This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In other words, neighbors play a major part in our life. Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. What is KNearestNeighbor? How to get started 1.
Traditional exact nearestneighbor search methods (e.g., brute-force search and k -nearestneighbor (kNN)) work by comparing each query against the whole dataset and provide us the best-case complexity of. These word vectors are trained from Twitter data making them semantically rich in information.
By manipulating the input features of a dataset, we can enhance their quality, extract meaningful information, and improve the performance of predictive models. Based on this information, it determines whether the user made a purchase or not (where zero indicates not purchased, and one indicates purchased).
Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information. Working with vector data is tough because regular databases, which usually handle one piece of information at a time, can’t handle the complexity and large amount of this type of data.
Its discriminative AI capabilities allow it to analyze audio inputs, extract relevant information, and generate appropriate responses, showcasing the power of AI-driven conversational systems in enhancing user experiences and streamlining business operations.
It’s like having a super-powered tool to sort through information and make better sense of the world. By comprehending these technical aspects, you gain a deeper understanding of how regression algorithms unveil the hidden patterns within your data, enabling you to make informed predictions and solve real-world problems.
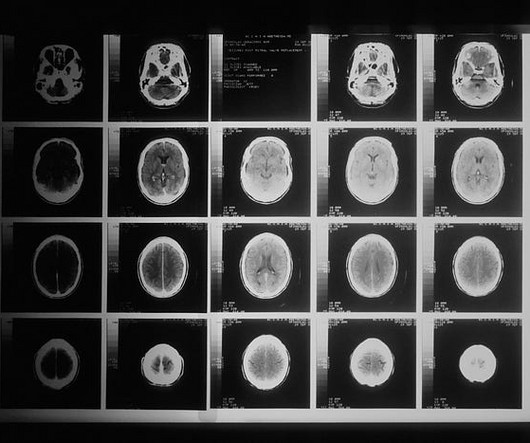
There are various techniques used to obtain information about tumors. Correlation: gives information about how correlated a pixel is to its neighboring pixels. The three weak learner models used for this implementation were k-nearestneighbors, decision trees, and naive Bayes.
The ability to quickly access relevant information is a key differentiator in todays competitive landscape. It supports advanced features such as result highlighting, flexible pagination, and k-nearestneighbor (k-NN) search for vector and semantic search use cases. Also, Cohere Rerank 3.5,
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. Decision trees and K-nearestneighbors (KNN) Both decision trees and KNN play vital roles in classification and prediction. What is data mining?
A sector that is currently being influenced by machine learning is the geospatial sector, through well-crafted algorithms that improve data analysis through mapping techniques such as image classification, object detection, spatial clustering, and predictive modeling, revolutionizing how we understand and interact with geographic information.
Examples include: Classifying species of plants Categorizing images into animals, vehicles, or landscapes Algorithms like Random Forests, Naive Bayes, and K-NearestNeighbors (KNN) are commonly used for multi-class classification. Each instance is assigned to one of several predefined categories.
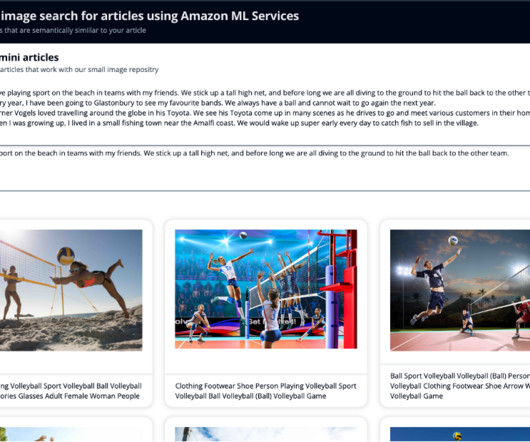
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. For more information on managing credentials securely, see the AWS Boto3 documentation. The closer vectors are to one another in this space, the more similar the information they represent is.
The challenge here is to retrieve the relevant data source to answer the question and correctly extract information from that data source. Use cases we have worked on include: Technical assistance for field engineers – We built a system that aggregates information about a company’s specific products and field expertise.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
Example: Determining whether an email is spam or not based on features like word frequency and sender information. k-NearestNeighbors (k-NN) k-NN is a simple algorithm that classifies new instances based on the majority class among its knearest neighbours in the training dataset.
MongoDB Atlas Vector Search uses a technique called k-nearestneighbors (k-NN) to search for similar vectors. k-NN works by finding the k most similar vectors to a given vector. Refer to Review knnVector Type Limitations for more information about the limitations of the knnVector type.
The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories. Click to learn more about author Kartik Patel. In this article, we will discuss the KNN Classification method of analysis. What Is the KNN Classification Algorithm?
This is the k-nearestneighbor (k-NN) algorithm. In k-NN, you can make assumptions around a data point based on its proximity to other data points. For more information, refer to Create a VPC. You can use the embedding of an article and check the similarity of the article against the preceding embeddings.
Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks. For more information, contact us at info@flotorch.ai. Each provisioned node was r7g.4xlarge, FloTorch used HSNW indexing in OpenSearch Service.
For this post, you use the following: Name, Id, and Urls – The celebrity name, a unique Amazon Rekognition ID, and list of URLs such as the celebrity’s IMDb or Wikipedia link for further information. Using the k-nearestneighbors (k-NN) algorithm, you define how many images to return in your results.
Evaluation allows us to select the top embedding models across various dimensions, potentially considering multiple values for knearestneighbors. Evaluating the Retrieval Pipeline Now that we’ve found the optimal embedding model for our use case, the next step is to evaluate the retrieval pipeline itself.
We shall look at various machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code.
Realizing the impact of these applications can provide enhanced insights to the customers and positively impact the performance efficiency in the organization, with easy information retrieval and automating certain time-consuming tasks. For more information about foundation models, see Getting started with Amazon SageMaker JumpStart.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decision tree.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decision tree.
Adding such extra information should improve the classification compared to the previous method (Principle Label Space Transformation). The prediction is then done using a k-nearestneighbor method within the embedding space. Distance preserving embeddings: The name of this method is straightforward.
Vector search, also known as vector similarity search or nearestneighbor search, is a technique used in data retrieval for RAG applications and information retrieval systems to find items or data points that are similar or closely related to a given query vector. Vector Search is Not Effortless!
Examples of Lazy Learning Algorithms: K-NearestNeighbors (k-NN) : k-NN is a classic Lazy Learning algorithm used for both classification and regression tasks. The algorithm identifies the k-nearestneighbors, where k is a user-defined parameter that is most similar to the new instance.
It combines information from various sources into comprehensive, on-demand summaries available in our CRM or proactively delivered based on upcoming meetings. Account Summaries provides a 360-degree account narrative with customizable sections, showcasing timely and relevant information about customers.
New users may find establishing a user profile vector difficult due to limited information about their interests. Like content-based recommendations, collaborative systems have their limitations: Identifying the -closest users for new users is difficult because of the limited information about their interests.
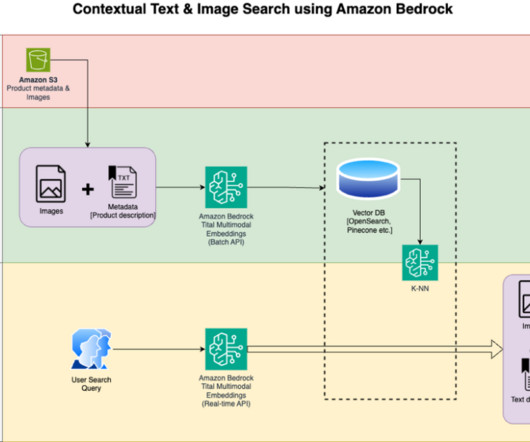
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality.
Do not add any information that is not mentioned in the text below.” The embedding model also has a maximum token input count, therefore summarizing the article is even more important to make sure that you can get as much information captured in the embedding as possible.
The algorithm must balance exploring different arms to gather information about their expected reward, while also exploiting the knowledge it has gained to make decisions that are likely to result in high rewards. bag of words or TF-IDF vectors) and splitting the data into training and testing sets.
Solution overview The solution provides an implementation for answering questions using information contained in text and visual elements of a slide deck. We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. I need numbers. Up to 4x higher throughput.
It could contain information in the form of text, or embedded in graphs, tables, and pictures. Solution overview The solution provides an implementation for answering questions using information contained in the text and visual elements of a slide deck. Setting k=1 retrieves the most relevant slide to the user question.
These word vectors are trained from Twitter data making them semantically rich in information. On Line 28 , we sort the distances and select the top knearestneighbors. Citation Information Puneet Mangla. Approximate NearestNeighbor with Locality Sensitive Hashing (LSH), PyImageSearch , P.
Significantly, the technique allows the model to work independently by discovering its patterns and previously undetected information. It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean. Therefore, it mainly deals with unlabelled data.
Common machine learning algorithms for supervised learning include: K-nearestneighbor (KNN) algorithm : This algorithm is a density-based classifier or regression modeling tool used for anomaly detection. These equations use labeled and unlabeled data to predict future outcomes when only some of the information is known.
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. Embeddings are vector representations of text that capture semantic and contextual information.
This benefits enterprise software development and helps overcome the following challenges: Sparse documentation or information for internal libraries and APIs that forces developers to spend time examining previously written code to replicate usage. For more information and to get started, visit the Amazon CodeWhisperer page.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content