This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. That is, is giving supervision to adjust via.
For instance, the Sentinel Data Access System has recorded 586 PiB in downloads over recent years. From Data Cubes to Embeddings During the development phase in March, participants will pretrain their encoders using self-supervisedlearning methods that underpin neural compression and EO foundation models.
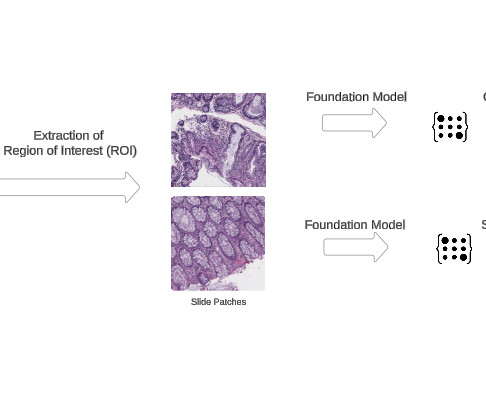
These models are trained using self-supervisedlearning algorithms on expansive datasets, enabling them to capture a comprehensive repertoire of visual representations and patterns inherent within pathology images. script that automatically downloads and organizes the data in your EFS storage.
We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Download the dataset Download the email_dataset.csv from GitHub and upload the file to the S3 bucket. Set the learning mode hyperparameter to supervised. Prepare the data for the model.
Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models. Transfer learning and better annotation tooling are both key to our current plans for spaCy and related projects.
This supervisedlearning algorithm supports transfer learning for all pre-trained models available on Hugging Face. The pre-trained model tarballs have been pre-downloaded from Hugging Face and saved with the appropriate model signature in S3 buckets, such that the training job runs in network isolation.
A demonstration of the RvS policy we learn with just supervisedlearning and a depth-two MLP. It uses no TD learning, advantage reweighting, or Transformers! Offline reinforcement learning (RL) is conventionally approached using value-based methods based on temporal difference (TD) learning.
This is the 3rd lesson in our 4-part series on OAK 101 : Introduction to OpenCV AI Kit (OAK) OAK-D: Understanding and Running Neural Network Inference with DepthAI API Training a Custom Image Classification Network for OAK-D (today’s tutorial) OAK 101: Part 4 To learn how to train an image classification network for OAK-D, just keep reading.
There are three main types of machine learning : supervisedlearning, unsupervised learning, and reinforcement learning. SupervisedLearning In supervisedlearning, the algorithm is trained on a labelled dataset containing input-output pairs. predicting house prices).
Gradient boosting is a supervisedlearning algorithm that attempts to accurately predict a target variable by combining an ensemble of estimates from a set of simpler and weaker models. For CSV, we still recommend splitting up large files into smaller ones to reduce data download time and enable quicker reads. 16 1592 1412.2
Machine Learning Basics Machine learning (ML) enables AI agents to learn patterns from data without explicit programming. There are three main types: SupervisedLearning: Training a model with labeled data. Unsupervised Learning: Finding hidden structures in unlabeled data.
Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? For instance, if a user who typically accesses the network during business hours suddenly logs in at midnight and starts downloading large amounts of data, this behavior would be considered anomalous.
Train an ML model on the preprocessed images, using a supervisedlearning approach to teach the model to distinguish between different skin types. Download the HAM10000 dataset. Use computer vision techniques to preprocess the images and extract relevant to differentiate between healthy and cancerous skin.
Key Takeaways The UCI Machine Learning Repository supports Machine Learning research with diverse datasets. Datasets are categorised by learning type and domain for easy access. Users can download datasets in formats like CSV and ARFF. What is the UCI Machine Learning Repository? CSV, ARFF) to begin the download.
To get started, download the Anaconda installer from the official Anaconda website and follow the installation instructions for your operating system. Machine Learning with Python Machine Learning is a vital component of Data Science, enabling systems to learn from data and make predictions.
It’s a downloadable tool with a powerful command-line interface for training and evaluating models, and a flexible web application for collecting annotations straight from the browser. While the web application was what originally inspired Prodigy, it quickly grew into a more complex “machine teaching” tool.
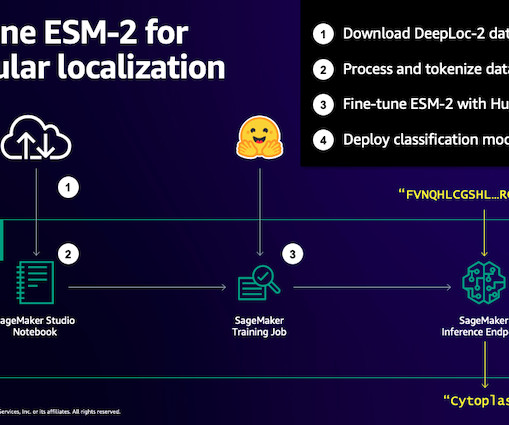
Similarly, pLMs are pre-trained on large protein sequence databases using unlabeled, self-supervisedlearning. We start by downloading a public dataset using Amazon SageMaker Studio. We can adapt them to predict things like the 3D structure of a protein or how it may interact with other molecules.
And that’s the power of self-supervisedlearning. But desert, ocean, desert, in this way, I think that’s what the power of self-supervisedlearning is. It’s essentially self -supervisedlearning. Let’s say when we started, it turns out that downloading data from NASA is work.
And that’s the power of self-supervisedlearning. But desert, ocean, desert, in this way, I think that’s what the power of self-supervisedlearning is. It’s essentially self -supervisedlearning. Let’s say when we started, it turns out that downloading data from NASA is work.
That’s why we’re pleased to introduce Prodigy , a downloadable tool for radically efficient machine teaching. You’ll collect more user actions, giving you lots of smaller pieces to learn from, and a much tighter feedback loop between the human and the model. What’s not good is the current technology for creating the examples.
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). The following are a few example RGB images and their labels. The dataset has a size of about 109 GB.
It is a supervisedlearning methodology that predicts if a piece of text belongs to one category or the other. As a machine learning engineer, you start with a labeled data set that has vast amounts of text that have already been categorized. Create a new R Script and call it train.R.
Just click this button and fill out the form to download it. Is the data labeled for supervisedlearning ? In this guide, we’ll dive into why many AI strategies fail, explore the benefits of building a proper AI strategy, and finally, offer a step-by-step guide to help your business build a successful AI strategy. No problem!
Limited availability of labeled datasets: In some domains, there is a scarcity of datasets with fine-grained annotations, making it difficult to train segmentation networks using supervisedlearning algorithms. kaggle datasets download haziqasajid5122/yolov8-finetuning-dataset-ducks !unzip
Topics include Reinforcement Learning, NLP, and Deep Learning. hours of on-demand video 5 coding exercises 40 articles and 9 downloadable resources Full access on mobile and TV Data Science Job Guarantee Program by Pickl.AI Lifetime access with certification upon completion. Course Content: 42.5
Data science teams that want to further reduce the need for human labeling can employ supervised or semi-supervisedlearning methods to relabel likely-incorrect records based on the patterns set by the high-confidence data points. At the time of this writing, DistillBERT was among the 20 most downloaded models on Hugging Face.
Data science teams that want to further reduce the need for human labeling can employ supervised or semi-supervisedlearning methods to relabel likely-incorrect records based on the patterns set by the high-confidence data points. At the time of this writing, DistillBERT was among the 20 most downloaded models on Hugging Face.
For example, you might want to solve an image recognition task using a supervisedlearning algorithm. Experimenting with the code and using the interactive visualization options greatly enhances your learning experience. Decide which implementation of the algorithm in SageMaker Training you want to use. So, please check it out.
For instance, something from a factory maybe some uses case where there’s a limited amount of data, then I think the current approach, and especially in the growing field of self-supervisedlearning, is very helpful here. You can actually improve embeddings and train embeddings in a self-supervised way.
In HPO mode, SageMaker Canvas supports the following types of machine learning algorithms: Linear learner: A supervisedlearning algorithm that can solve either classification or regression problems. Download the classic Titanic dataset to your local computer. A trial that is performing well is allocated more resources.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content