This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database. Create dbt models in dbt Cloud.
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. Familiarity with machine learning, algorithms, and statistical modeling.
Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB. Data Engineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing.
Extraction, Transform, Load (ETL). Redshift is the product for data warehousing, and Athena provides SQL data analytics. Profisee notices changes in data and assigns events within the systems. Dataform is a data transformation platform that is based on SQL. Master data management. Data transformation.
This tool is designed to connect various data sources, enterprise applications and perform analytics and ETL processes. This ETL integration software allows you to build integrations anytime and anywhere without requiring any coding. Moreover, it allows you to explore the data in SQL and view it in any analytics tool efficiently.
Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. The diagram depicts the flow; the key components are detailed below: Data Ingestion: Data is ingested into the system using Attunity data ingestion in Spark SQL. Analytic data is stored in Amazon Redshift.
It can represent a geographical area as a whole or it can represent an event associated with a geographical area. To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings.
Event-driven businesses across all industries thrive on real-time data, enabling companies to act on events as they happen rather than after the fact. This is where Apache Flink shines, offering a powerful solution to harness the full potential of an event-driven business model through efficient computing and processing capabilities.
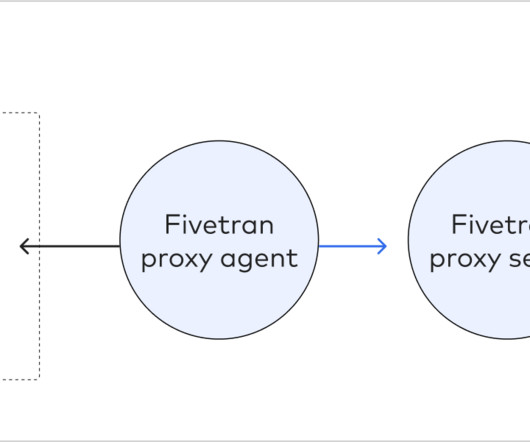
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
Data Warehouses Some key characteristics of data warehouses are as follows: Data Type: Data warehouses primarily store structured data that has undergone ETL (Extract, Transform, Load) processing to conform to a specific schema. Processing: Relational databases are optimized for transactional processing and structured queries using SQL.
The entire process is also achieved much faster, boosting not just general efficiency but an organization’s reaction time to certain events, as well. The popular tools, on the other hand, include Power BI, ETL, IBM Db2, and Teradata. For frameworks and languages, there’s SAS, Python, R, Apache Hadoop and many others.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. As the users are interacting with TR’s applications, they generate clickstream events, which are published into Amazon Kinesis Data Streams.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. Interested in attending an ODSC event? Learn more about our upcoming events here.
Some of the databases supported by Fivetran are: Snowflake Data Cloud (BETA) MySQL PostgreSQL SAP ERP SQL Server Oracle In this blog, we will review how to pull Data from on-premise Systems using Fivetran to a specific target or destination. The most common example of such databases is where events are tracked.
Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven. Enables users to trigger their custom transformations via SQL and dbt. Relational database connectors such as Teradata, Oracle, and Microsoft SQL servers are available.
It also supports ETL (Extract, Transform, Load) processes, making data warehousing and analytics essential. Spark SQL Spark SQL is a module that works with structured and semi-structured data. It allows users to run SQL queries, read data from different sources, and seamlessly integrate with Spark’s core capabilities.
Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. It’s not a widely known programming language like Java, Python, or SQL. ECL sounds compelling, but it is a new programming language and has fewer users than languages like Python or SQL.
BI developer: A BI developer is responsible for designing and implementing BI solutions, including data warehouses, ETL processes, and reports. Database management: A BI professional should be able to design and manage databases, including data modeling, ETL processes, and data integration.
BI developer: A BI developer is responsible for designing and implementing BI solutions, including data warehouses, ETL processes, and reports. Database management: A BI professional should be able to design and manage databases, including data modeling, ETL processes, and data integration.
Apache Airflow Airflow is an open-source ETL software that is very useful when paired with Snowflake. The DAGs can then be scheduled to run at specific intervals or triggered when an event occurs. Airflow uses Directed Acyclic Graphs (DAGs) to represent workflows as tasks with defined dependencies.
For example, you can use alerts to send notifications, capture data, or execute SQL commands when certain events or thresholds are reached in your data. A task is a SQL statement that runs on a schedule or when triggered by other tasks. SQL commands allow users to create, modify, suspend, resume, and drop tasks.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity. Apache Kafka Kafka is a distributed event streaming platform for building real-time data pipelines and streaming applications.
Hyper Supercharge your analytics with in-memory data engine Hyper is Tableau's blazingly fast SQL engine that lets you do fast real-time analytics, interactive exploration, and ETL transformations through Tableau Prep. An ODBC connector lets you access any data source that supports the SQL standard and implements the ODBC API.
The tool converts the templated configuration into a set of SQL commands that are executed against the target Snowflake environment. Instead of manually converting these queries, consider using software built to automate the translation of queries from your legacy systems language to Snowflake’s version, such as phData’s SQL Translation Tool.
In celebration of last week’s dbt Coalesce, their flagship event, I interviewed the D&A team to learn more about how they leverage dbt to support excellence in analytics. Adrian : Fivetran and dbt enable us to easily connect data sources and write SQL transformations to power downstream dashboards and reporting.
Switching contexts across tools like Pandas, SciKit-Learn, SQL databases, and visualization engines creates cognitive burden. For organizations beginning the journey, an incremental approach allows quick wins while building internal expertise over time through online education, community events, andmentors.
This involves selecting appropriate Database Management Systems (DBMS) such as Oracle, SQL Server, or MySQL. the event of data loss, DBAs are responsible for restoring databases from backups efficiently to minimize downtime. Their expertise is crucial in projects involving data extraction, transformation, and loading (ETL) processes.
These tables are called “factless fact tables” or “junction tables” They are used for modelling many-to-many relationships or for capturing timestamps of events. A star schema forms when a fact table combines with its dimension tables. This schema serves as the foundation of dimensional modeling.
Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake. To help you make your choice, here are the ones we consider to be the best. What Are the Best Third-Party Data Ingestion Tools for Snowflake?
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
Understanding the differences between SQL and NoSQL databases is crucial for students. Understanding ETL (Extract, Transform, Load) processes is vital for students. Students should understand the concepts of event-driven architecture and stream processing. Knowledge of RESTful APIs and authentication methods is essential.
Thanks to its various operators, it is integrated with Python, Spark, Bash, SQL, and more. Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines. Flexibility: Airflow was designed with batch workflows in mind; it was not meant for permanently running event-based workflows.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. Apache Kafka Apache Kafka is a distributed event streaming platform for real-time data pipelines and stream processing. Unstructured.io
Modern low-code/no-code ETL tools allow data engineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance.
In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more. Rich Context: Each event carries with it a wealth of contextual information. What is Activity Schema Modeling?
Relational databases use SQL for querying, which can be complex and rigid. Explain The Difference Between MongoDB and SQL Databases. MongoDB is a NoSQL database that stores data in documents, while SQL databases store data in tables with rows and columns. Documents are stored in collections, analogous to SQL database tables.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Python, SQL, and Apache Spark are essential for data engineering workflows. SQL Structured Query Language ( SQL ) is a fundamental skill for data engineers.
Andy Bunn taking a huge jump with his fellow teammates, including Heather Coyle (to Andys right), at phDatas 2025 Kickoff Event in San Antonio. Ingrid Bauer (Middle) poses for a picture with two other colleagues at the 2025 phData Kickoff event. Tepi Hanson speaking at the 2025 phData Kickoff event.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content