This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
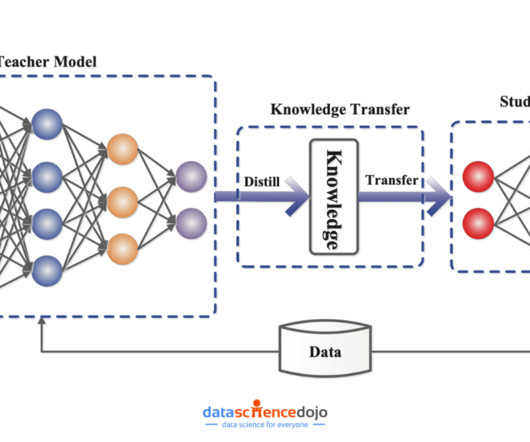
Knowledge Distillation is a machine learning technique where a teacher model (a large, complex model) transfers its knowledge to a student model (a smaller, efficient model). Now, it is time to train the teacher model on the dataset using standard supervisedlearning.
implies retaining sufficient components to capture 95% of the original datas variance, which may be appropriate for reducing the datas dimensionality while preserving most of its information. Theres another reason we are doing this, let me clarify it a bit later. For example, setting n_components to 0.95 Is this a good result?
Challenges in supervisedlearningSupervisedlearning often grapples with data limitations, particularly the scarcity of labeled examples necessary for training algorithms effectively. Cycle of continuous improvement The HITL process is iterative, involving constant cycles of data tagging and model refinement.
Typical SSL Architectures Introduction: The Rise of Self-SupervisedLearning In recent years, Self-SupervisedLearning (SSL) has emerged as a pivotal paradigm in machine learning, enabling models to learn from unlabeled data by generating their own supervisory signals. Core Techniques in SSL 1.
By submitting your information you agree to the Terms & Conditions and Privacy Policy and are aged 16 or over. The teams experiment could lead to more efficient algorithms in the fields of naturallanguageprocessing and other supervisedlearning models.
Structured data is a fundamental component in the world of data management and analytics, playing a crucial role in how we store, retrieve, and processinformation. Structured data refers to information that is organized into a well-defined format, allowing for straightforward processing and analysis.
Each layer captures essential features while discarding irrelevant information. It contains the most crucial information from the input data in a significantly reduced form. Can I Use Autoencoders for SupervisedLearning Tasks? Yes, autoencoders can enhance supervisedlearning tasks.
Machine learning forms a core subset of artificial intelligence and has a heavy influence in modern technology ranging from recommendation engines to self-driving cars. SupervisedLearning Algorithms One of the most common applications of machine learning occurs in supervisedlearning.
To excel in ML, you must understand its key methodologies: SupervisedLearning: Involves training models on labeled datasets for tasks like classification (e.g., Recurrent Neural Networks (RNNs): Designed for sequential data, such as time series or text, RNNs are commonly used in naturallanguageprocessing and speech recognition.
Essential Skills for Solo AI Business TL;DR Key Takeaways : A strong understanding of AI fundamentals, including algorithms, neural networks, and naturallanguageprocessing, is essential for creating effective AI solutions and making informed decisions.
This process typically involves training from scratch on diverse datasets, often consisting of hundreds of billions of tokens drawn from books, articles, code repositories, webpages, and other public sources. The key innovation of DPO lies in its formulation of preference learning as a classification problem.
Large language models (LLMs) can be used to perform naturallanguageprocessing (NLP) tasks ranging from simple dialogues and information retrieval tasks, to more complex reasoning tasks such as summarization and decision-making. 2022) Training language models to follow instructions with human feedback.
This deep learning model is designed to extract hierarchical representations from unlabeled data, setting a strong foundation for tasks across various domains, including image recognition and naturallanguageprocessing. Here, labeled data comes into play as it is used for supervisedlearning.
Copy the YouTube video URL from your browser Head over to Y2Mate and paste the URL in the search box Wait for Y2Mate to fetch the video information (like waiting for your model to initialize!)
Azure ML SDK : For those who prefer a code-first approach, the Azure Machine Learning Python SDK allows data scientists to work in familiar environments like Jupyter notebooks while leveraging Azure’s capabilities. Check out the Python SDK reference for detailed information.
By systematically updating the weights of connections between neurons, this algorithm forms the basis for training models that can tackle a variety of tasks, from image recognition to naturallanguageprocessing. Structure of neural networks Neural networks consist of several layers that work together to processinformation.
It allows machines to analyze vast amounts of information, which can lead to incredible innovations across various industries. These sophisticated algorithms facilitate a deeper understanding of data, enabling applications from image recognition to naturallanguageprocessing. What is deep learning?
Historical context of LLM development The development of AI language models began in the 1960s with early programs like Eliza, which simulated conversation by using pre-defined scripts. This innovation improved the efficiency of processinginformation, allowing models to handle longer dependencies in text data.
Masked language models (MLMs) are at the forefront of advancements in naturallanguageprocessing (NLP). These innovative models have revolutionized how machines comprehend and generate human language. What are masked language models (MLMs)?
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. Lets look at how generative AI can help solve this problem. Lets look at how generative AI can help solve this problem.
There are two types of machine learning based on the data on which the experts are training the model: SupervisedLearning: It is used when we have training data with the labels for the correct answer. Without human supervision, DL focuses on analyzing and acquiring dominant characteristics from intricate raw data forms.
AI data labeling is a fundamental process that underpins the success of machine learning (ML) applications. By accurately tagging and categorizing data, it transforms raw information into valuable insights, driving advancements across various sectors. What is AI data labeling?
They are essential for securing communications and safeguarding sensitive information against unauthorized access. Machine learning as an algorithm example Machine learning encompasses a variety of algorithms that learn from data and improve over time.
Zero-shot, one-shot, and few-shot learning are redefining how machines adapt and learn, promising a future where adaptability and generalization reach unprecedented levels. Source: Photo by Hal Gatewood on Unsplash In this exploration, we navigate from the basics of supervisedlearning to the forefront of adaptive models.
A visual representation of discriminative AI – Source: Analytics Vidhya Discriminative modeling, often linked with supervisedlearning, works on categorizing existing data. Generative AI often operates in unsupervised or semi-supervisedlearning settings, generating new data points based on patterns learned from existing data.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. They function by remembering past inputs to learn more contextual information.
These professionals venture into new frontiers like machine learning, naturallanguageprocessing, and computer vision, continually pushing the limits of AI’s potential. Supervisedlearning: This involves training a model on a labeled dataset, where each data point has a corresponding output or target variable.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. They function by remembering past inputs to learn more contextual information.
In their quest for effectiveness and well-informed decision-making, businesses continually search for new ways to collect information. QR codes can contain a huge amount of information, such as text, URLs, contact details, and more. In the realm of AI and ML, QR codes find diverse applications across various domains.
From virtual assistants like Siri and Alexa to personalized recommendations on streaming platforms, chatbots, and language translation services, language models surely are the engines that power it all.
Zero-shot, one-shot, and few-shot learning are redefining how machines adapt and learn, promising a future where adaptability and generalization reach unprecedented levels. Source: Photo by Hal Gatewood on Unsplash In this exploration, we navigate from the basics of supervisedlearning to the forefront of adaptive models.
Pixabay: by Activedia Image captioning combines naturallanguageprocessing and computer vision to generate image textual descriptions automatically. Image captioning integrates computer vision, which interprets visual information, and NLP, which produces human language.
These include image recognition, naturallanguageprocessing, autonomous vehicles, financial services, healthcare, recommender systems, gaming and entertainment, and speech recognition. Inspired by human brain structure, they are designed to perform as powerful tools for pattern recognition, classification, and prediction tasks.
The classification model learns from the training data, identifying the distinguishing characteristics between each class, enabling it to make informed predictions. Classification in machine learning can be a versatile tool with numerous applications across various industries.
Understanding the basics of artificial intelligence Artificial intelligence is an interdisciplinary field of study that involves creating intelligent machines that can perform tasks that typically require human-like cognitive abilities such as learning, reasoning, and problem-solving.
2022 was a big year for AI, and we’ve seen significant advancements in various areas – including naturallanguageprocessing (NLP), machine learning (ML), and deep learning. Unsupervised and self-supervisedlearning are making ML more accessible by lowering the training data requirements.
It’s important to take extra precautions to protect your device and sensitive information. As technology is improving, the detection of spam emails becomes a challenging task due to its changing nature. Text classification is essential for applications like web searches, information retrieval, ranking, and document classification.
The core process is a general technique known as self-supervisedlearning , a learning paradigm that leverages the inherent structure of the data itself to generate labels for training. Fine-tuning may involve further training the pre-trained model on a smaller, task-specific labeled dataset, using supervisedlearning.
In the first part of the series, we talked about how Transformer ended the sequence-to-sequence modeling era of NaturalLanguageProcessing and understanding. Semi-Supervised Sequence Learning As we all know, supervisedlearning has a drawback, as it requires a huge labeled dataset to train.
In recent years, naturallanguageprocessing and conversational AI have gained significant attention as technologies that are transforming the way we interact with machines and each other. Moreover, the model training process is capable of adapting to new languages and data effectively.
Summarization is the technique of condensing sizable information into a compact and meaningful form, and stands as a cornerstone of efficient communication in our information-rich age. In a world full of data, summarizing long texts into brief summaries saves time and helps make informed decisions.
Types of Machine Learning There are three main categories of Machine Learning, Supervisedlearning, Unsupervised learning, and Reinforcement learning. Supervisedlearning: This involves learning from labeled data, where each data point has a known outcome. Models […]
On the other hand, artificial intelligence is the simulation of human intelligence in machines that are programmed to think and learn like humans. By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informed decisions and take autonomous actions.
The answer lies in the various types of Machine Learning, each with its unique approach and application. In this blog, we will explore the four primary types of Machine Learning: SupervisedLearning, UnSupervised Learning, semi-SupervisedLearning, and Reinforcement Learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content