This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Quality Evaluation and Testing : Unlike traditional ML models with clear accuracy metrics, evaluating generative AI requires more sophisticated approaches. Retrieval-Augmented Generation (RAG) Systems RAG addresses one of the biggest limitations of foundation models: their knowledge cutoff dates and lack of domain-specific information.
More On This Topic 7 Python Errors That Are Actually Features Math Myths Busted: What Beginners Actually Need for Data Science Free Courses That Are Actually Free: Data Analytics Edition What I Actually Do As a Data Scientist (in 2024) What Junior ML Engineers Actually Need to Know to Get Hired?
Quick links Paper GitHub Share Copy link × Neural embedding models have become a cornerstone of modern information retrieval (IR). How tall is Mt Everest?”), the goal of IR is to find information relevant to the query from a very large collection of data (e.g., Given a query from a user (e.g., “How
Awesome Machine Learning: The Best ML Libraries Link: josephmisiti/awesome-machine-learning A comprehensive and organized list of machine learning frameworks, libraries, and software across multiple languages. It also includes free machine learning books, courses, blogs, newsletters, and links to local meetups and communities.
The programming language has basically become the gold standard in the data community. If you are already familiar with Python, you often encounter erroneous information whenever you produce incorrect syntax or violate Pythons rules. Cornellius writes on a variety of AI and machine learning topics.
Although some of these evaluation challenges also appear in shorter contexts, long-context evaluation amplifies issues such as: Information overload: Irrelevant details in large documents obscure relevant facts, making it harder for retrievers and models to locate the right evidence for the answer. A study by Xu et al.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (NaturalLanguageProcessing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
Step 1: Cover the Fundamentals You can skip this step if you already know the basics of programming, machine learning, and naturallanguageprocessing. Step 2: Understand Core Architectures Behind Large Language Models Large language models rely on various architectures, with transformers being the most prominent foundation.
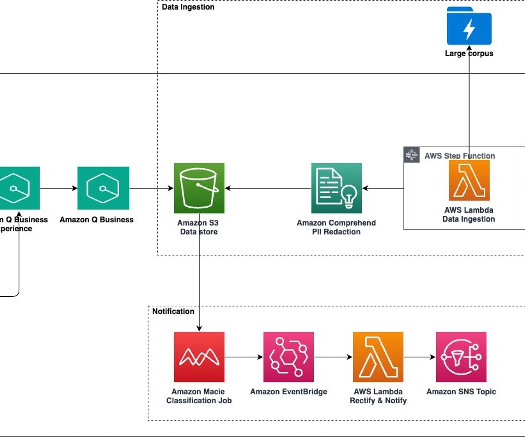
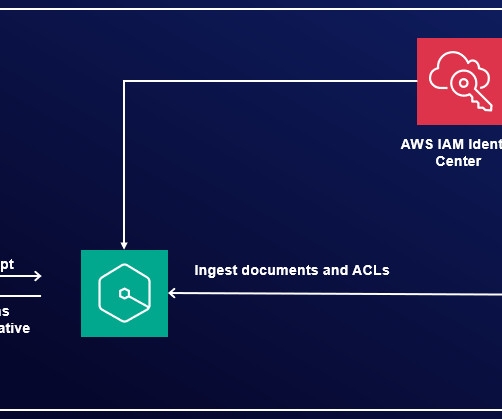
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive.
This conversational agent offers a new intuitive way to access the extensive quantity of seed product information to enable seed recommendations, providing farmers and sales representatives with an additional tool to quickly retrieve relevant seed information, complementing their expertise and supporting collaborative, informed decision-making.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. To address these inefficiencies, the implementation of advanced information extraction systems is crucial.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. For more information, refer to Shut down and Update Studio Classic Apps.
The federal government agency Precise worked with needed to automate manual processes for document intake and image processing. The agency wanted to use AI [artificial intelligence] and ML to automate document digitization, and it also needed help understanding each document it digitizes, says Duan.
Machine Learning & AI Applications Discover the latest advancements in AI-driven automation, naturallanguageprocessing (NLP), and computer vision. Machine Learning & Deep Learning Advances Gain insights into the latest ML models, neural networks, and generative AI applications.
Virtual Agent: Thats great, please say your 5 character booking reference, you will find it at the top of the information pack we sent. Virtual Agent: Thats great, please say your 5 character booking reference, you will find it at the top of the information pack we sent. Customer: Id like to check my booking. Please say yes or no.
By harnessing the power of machine learning (ML) and naturallanguageprocessing (NLP), businesses can streamline their data analysis processes and make more informed decisions. Augmented analytics is revolutionizing how organizations interact with their data. What is augmented analytics?
Your task is to provide a concise 1-2 sentence summary of the given text that captures the main points or key information. The summary should be concise yet informative, capturing the essence of the text in just 1-2 sentences. context} Please read the provided text carefully and thoroughly to understand its content.
Indeed, attackers are increasingly leveraging AI to efficiently gather and processinformation about their targets, prepare phishing campaigns, and develop new versions of malware, enhancing the power and effectiveness of their malicious operations. Since DL falls under ML, this discussion will primarily focus on machine learning.
Machine learning (ML) has emerged as a powerful tool to help nonprofits expedite manual processes, quickly unlock insights from data, and accelerate mission outcomesfrom personalizing marketing materials for donors to predicting member churn and donation patterns. It supports multiple predictive problem types.
By offering real-time translations into multiple languages, viewers from around the world can engage with live content as if it were delivered in their first language. In addition, the extension’s capabilities extend beyond mere transcription and translation. Chiara Relandini is an Associate Solutions Architect at AWS.
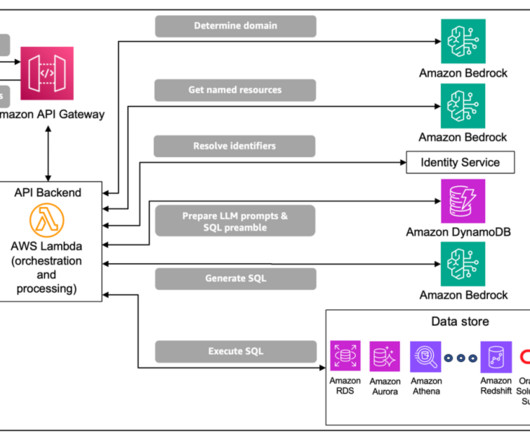
Large language models (LLMs) have transformed naturallanguageprocessing (NLP), yet converting conversational queries into structured data analysis remains complex. Amazon Bedrock Knowledge Bases enables direct naturallanguage interactions with structured data sources.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
The integration of modern naturallanguageprocessing (NLP) and LLM technologies enhances metadata accuracy, enabling more precise search functionality and streamlined document management. The process takes the extractive summary as input, which helps reduce computation time and costs by focusing on the most relevant content.
Although rapid generative AI advancements are revolutionizing organizational naturallanguageprocessing tasks, developers and data scientists face significant challenges customizing these large models. There are three personas: admin, data engineer, and user, which can be a data scientist or an ML engineer.
This wealth of content provides an opportunity to streamline access to information in a compliant and responsible way. Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles.
This mapping is similar in nature to intent classification, and enables the construction of an LLM prompt that is scoped for each input query (described next). By focusing on the data domain of the input query, redundant information, such as schemas for other data domains in the enterprise data store, can be excluded.
Sensitive information filters – You can detect sensitive content such as PII or custom regular expressions (regex) entities in user inputs and FM responses. Based on the use case, you can reject inputs that contain sensitive information or redact them in FM responses. test_type is either INPUT or OUTPUT.
Extracting information from unstructured documents at scale is a recurring business task. A classic approach to extracting information from text is named entity recognition (NER). Amazon Bedrock Data Automation serves as the primary engine for information extraction.
However, with the introduction of the Transformer architecture—initially successful in NaturalLanguageProcessing (NLP)—the landscape has shifted. From this point on, each patch is treated as a “token,” akin to words in NaturalLanguageProcessing (NLP) tasks.
Business challenge Today, many developers use AI and machine learning (ML) models to tackle a variety of business cases, from smart identification and naturallanguageprocessing (NLP) to AI assistants. Kanwaljit Khurmi is a Principal Generative AI/ML Solutions Architect at Amazon Web Services.
These agents represent a significant advancement over traditional systems by employing machine learning and naturallanguageprocessing to understand and respond to user inquiries. Machine learning (ML): Allows continuous improvement through data analysis.
These FMs work well for many use cases but lack domain-specific information that limits their performance at certain tasks. The dataset is clean and organized with about 5,000 data points, and the responses are more conversational than information seeking. This architecture allows these models to use only 13B (about 18.5%) of its 46.7B
Overview of multimodal embeddings and multimodal RAG architectures Multimodal embeddings are mathematical representations that integrate information not only from text but from multiple data modalities—such as product images, graphs, and charts—into a unified vector space.
The Rise of Augmented Analytics Augmented analytics is revolutionizing how data insights are generated by integrating artificial intelligence (AI) and machine learning (ML) into analytics workflows. Over 77% of AI-related job postings now require machine learning expertise, reflecting its critical role in data science jobs.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications. Sonnet across various tasks.
Why generative AI is best suited for assistants that support customer journeys Traditional AI assistants that use rules-based navigation or naturallanguageprocessing (NLP) based guidance fall short when handling the nuances of complex human conversations. Always ask for relevant information and avoid making assumptions.
Essential Skills for Solo AI Business TL;DR Key Takeaways : A strong understanding of AI fundamentals, including algorithms, neural networks, and naturallanguageprocessing, is essential for creating effective AI solutions and making informed decisions.
To excel in ML, you must understand its key methodologies: Supervised Learning: Involves training models on labeled datasets for tasks like classification (e.g., These techniques allow you to select the most effective approach for addressing specific challenges, making ML expertise indispensable in AI development.
Enterprises face significant challenges accessing and utilizing the vast amounts of information scattered across organization’s various systems. This consolidated index powers the naturallanguageprocessing and response generation capabilities of Amazon Q. You need the following information before running the script.
Selective logging – Use the capture_input and capture_output parameters to selectively log function inputs or outputs or exclude sensitive information or large data structures that might not be relevant for observability. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing with their ability to understand and generate humanlike text. For more information, refer Configure the AWS CLI. This blog post is co-written with Moran beladev, Manos Stergiadis, and Ilya Gusev from Booking.com.
Imagine an AI model that doesn’t just rely on static datasets but actively retrieves the latest medical research, legal precedents, or financial trends to inform its decisions. RAFT dynamically retrieves up-to-date information during training, bridging the gap between static datasets and evolving real-world knowledge.
Automated Reasoning checks help prevent factual errors from hallucinations using sound mathematical, logic-based algorithmic verification and reasoning processes to verify the information generated by a model, so outputs align with provided facts and arent based on hallucinated or inconsistent data.
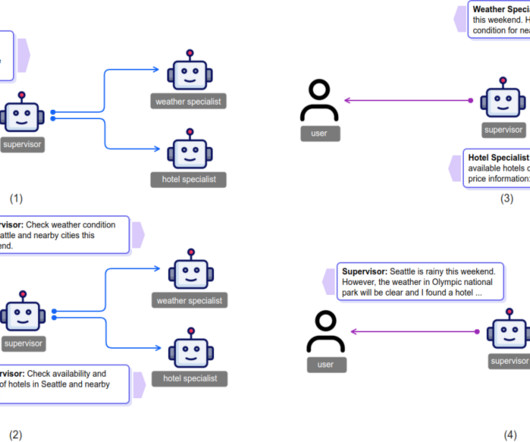
This single-agent approach can easily lead to confusion for LLMs because long-context reasoning becomes challenging when different types of information are mixed. Inter-agent communication Communication is the key component of multi-agent collaboration, allowing agents to exchange information and coordinate their actions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content