Building a Scalable ETL with SQL + Python
KDnuggets
APRIL 21, 2022
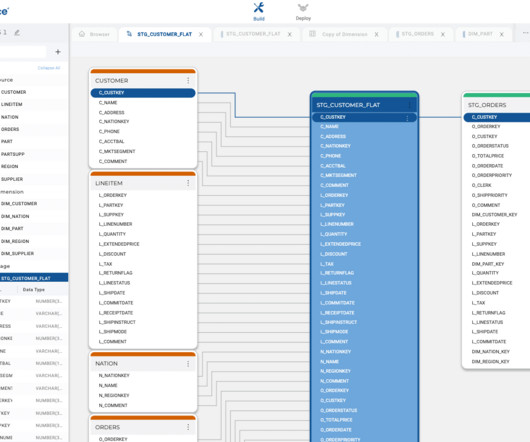
This post will look at building a modular ETL pipeline that transforms data with SQL and visualizes it with Python and R.
 ETL Python SQL
ETL Python SQL 
KDnuggets
APRIL 21, 2022
This post will look at building a modular ETL pipeline that transforms data with SQL and visualizes it with Python and R.

KDnuggets
APRIL 27, 2022
A Brief Introduction to Papers With Code; Machine Learning Books You Need To Read In 2022; Building a Scalable ETL with SQL + Python; 7 Steps to Mastering SQL for Data Science; Top Data Science Projects to Build Your Skills.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Data Science Dojo
OCTOBER 31, 2024
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. Familiarity with machine learning, algorithms, and statistical modeling.

Data Science Blog
SEPTEMBER 19, 2023
This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. using for loops in Python). The following Terraform script will create an Azure Resource Group, a SQL Server, and a SQL Database. So why using IaC for Cloud Data Infrastructures?

AWS Machine Learning Blog
DECEMBER 14, 2023
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The system includes feature engineering, deep learning model architecture design, hyperparameter optimization, and model evaluation, where all modules are run using Python.

AWS Machine Learning Blog
APRIL 16, 2024
They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference. Previously, data scientists often found themselves juggling multiple tools to support SQL in their workflow, which hindered productivity.

Hacker News
NOVEMBER 19, 2024
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)

Expert insights. Personalized for you.








































Let's personalize your content