads were very slow and this was impacting his team’s efficiency and leading to job dissatisfaction every day.
com:9000, enabled unauthorized users to execute arbitrary SQL queries via the web browser without requiring authentication. It remains unclear if any malicious actors accessed or downloaded the data before the issue was resolved. The database, which was accessible at oauth2callback.deepseek[.]com:9000 com:9000 and dev.deepseek[.]com:9000,
We work backward from the customers business objectives, so I download an annual report from the customer website, upload it in Field Advisor, ask about the key business and tech objectives, and get a lot of valuable insights. I then use Field Advisor to brainstorm ideas on how to best position AWS services.
Download the free, unabridged version here. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data. Download the free whitepaper for the complete guide to setting up automation across each step of your data science project pipelines.
A Trojan horse is malicious code that tricks people into downloading it by appearing to be a useful program or hiding within legitimate software. Injection Attacks In these attacks, hackers inject malicious code into a program or download malware to execute remote commands, enabling them to read or modify a database or change website data.
It is essentially a translator of SQL queries that traditionally return numbers and tables into an effortless visual analysis.” Along with the Desktop/Web Authoring interface, it allows users with little or no experience with SQL to create beautiful visualizations and find actionable insights right away.
To get the most out of the Snowflake Data Cloud , however, requires extensive knowledge of SQL and dedicated IT and data engineering teams. The great benefit to an analytics engineering tool such as KNIME is that it does not require any SQL or coding knowledge (although it can certainly be helpful).
And retrieving data is straightforward with a query language like SQL where you can filter by value, tag, time range, and more. It quickly processes and stores massive datasets with high performance and scalability, and with a little knowledge of SQL you can manage your data much more conveniently than traditional CSV files.
Extract and Transform Steps The extraction is a streaming job, downloading the data from the source APIs and directly persisting it into COS. This job is an orchestrating job that submits SQL statements to the target DB2 Warehouse on the Cloud and waits for their completion. Thus, it has only a minimal footprint.
Download the SageMaker Data Wrangler flow. Download the SageMaker Data Wrangler flow You first need to retrieve the SageMaker Data Wrangler flow file from GitHub and upload it to SageMaker Studio. On GitHub, choose the download icon to download the flow file to your local computer. Add a destination node.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
Queries are translated into SQL statements and executed against the relational database. Cons: Slower query performance compared to MOLAP, complex SQL queries can be required. DOLAP (Desktop OLAP) DOLAP allows users to download a subset of data to their desktop for analysis. Cons: More complex to implement and manage.
So if you are familiar with the Standard SQL queries, you are good to go!! The sample data used in this article can be downloaded from the link below, Fruit and Vegetable Prices How much do fruits and vegetables cost? Athena works with the data stored in S3. We know the data stored in S3 is very cheap and they are highly available.
They can generate code in Python, JavaScript, SQL, and call well-known APIs. It could be an SQL query, that is sent to the tool that the Agent knows will execute SQL queries. This combination of capabilities, which only Big Language Models possess, I would say from GPT-3.5 onwards, is crucial for creating Agents.
The software is easy to use and provides the ability to download different file formats. With that said, a basic understanding of SQL and VB Script can be helpful in leveraging all it has to offer. One of the biggest benefits of Tableau is that the software is free and extremely versatile. Choosing an Analytics Tool.
Explore Guide to SQL Ranking Getting Started with MySQL To begin using MySQL, you first need to install it on your system. Here are the steps to get started: Download MySQL : Visit the official MySQL website and download the MySQL installer suitable for your operating system.
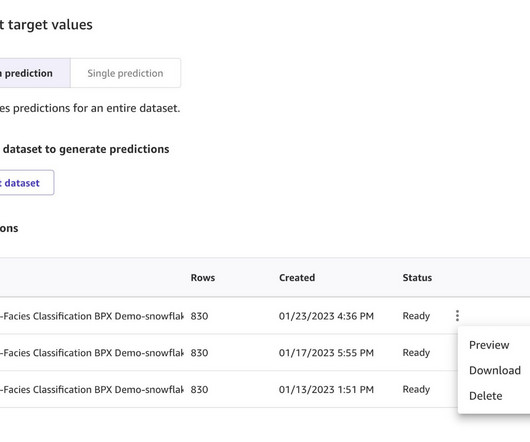
Download the training_data.csv and validation_data_nofacies.csv files to your local machine. It’s important that the data types and the order in which they appear are correct, and align with what is found in the CSV files that we previously downloaded. If you’re happy with the data, you can edit the custom SQL in the data visualizer.
The migration of SSRS (SQL Server Reporting Services) reports to Power BI Service marks a significant shift in data visualization and reporting capabilities. You can download it from the Microsoft website if you don’t already have it. Step 2 Download the latest version of Snowflake ODBC 64 bit driver.
And as the data produced by indexing can become large, we want to make it available over the network through a query interface rather than having to download it. Glean can provide this language-neutral view of the data by defining an abstraction layer in the schema itself the mechanism is similar to SQL views if youre familiar with those.
Users only need to include the respective path in the SQL query to get to work. In addition to supporting standard SQL, Apache Drill lets you keep depending on business intelligence tools you may already use, such as Qlik and Tableau. It allows secure and interactive SQL analytics at the petabyte scale.
Each works through a different way to handle LoRA fine-tuned models as illustrated in the following diagram: First, we download the pre-trained Llama2 model with 7 billion parameters using SageMaker Studio Notebooks. They can also use SageMaker Experiments to download the created charts and share the model evaluation with their stakeholders.
Released in 2022, DagsHub’s Direct Data Access (DDA for short) allows Data Scientists and Machine Learning engineers to stream files from DagsHub repository without needing to download them to their local environment ahead of time. This can prevent lengthy data downloads to the local disks before initiating their mode training.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content