This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Author(s): Julia Originally published on Towards AI. This member-only story is on us. Upgrade to access all of Medium. Everybody’s talking about AI, but how many of those who claim to be “experts” can actually break down the math behind it? It’s easy to get lost in the buzzwords and headlines, but the truth is — without a solid understanding of the equations and theories driving these technologies, you’re only skimming the surface.
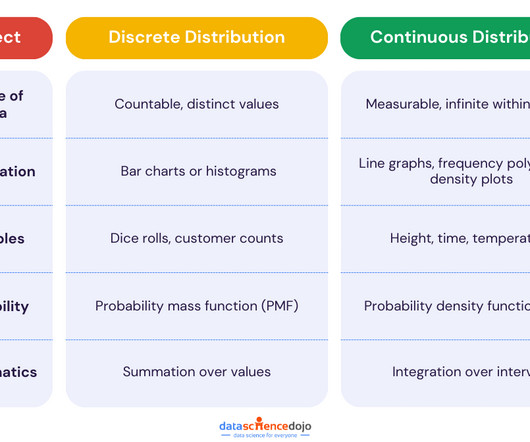
In the realm of data analysis, understanding data distributions is crucial. It is also important to understand the discrete vs continuous data distribution debate to make informed decisions. Whether analyzing customer behavior, tracking weather, or conducting research, understanding your data type and distribution leads to better analysis, accurate predictions, and smarter strategies.
In this contributed article, engineering leader Uma Uppin emphasizes that high-quality data is fundamental to effective AI systems, as poor data quality leads to unreliable and potentially costly model outcomes. Key data attributes like accuracy, completeness, consistency, timeliness, and relevance play crucial roles in shaping AI performance and minimizing ethical risks.
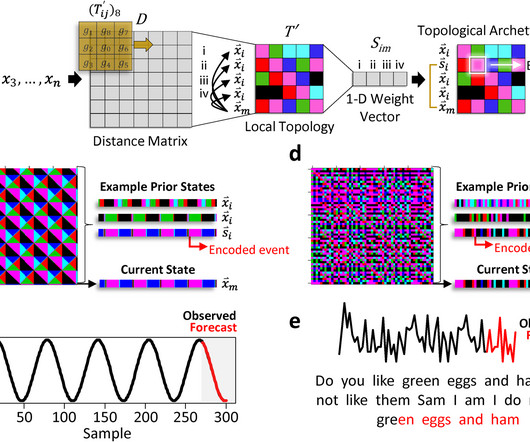
Time-series forecasting is a practical goal in many areas of science and engineering. Common approaches for forecasting future events often rely on highly parameterized or black-box models. However, these are associated with a variety of drawbacks including critical model assumptions, uncertainties in their estimated input hyperparameters, and computational cost.
Document-heavy workflows slow down productivity, bury institutional knowledge, and drain resources. But with the right AI implementation, these inefficiencies become opportunities for transformation. So how do you identify where to start and how to succeed? Learn how to develop a clear, practical roadmap for leveraging AI to streamline processes, automate knowledge work, and unlock real operational gains.
Summary: Autoencoders are powerful neural networks used for deep learning. They compress input data into lower-dimensional representations while preserving essential features. Their applications include dimensionality reduction, feature learning, noise reduction, and generative modelling. Autoencoders enhance performance in downstream tasks and provide robustness against overfitting, making them versatile tools in Machine Learning.
The modern data stack is defined by its ability to handle large datasets, support complex analytical workflows, and scale effortlessly as data and business needs grow. It must integrate seamlessly across data technologies in the stack to execute various workflows—all while maintaining a strong focus on performance and governance. Two key technologies that have become foundational for this type of architecture are the Snowflake AI Data Cloud and Dataiku.
Key Takeaways: Data quality is the top challenge impacting data integrity – cited as such by 64% of organizations. Data trust is impacted by data quality issues, with 67% of organizations saying they don’t completely trust their data used for decision-making. Data quality is the top data integrity priority in 2024, cited by 60% of respondents. The 2025 Outlook: Data Integrity Trends and Insights report is here!
Key Takeaways: Data quality is the top challenge impacting data integrity – cited as such by 64% of organizations. Data trust is impacted by data quality issues, with 67% of organizations saying they don’t completely trust their data used for decision-making. Data quality is the top data integrity priority in 2024, cited by 60% of respondents. The 2025 Outlook: Data Integrity Trends and Insights report is here!
Last Updated on November 11, 2024 by Editorial Team Author(s): Vitaly Kukharenko Originally published on Towards AI. AI hallucinations are a strange and sometimes worrying phenomenon. They happen when an AI, like ChatGPT, generates responses that sound real but are actually wrong or misleading. This issue is especially common in large language models (LLMs), the neural networks that drive these AI tools.
On-device AI and running large language models on smaller devices have been one of the key focus points for AI industry leaders over the past few years. This area of research is among the most critical in AI, with the potential to profoundly influence and reshape the role of AI, computers, and mobile devices in everyday life. This research operates behind the scenes, largely invisible to users, yet mirrors the evolution of computers — from machines that once occupied entire rooms and were access
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services.
The fields of Data Science, Artificial Intelligence (AI), and Large Language Models (LLMs) continue to evolve at an unprecedented pace. To keep up with these rapid developments, it’s crucial to stay informed through reliable and insightful sources. In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
In this feature article, Daniel D. Gutierrez, insideAInews Editor-in-Chief & Resident Data Scientist, explores why mathematics is so integral to data science and machine learning, with a special focus on the areas most crucial for these disciplines, including the foundation needed to understand generative AI.
Image segmentation is another popular computer vision task that has applications with different models. Its usefulness across different industries and fields has allowed for more research and improvements. Maskformer is part of another revolution of image segmentation, using its mask attention mechanism to detect objects that overlap their bounding boxes.
Unity makes strength. This well-known motto perfectly captures the essence of ensemble methods: one of the most powerful machine learning (ML) approaches -with permission from deep neural networks- to effectively address complex problems predicated on complex data, by combining multiple models for addressing one predictive task.
Large language models (LLMs) are powerful tools for generating text, but they are limited by the data they were initially trained on. This means they might struggle to provide specific answers related to unique business processes unless they are further adapted. Fine-tuning is a process used to adapt pre-trained models like Llama, Mistral, or Phi to specialized tasks without the enormous resource demands of training from scratch.
Speaker: Chris Townsend, VP of Product Marketing, Wellspring
Over the past decade, companies have embraced innovation with enthusiasm—Chief Innovation Officers have been hired, and in-house incubators, accelerators, and co-creation labs have been launched. CEOs have spoken with passion about “making everyone an innovator” and the need “to disrupt our own business.” But after years of experimentation, senior leaders are asking: Is this still just an experiment, or are we in it for the long haul?
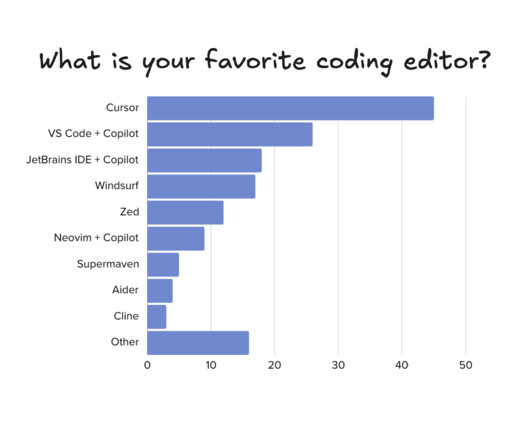
It’s been nearly 6 months since our research into which AI tools software engineers use, in the mini-series, AI tooling for software engineers: reality check. At the time, the most popular tools were ChatGPT for LLMs, and GitHub copilot for IDE-integrated tooling. Then this summer, I saw the Cursor IDE becoming popular around when Anthropic’s Sonnet 3.5 model was released, which has superior code generation compared to ChatGPT.
The Llama model series has been a fascinating journey in the world of AI development. It all started with Meta’s release of the original Llama model, which aimed to democratize access to powerful language models by making them open-source. It allowed researchers and developers to dive deeper into AI without the constraints of closed systems. Fast forward to today, and we have seen significant advancements with the introduction of Llama 3, Llama 3.1, and the latest, Llama 3.2.
In this contributed article, Aayam Bansal explores the increasing reliance on AI in surveillance systems and the profound societal implications that could lead us toward a surveillance state. This piece delves into the ethical risks of AI-powered tools like predictive policing, facial recognition, and social credit systems, while raising the question: Are we willing to trade our personal liberties for the promise of safety?
Machine learning (ML) has become a cornerstone of modern technology, enabling businesses and researchers to make data-driven decisions with greater precision. However, with the vast number of ML models available, choosing the right one for your specific use case can be challenging. Whether you’re working on a classification task, predicting trends, or building a recommendation […] The post How to Choose Best ML Model for your Usecase?
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
TL;DR: Landmines pose a persistent threat and hinder development in over 70 war-affected countries. Humanitarian demining aims to clear contaminated areas, but progress is slow: at the current pace, it will take 1,100 years to fully demine the planet. In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance
The United States remains the world leader in artificial intelligence innovation, according to a newly released Stanford University index. The Stanford Institute for Human-Centered AI’s Global Vibrancy Tool 2024 assesses AI development across 36 countries, ranking the U.S. first, followed by China and the United Kingdom. The index measures various indicators of AI activity, including research output, private investment, and patenting efforts.
Today, we are excited to announce the general availability of Amazon Bedrock Flows (previously known as Prompt Flows). With Bedrock Flows, you can quickly build and execute complex generative AI workflows without writing code. Key benefits include: Simplified generative AI workflow development with an intuitive visual interface. Seamless integration of latest foundation models (FMs), Prompts, Agents, Knowledge Bases, Guardrails, and other AWS services.
As the world becomes more interconnected and data-driven, the demand for real-time applications has never been higher. Artificial intelligence (AI) and natural language processing (NLP) technologies are evolving rapidly to manage live data streams. They power everything from chatbots and predictive analytics to dynamic content creation and personalized recommendations.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
In this contributed article, Ulrik Stig Hansen, President and Co-Founder of Encord, discusses the reality – AI hallucinations aren’t bugs in the system—they’re features of it. No matter how well we build these models, they will hallucinate. Instead of chasing the impossible dream of eliminating hallucinations, our focus should be on rethinking model development to reduce their frequency and implementing additional steps to mitigate the risks they pose.
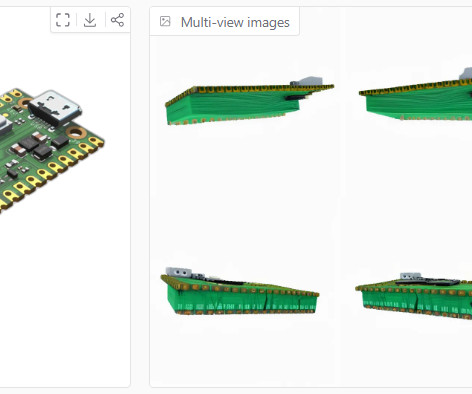
Introducing Hunyuan3D-1.0, a game-changer in the world of 3D asset creation. Imagine generating high-quality 3D models in under 10 seconds—no more long waits or cumbersome processes. This innovative tool combines cutting-edge AI and a two-stage framework to create realistic, multi-view images before transforming them into precise, high-fidelity 3D assets.
Last Updated on November 10, 2024 by Editorial Team Author(s): Tata Ganesh Originally published on Towards AI. Photo by Jaredd Craig on Unsplash In this article, we will review the paper titled “Computation-Efficient Knowledge Distillation via Uncertainty-Aware Mixup” [1], which aims to reduce the computational cost associated with distilling the knowledge of computer vision models.
OpenAI Orion, the company’s next-generation AI model, is hitting performance walls that expose limitations in traditional scaling approaches. Sources familiar with the matter reveal that Orion is delivering smaller performance gains than its predecessors, prompting OpenAI to rethink its development strategy. Early testing reveals plateauing improvements Initial employee testing indicates that OpenAI Orion achieved GPT-4 level performance after completing only 20% of its training.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Robert Califf has made no secret of the Food and Drug Administration’s struggles to regulate generative AI. Large language models and their application to health care “provide a massive example of a technology with novel needs,” FDA commissioner Califf said in an address earlier this year to the Coalition for Health AI. This week, the agency will turn toward that challenge, focusing the first-ever meeting of its Digital Health Advisory Committee on the question of whet
Large language models are expected to grow at a CAGR (Compound Annual Growth Rate) of 33.2% by 2030. It is anticipated that by 2025, 30% of new job postings in technology fields will require proficiency in LLM-related skills. As the influence of LLMs continues to grow, it’s crucial for professionals to upskill and stay ahead in their fields. But how can you quickly gain expertise in LLMs while juggling a full-time job?
In this contributed article, Kunju Kashalikar, Senior Director of Product Management at Pentaho, discusses how to dream big without the risk: three steps to AI-grade data. The industry adage of ‘garbage-in-garbage-out' has never been more applicable than now. Clean, accurate data is the key to winning the AI race - but leaving the starting blocks is the challenge for most.
Generative AI is a newly developed field booming exponentially with job opportunities. Companies are looking for candidates with the necessary technical abilities and real-world experience building AI models. This list of interview questions includes descriptive answer questions, short answer questions, and MCQs that will prepare you well for any generative AI interview.
In the accounting world, staying ahead means embracing the tools that allow you to work smarter, not harder. Outdated processes and disconnected systems can hold your organization back, but the right technologies can help you streamline operations, boost productivity, and improve client delivery. Dive into the strategies and innovations transforming accounting practices.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content