This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image-based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervisedlearning from images.
Supervisedlearning is a powerful approach within the expansive field of machine learning that relies on labeled data to teach algorithms how to make predictions. What is supervisedlearning? Supervisedlearning refers to a subset of machine learning techniques where algorithms learn from labeled datasets.
Semi-supervisedlearning is reshaping the landscape of machine learning by bridging the gap between supervised and unsupervised methods. With vast amounts of unlabeled data available in various domains, semi-supervisedlearning proves to be an invaluable tool in tackling complex classification tasks.
Typical SSL Architectures Introduction: The Rise of Self-SupervisedLearning In recent years, Self-SupervisedLearning (SSL) has emerged as a pivotal paradigm in machine learning, enabling models to learn from unlabeled data by generating their own supervisory signals.
Introduction Many contemporary technologies, especially machine learning, rely heavily on labeled data. The availability and caliber of labeled data strongly influence the […] The post What is Labeled Data?
Self-supervisedlearning (SSL) is a powerful tool in machine learning, but understanding the learned representations and their underlying mechanisms remains a challenge. This clustering process not only enhances downstream classification but also compresses the data information.
The mechanisms behind the success of multi-view self-supervisedlearning (MVSSL) are not yet fully understood. Contrastive MVSSL methods have been studied though the lens of InfoNCE, a lower bound of the Mutual Information (MI). However, the relation between other MVSSL methods and MI remains unclear.
Zero-shot, one-shot, and few-shot learning are redefining how machines adapt and learn, promising a future where adaptability and generalization reach unprecedented levels. Source: Photo by Hal Gatewood on Unsplash In this exploration, we navigate from the basics of supervisedlearning to the forefront of adaptive models.
Self-supervisedlearning (SSL) has emerged as a powerful technique for training deep neural networks without extensive labeled data. However, unlike supervisedlearning, where labels help identify relevant information, the optimal SSL representation heavily depends on assumptions made about the input data and desired downstream task.
In machine learning, few ideas have managed to unify complexity the way the periodic table once did for chemistry. Now, researchers from MIT, Microsoft, and Google are attempting to do just that with I-Con, or Information Contrastive Learning. It all boils down to preserving certain relationships while simplifying others.
Stage 2: Introduction of neural networks The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
Challenges in supervisedlearningSupervisedlearning often grapples with data limitations, particularly the scarcity of labeled examples necessary for training algorithms effectively. By incorporating insights from human experts, HITL contributes to more accurate predictions and informed decision-making.
A keen awareness of where a model lies on the bias-variance spectrum can lead to more informed decisions during the modeling process. Types of errors in machine learning Beyond bias and variance, specific types of errors characterize model performance issues. What is underfitting?
The world of multi-view self-supervisedlearning (SSL) can be loosely grouped into four families of methods: contrastive learning, clustering, distillation/momentum, and redundancy reduction. This work not only brings new theoretical insights but also introduces practical tools to optimize self-supervised models.
A visual representation of discriminative AI – Source: Analytics Vidhya Discriminative modeling, often linked with supervisedlearning, works on categorizing existing data. Generative AI often operates in unsupervised or semi-supervisedlearning settings, generating new data points based on patterns learned from existing data.
As machine learning continues to reshape the financial services industry, most headlines are dominated by breakthroughs in supervisedlearning. These include fraud detection models trained on labeled transactions or credit scoring systems built from years of historical repayment data. But behind
Linear regression stands out as a foundational technique in statistics and machine learning, providing insights into the relationships between variables. This method enables analysts and practitioners to create predictive models that can inform decision-making across many fields. What is linear regression?
Stage 2: Introduction of neural networks The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
This paper was accepted at the Self-SupervisedLearning - Theory and Practice (SSLTP) Workshop at NeurIPS 2024. Image-based Joint-Embedding Predictive Architecture (IJEPA) offers an attractive alternative to Masked Autoencoder (MAE) for representation learning using the Masked Image Modeling framework.
Moreover, these approaches integrate external processes to influence token generation by modifying the contextual information. A Paradigm Shift in AI Reasoning AoT marks a notable shift away from traditional supervisedlearning by integrating the search process itself.
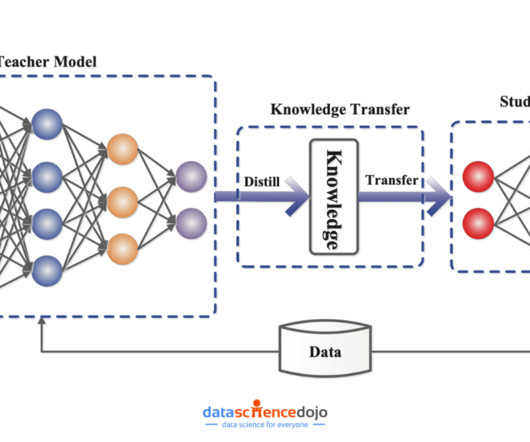
Knowledge Distillation is a machine learning technique where a teacher model (a large, complex model) transfers its knowledge to a student model (a smaller, efficient model). Now, it is time to train the teacher model on the dataset using standard supervisedlearning.
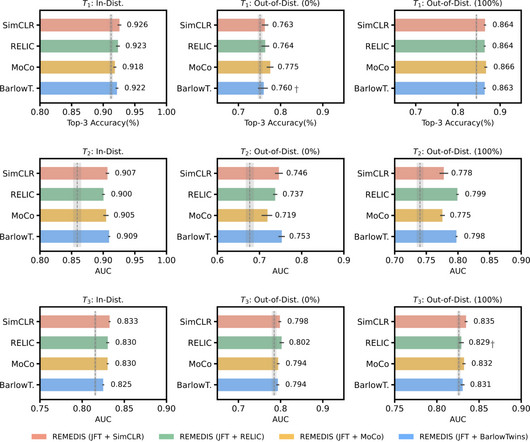
Alternatively, self-supervisedlearning (SSL) methods (e.g., SimCLR and MoCo v2 ), which leverage a large amount of unlabeled data to learn representations that capture periodic or quasi-periodic temporal dynamics, have demonstrated success in solving classification tasks. video or satellite imagery).
At the core of machine learning, two primary learning techniques drive these innovations. These are known as supervisedlearning and unsupervised learning. Supervisedlearning and unsupervised learning differ in how they process data and extract insights.
From Data Cubes to Embeddings During the development phase in March, participants will pretrain their encoders using self-supervisedlearning methods that underpin neural compression and EO foundation models. Link to the challenge and more information : Challenge PortalEval.AI
It takes in data, makes sense of it, and uses that information to plan its next move. Its about creating AI that does not just do, but thinks, learns, and acts on its own. It allows developers to easily create and manage systems where multiple AI agents can communicate, share information, and delegate tasks to each other.
What is clustering in machine learning? Clustering is a subset of unsupervised learning where the goal is to categorize a set of objects into groups based on their similarities. Unlike supervisedlearning, which relies on labeled training data, clustering algorithms identify inherent structures within the data.
Zero-shot, one-shot, and few-shot learning are redefining how machines adapt and learn, promising a future where adaptability and generalization reach unprecedented levels. Source: Photo by Hal Gatewood on Unsplash In this exploration, we navigate from the basics of supervisedlearning to the forefront of adaptive models.
These models are trained using data at scale, often by self-supervisedlearning. This process results in generalist models that can rapidly be adapted to new tasks and environments with less need for supervised data. The specific approach used for pre-training and learning representations is SimCLR.
Types of Machine Learning Algorithms Machine Learning has become an integral part of modern technology, enabling systems to learn from data and improve over time without explicit programming. The goal is to learn a mapping from inputs to outputs, allowing the model to make predictions on unseen data.
In their quest for effectiveness and well-informed decision-making, businesses continually search for new ways to collect information. QR codes can contain a huge amount of information, such as text, URLs, contact details, and more. In the realm of AI and ML, QR codes find diverse applications across various domains.
By allowing algorithms to learn autonomously, it opens the door to various innovative applications across different fields. From organizing vast datasets to finding similarities among complex information, unsupervised learning plays a pivotal role in enhancing decision-making processes and operational efficiencies.
Let’s dig into some of the most asked interview questions from AI Scientists with best possible answers Core AI Concepts Explain the difference between supervised, unsupervised, and reinforcement learning. The model learns to map input features to output labels.
Multiview Self-SupervisedLearning (MSSL) is based on learning invariances with respect to a set of input transformations. However, invariance partially or totally removes transformation-related information from the representations, which might harm performance for specific downstream tasks that require such information.
With the use of machine learning, people find out about the 2 main types of machine learning: Supervised and Unsupervised learning. SupervisedLearning First, what exactly is supervisedlearning? It is the most common type of machine learning that you will use. Let’s get right into it.
The classification model learns from the training data, identifying the distinguishing characteristics between each class, enabling it to make informed predictions. Classification in machine learning can be a versatile tool with numerous applications across various industries.
Characteristics of KNN Supervisedlearning: KNN is a supervisedlearning algorithm that requires labeled training data to work effectively. Understanding these can help professionals make informed decisions on when to use this algorithm.
Instance-based learning (IBL) is a fascinating approach within the realm of machine learning that emphasizes the importance of individual data points rather than abstracting information into generalized models. This method allows systems to utilize specific historical examples to inform predictions about new instances.
Recent Self-SupervisedLearning (SSL) methods are able to learn feature representations that are invariant to different data augmentations, which can then be transferred to downstream tasks of interest. In this paper, we aim to learn self-supervised features that generalize well across a variety of downstream tasks (e.g.,
Imagine a world where computers can’t interpret the visual information around them without a little human assistance. These labels provide crucial context for machine learning models, enabling them to make informed decisions and predictions. That’s where data annotation comes into play.
What is ground truth in machine learning? Ground truth in machine learning refers to the precise, labeled data that provides a benchmark for various algorithms. This accurate information is essential for ensuring the performance of predictive models, which learn from existing data to make future predictions.
Support Vector Machines (SVM) are a type of supervisedlearning algorithm designed for classification and regression tasks. In the context of SVMs, it serves as the decision boundary that separates different classes of data, allowing for distinct classifications in supervisedlearning.
Input and learning process To begin learning, DeepMind systems take in raw data, often in the form of pixel information. Deep learning techniques The division employs deep learning methodologies, particularly convolutional neural networks (CNNs), which excel at recognizing patterns.
It has significantly impacted industries like finance, healthcare, and transportation by analysing data, making predictions, and automating decisions Predictive Modelling Machine Learning algorithms excel at predictive modelling, which involves using historical data to create models that forecast future events. predicting house prices).
In this article, I’ll guide you through your first training session on a Machine Learning Algorithm: we’ll be training… pub.towardsai.net Classification and Regression fall under SupervisedLearning, a category in Machine Learning where we have prior knowledge of the target variable.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content