This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apache Hadoop needs no introduction when it comes to the management of large sophisticated storage spaces, but you probably wouldn’t think of it as the first solution to turn to when you want to run an email marketing campaign. Some groups are turning to Hadoop-based data mining gear as a result.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is Apache Hadoop? What is Apache Spark?
To know more about IBM SPSS Analytic Server [link] IBM SPSS ANALYTIC SERVER enables IBM SPSS Modeler to use big data as a source for predictive modelling. Together they can provide an integrated predictiveanalytics platform, using data from Hadoop distributions and Spark applications.
The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark). such data resources are cleaned, transformed, and analyzed by using tools like Python, R, SQL, and big data technologies such as Hadoop and Spark.
Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Big Data Technologies Enable Data Science at Scale Tools like Hadoop and Spark were developed specifically to handle the challenges of Big Data.
Big data analytics Big data analytics involves processing vast amounts of structured and unstructured data, extracting key insights that drive business decisions. Machine learning Integrating machine learning enhances the accuracy of predictiveanalytics applications, continuously learning from new data inputs.
There are a number of reasons that machine learning, data analytics and Hadoop technology are changing SEO: Machine learning is becoming more widely used in search engine algorithms. One is the evolution of predictiveanalytics. Big data is a very important part of any digital marketing strategy.
Hadoop has also helped considerably with weather forecasting. That means you can now learn about the weather conditions at precise locations, such as residential buildings, airports, farms, construction sites, etc. Combined with IoT, it has propelled the rise of hyperlocal weather forecasting.
In the early days, organizations used a central data warehouse to drive their data analytics. Even today, there are a large number of them using data lakes to drive predictiveanalytics. The Hadoop library enabled distributed processing across all points of data storage. Data Management before the ‘Mesh’.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Having the right data strategy and data architecture is especially important for an organization that plans to use automation and AI for its data analytics.
This section will highlight key tools such as Apache Hadoop, Spark, and various NoSQL databases that facilitate efficient Big Data management. Apache HadoopHadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Analytics tools help convert raw data into actionable insights for businesses. Distributed File Systems: Technologies such as Hadoop Distributed File System (HDFS) distribute data across multiple machines to ensure fault tolerance and scalability.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Analytics tools help convert raw data into actionable insights for businesses. Distributed File Systems: Technologies such as Hadoop Distributed File System (HDFS) distribute data across multiple machines to ensure fault tolerance and scalability.
Read More: Use of AI and Big Data Analytics to Manage Pandemics Overview of Uber’s Data Analytics Strategy Uber’s Data Analytics strategy is multifaceted, focusing on real-time data collection, predictiveanalytics, and Machine Learning. What Technologies Does Uber Use for Data Processing?
Data processing is another skill vital to staying relevant in the analytics field. For frameworks and languages, there’s SAS, Python, R, Apache Hadoop and many others. Professionals adept at this skill will be desirable by corporations, individuals and government offices alike.
Companies that know how to leverage analytics will have the following advantages: They will be able to use predictiveanalytics tools to anticipate future demand of products and services. They are able to utilize Hadoop-based data mining tools to improve their market research capabilities and develop better products.
The emergence of massive data centers with exabytes in the form of transaction records, browsing habits, financial information, and social media activities are hiring software developers to write programs that can help facilitate the analytics process. to rapidly find and fix bugs faster, significantly lowering the software development rates.
Some of the changes include the following: Big data can be used to identify new link building opportunities through complicated Hadoop data-mining tools. Predictiveanalytics tools can be used to identify future changes in Google’s algorithms. Lots of courses are being offered on SEO these days.
There are three main types, each serving a distinct purpose: Descriptive Analytics (Business Intelligence): This focuses on understanding what happened. ” PredictiveAnalytics (Machine Learning): This uses historical data to predict future outcomes. ” or “What are our customer demographics?”
One ride-hailing transportation company uses big data analytics to predict supply and demand, so they can have drivers at the most popular locations in real time. An e-commerce conglomeration uses predictiveanalytics in its recommendation engine. Python is the most common programming language used in machine learning.
It involves using various techniques, such as data mining, Machine Learning, and predictiveanalytics, to solve complex problems and drive business decisions. Big Data Technologies (Hadoop, Spark) Hadoop and Spark are super helpful for managing big data.
Data Analysis At this stage, organizations use various analytical techniques to derive insights from the stored data: Descriptive Analytics: Provides insights into past performance by summarizing historical data. Prescriptive Analytics : Offers recommendations for actions based on predictive models.
According to recent statistics, 56% of healthcare organisations have adopted predictiveanalytics to improve patient outcomes. For example: In finance, predictiveanalytics helps institutions assess risks and identify investment opportunities. In healthcare, patient outcome predictions enable proactive treatment plans.
Root cause analysis is a typical diagnostic analytics task. 3. PredictiveAnalytics Projects: Predictiveanalytics involves using historical data to predict future events or outcomes. It involves deeper analysis and investigation to identify the root causes of problems or successes.
Integration with Big Data Technologies Relational databases are increasingly being integrated with big data tools like Hadoop or Spark for enhanced analytics capabilities. Artificial Intelligence Integration AI technologies are being integrated into RDBMS systems for smarter query optimization and predictiveanalytics capabilities.
It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. Limitations High Cost for Advanced Features: While the basic version is affordable, advanced features like PredictiveAnalytics are more expensive.
Scikit-learn also earns a top spot thanks to its success with predictiveanalytics and general machine learning. Hadoop, though less common in new projects, is still crucial for batch processing and distributed storage in large-scale environments. Kafka remains the go-to for real-time analytics and streaming.
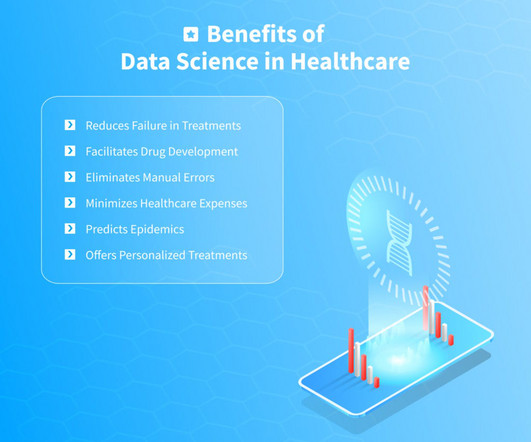
Predicting Diseases Predictiveanalytics utilizes data science in healthcare to forecast the patient’s health condition. Using tools for processing and analyzing genetic data, scientists can create and test new drugs and shine more light on how our genes determine our health.
Ensemble modeling is a powerful approach in predictiveanalytics that leverages the strengths of multiple machine learning models. As computational power increased and large datasets became available, researchers recognized the potential of combining models to improve predictiveanalytics significantly.
Overview of core disciplines Data science encompasses several key disciplines including data engineering, data preparation, and predictiveanalytics. Predictiveanalytics utilizes statistical algorithms and machine learning to forecast future outcomes based on historical data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content