This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database. Create dbt models in dbt Cloud.
Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. Many experts recommend actively participating in discussions, attending virtual events, and connecting with data science professionals to boost your visibility.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed data engine Daft [link] is open-sourced and runs on 800k CPU cores daily.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance data pipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. A three-step ETL framework job should do the trick. Conclusion.
Hosted at one of Mindspace’s coworking locations, the event was a convergence of insightful talks and professional networking. Mindspace , a global coworking and flexible office provider with over 45 locations worldwide, including 13 in Germany, offered a conducive environment for this knowledge-sharing event.
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
In this representation, there is a separate store for events within the speed layer and another store for data loaded during batch processing. It is important to note that in the Lambda architecture, the serving layer can be omitted, allowing batch processing and event streaming to remain separate entities.
In case of security breaches or data anomalies, auditing logs provide a trail of events that led to the incident. Secure Data Integration and ETL Processes : Implement secure data integration practices to ensure that data flowing into your warehouse is not compromised.
An excellent example is how the Oversea-Chinese Banking Corporation (OCBC) designed a successful event-based marketing strategy based on the high amounts of historical customer data they collected. However, to take full advantage of big data’s powerful capabilities, choosing BI and ETL solutions cannot be over-emphasized.
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. It seeks to identify the root causes of specific outcomes or issues.
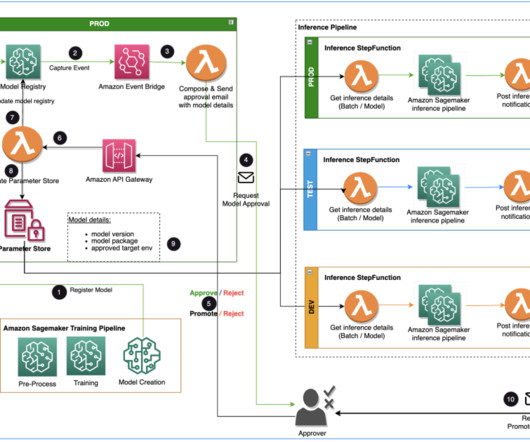
EventBridge monitors status change events to automatically take actions with simple rules. The EventBridge model registration event rule invokes a Lambda function that constructs an email with a link to approve or reject the registered model. At this point, the model status is PendingManualApproval.
This tool is designed to connect various data sources, enterprise applications and perform analytics and ETL processes. This ETL integration software allows you to build integrations anytime and anywhere without requiring any coding. It is one of the powerful big data integration tools which marketing professionals use.
With Snowpipe’s feature of automated data loading, it also leverages event notification for the purpose of cloud storage. Automated Snowpipe utilizes the event notifications for determining the time of arrival of the new files in the cloud storage that is being monitored. Snowpipe enables copying these files into a long queue.
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. our solution would provide the verified re:Invent dates to guide the Amazon Bedrock agents response with additional context.
Data Engineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Career Support Some bootcamps include job placement services like resume assistance, mock interviews, networking events, and partnerships with employers to aid in job placement.
What makes the difference is a smart ETL design capturing the nature of process mining data. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses. Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered.
It can represent a geographical area as a whole or it can represent an event associated with a geographical area. To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings.
Extraction, Transform, Load (ETL). Profisee notices changes in data and assigns events within the systems. It allows users to organise, monitor and schedule ETL processes through the use of Python. The storage and processing of data through a cloud-based system of applications. Master data management. Data transformation.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions.
Event-driven businesses across all industries thrive on real-time data, enabling companies to act on events as they happen rather than after the fact. This is where Apache Flink shines, offering a powerful solution to harness the full potential of an event-driven business model through efficient computing and processing capabilities.
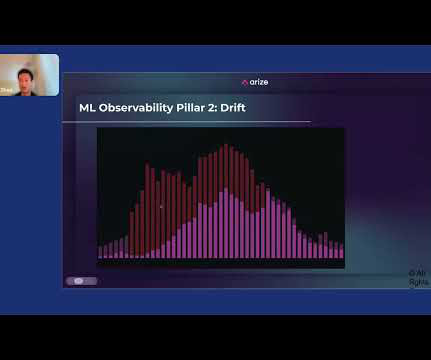
Whenever drift is detected, an event is launched to notify the respective teams to take action or initiate model retraining. Event-driven architecture – The pipelines for model training, model deployment, and model monitoring are well integrated by use Amazon EventBridge , a serverless event bus.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. ETL Design Pattern Here is an example of how the ETL design pattern can be used in a real-world scenario: A healthcare organization wants to analyze patient data to improve patient outcomes and operational efficiency.
Data refinement: Raw data is refined into consumable layers (raw, processed, conformed, and analytical) using a combination of AWS Glue extract, transform, and load (ETL) jobs and EMR jobs. We have numerous jobs that are launched by AWS Lambda functions that in turn are triggered by timers or events.
Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures. It maintains a write-ahead log to ensure that the state of FlowFiles preserved, even in the event of a failure. Provenance Repository : This repository records all provenance events related to FlowFiles. Is Apache NiFi Easy to Use?
TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations. As the users are interacting with TR’s applications, they generate clickstream events, which are published into Amazon Kinesis Data Streams.
Data Warehouses Some key characteristics of data warehouses are as follows: Data Type: Data warehouses primarily store structured data that has undergone ETL (Extract, Transform, Load) processing to conform to a specific schema. Interested in attending an ODSC event? Learn more about our upcoming events here.
You can use OpenScale to monitor these events. Regular evaluation of these factors can help to determine if a model needs retraining to maintain its effectiveness. For example: retrain model if we receive 1000 new records consider certain time periods. For example you are just intrested to use the last 6 months of data.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. Interested in attending an ODSC event? Learn more about our upcoming events here.
The entire process is also achieved much faster, boosting not just general efficiency but an organization’s reaction time to certain events, as well. The popular tools, on the other hand, include Power BI, ETL, IBM Db2, and Teradata. For frameworks and languages, there’s SAS, Python, R, Apache Hadoop and many others.
.” Hence the very first thing to do is to make sure that the data being used is of high quality and that any errors or anomalies are detected and corrected before proceeding with ETL and data sourcing. If you aren’t aware already, let’s introduce the concept of ETL. We primarily used ETL services offered by AWS.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. When the ETL process is complete, the output file is placed back into Amazon S3, ready for ingestion into Amazon Personalize via a dataset import job.
As the name suggests, real-time operating systems (RTOS) handle real-time applications that undertake data and event processing under a strict deadline. When it comes to data integration, RTOS can work with systems that employ data warehousing, API management, and ETL technologies. Moreover, RTOS is built to be scalable and flexible.
A partnership built brick by (Data)bricks By sponsoring this event, Alation further solidifies its strengthened collaboration with Databricks. We’re looking forward to seeing you there! There are countless paths to the lakehouse — but you don’t want to get lost along the way.
Apache Kafka is an open-source event distribution platform. Its use cases range from real-time analytics, fraud detection, messaging, and ETL pipelines. Confluent Kafka is also powered by a user-friendly interface that enables the development of event-driven microservices and other real-time use cases.
Failed Webhooks If webhooks are configured and the webhook event fails, a notification will be sent out. Proactive Monitoring & Faster Troubleshooting : Teams may easily monitor and debug operations by using Slack to receive rapid notifications on pipeline events like task completions and errors.
Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven. Fivetran Overview It is aimed at automating the data movement across the cloud platform of different enterprises, alleviating the pain points of the complexity around the ETL process.
BI developer: A BI developer is responsible for designing and implementing BI solutions, including data warehouses, ETL processes, and reports. Database management: A BI professional should be able to design and manage databases, including data modeling, ETL processes, and data integration.
BI developer: A BI developer is responsible for designing and implementing BI solutions, including data warehouses, ETL processes, and reports. Database management: A BI professional should be able to design and manage databases, including data modeling, ETL processes, and data integration.
Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. This year’s event is free to attend and open to all users of HPCC Systems throughout RELX and the broader open-source community. Interested in attending an ODSC event?
Lets dive into the schedule and key events that will shape this years conference. Check out our first-announced speakers and updateshere! ODSC East 2025: A Sneak Peek at theSchedule Cant wait to see whats in store for ODSC East 2025? We discuss the open-source Guardrails AI and how you can use it to safeguard your AIapps.
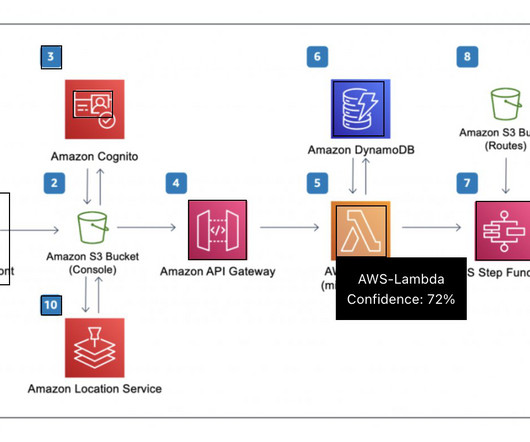
The figure below illustrates a high-level overview of our asynchronous event-driven architecture. Step 3 The S3 bucket is configured to trigger an event when the user uploads the input content. When the asynchronous SageMaker endpoint completes a prediction, an Amazon SNS event is triggered.
You have to make sure that your ETLs are locked down. More Snorkel AI events coming! Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies. You have to check that your production features are the same as your training features.
And that’s when what usually happens, happened: We came for the ML models, we stayed for the ETLs. But even when the ETLs were well thought out, they were a bit “outdated” in their approach. ETL Pipeline ETL Pipeline | Source: Author The pipeline is triggered by Eventbridge , and can be done either manually or by cron.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content