This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Movie Recommendation and Rating Prediction using K-NearestNeighbors appeared first on Analytics Vidhya. Introduction Recommendation systems are becoming increasingly important in today’s hectic world. People are always in the lookout for products/services that are best suited for.
The OpenCV library comes with a module that implements the k-NearestNeighbors algorithm for machine learning applications. In this tutorial, you are going to learn how to apply OpenCV’s k-NearestNeighbors algorithm for the task of classifying handwritten digits.
The k-NearestNeighbors Classifier is a machine learning algorithm that assigns a new data point to the most common class among its k closest neighbors. In this tutorial, you will learn the basic steps of building and applying this classifier in Python.
Introduction This article concerns one of the supervised ML classification algorithm-KNN(K. The post A Quick Introduction to K – NearestNeighbor (KNN) Classification Using Python appeared first on Analytics Vidhya. ArticleVideos This article was published as a part of the Data Science Blogathon.
Learn about the k-nearest neighbours algorithm, one of the most prominent workhorse machine learning algorithms there is, and how to implement it using Scikit-learn in Python.
Introduction Knearestneighbors are one of the most popular and best-performing algorithms in supervised machine learning. This article was published as a part of the Data Science Blogathon. Therefore, the data […].
Overview: KNearestNeighbor (KNN) is intuitive to understand and. ArticleVideo Book This article was published as a part of the Data Science Blogathon. The post Simple understanding and implementation of KNN algorithm! appeared first on Analytics Vidhya.
Introduction KNN stands for K-NearestNeighbors, the supervised machine learning algorithm that can operate with both classification and regression tasks. This article was published as a part of the Data Science Blogathon.
Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. Enter KNearestNeighbor (k-NN), a technique that personifies the very essence of propinquity and Neighborly dynamics.
Introduction Knearestneighbor or KNN is one of the most famous algorithms in classical AI. KNN is a great algorithm to find the nearestneighbors and thus can be used as a classifier or similarity finding algorithm. The post Product Quantization: NearestNeighbor Search appeared first on Analytics Vidhya.
In this article, we will try to classify Food Reviews using multiple Embedded techniques with the help of one of the simplest classifying machine learning models called the K-NearestNeighbor. Here is the agenda that will follow in this article. Objective Loading Data Data […].
Learn the basics of machine learning, including classification, SVM, decision tree learning, neural networks, convolutional, neural networks, boosting, and Knearestneighbors.
Photo by Avi Waxman on Unsplash What is KNN Definition K-NearestNeighbors (KNN) is a supervised algorithm. The basic idea behind KNN is to find Knearest data points in the training space to the new data point and then classify the new data point based on the majority class among the knearest data points.
Traditional exact nearestneighbor search methods (e.g., brute-force search and k -nearestneighbor (kNN)) work by comparing each query against the whole dataset and provide us the best-case complexity of. On Line 28 , we sort the distances and select the top knearestneighbors.
Using GZIP compression and the k-NearestNeighbors algorithm, we explore an innovative approach to classifying the MNIST dataset with about 78% accuracy
Zheng’s “Guide to Data Structures and Algorithms” Parts 1 and Part 2 1) Big O Notation 2) Search 3) Sort 3)–i)–Quicksort 3)–ii–Mergesort 4) Stack 5) Queue 6) Array 7) Hash Table 8) Graph 9) Tree (e.g.,
However, it can be very effective when you are working with multivariate analysis and similar methods, such as Principal Component Analysis (PCA), Support Vector Machine (SVM), K-means, Gradient Descent, Artificial Neural Networks (ANN), and K-nearestneighbors (KNN).
By New Africa In this article, I will show how to implement a K-NearestNeighbor classification with Tensorflow.js. KNN KNN (K-NearestNeighbors) classification is a supervised machine learning algorithm used for classification tasks. TensorFlow.js TensorFlow.js
The K-NearestNeighbors Algorithm Math Foundations: Hyperplanes, Voronoi Diagrams and Spacial Metrics. K-NearestNeighbors Suppose that a new aircraft is being made. Intersecting bubbles create a space segmented by Voronoi regions. Photo by Who’s Denilo ? Photo from here 2.1
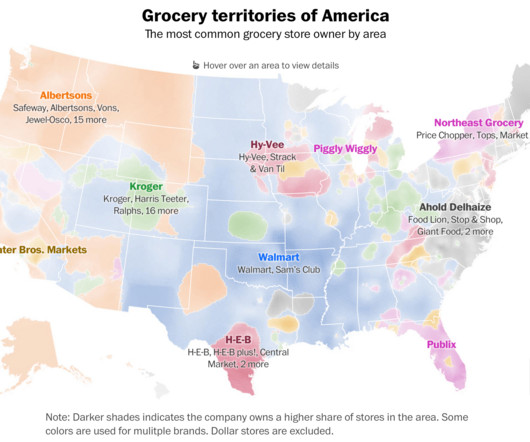
The map visualizes the influence of the nearest grocery store locations using a k-nearestneighbor analysis that falls off as the distance to a stores increases. The Post pulled locations in the United States identified as supermarkets, as well as Walmart, Sam’s Club, Target and Costco.
Some common models used are as follows: Logistic Regression – it classifies by predicting the probability of a data point belonging to a class instead of a continuous value Decision Trees – uses a tree structure to make predictions by following a series of branching decisions Support Vector Machines (SVMs) – create a clear decision (..)
The three weak learner models used for this implementation were k-nearestneighbors, decision trees, and naive Bayes. For the meta-model, k-nearestneighbors were used again. A meta-model is trained on this second-level training data to produce the final predictions.
We shall look at various types of machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. R Studios and GIS In a previous article, I wrote about GIS and R.,
You can use the following tuning controls: Algorithms and parameters This includes the following: Hierarchical Navigable Small World (HNSW) algorithm and parameters like ef_search , ef_construct , and m Inverted File Index (IVF) algorithm and parameters like nlist and nprobes Exact k-nearestneighbors (k-NN), also known as brute-force k-NN (BFKNN) (..)
We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. K-NearestNeighbors (KNN) is a supervised ML algorithm for classification and regression. I’m trying out a new thing: I draw illustrations of graphs, etc., Quick Primer: What is Supervised?
For geographical analysis, Random Forest, Support Vector Machines (SVM), and k-nearestNeighbors (k-NN) are three excellent methods. Scalability: Verify that the algorithm can manage increasing data quantities and, if required, be applied to distributed systems. So, Who Do I Have?
Nearestneighbor search algorithms : Efficiently retrieving the closest patient vec t o r s to a given query. Techniques like k-NearestNeighbors ( kNN ) and Annoy trees excel in this area, enabling rapid identification of sim i l a r patients.
Decision trees and K-nearestneighbors (KNN) Both decision trees and KNN play vital roles in classification and prediction. Decision trees provide clear, visual representations of decision-making processes, while KNN classifies data based on the proximity of neighboring points.
Examples include: Classifying species of plants Categorizing images into animals, vehicles, or landscapes Algorithms like Random Forests, Naive Bayes, and K-NearestNeighbors (KNN) are commonly used for multi-class classification. Each instance is assigned to one of several predefined categories.
37.79);// Sample the training data using the ROIvar training = image.sample({ region: roi, scale: 30, numPixels: 5000});// Set the class property based on a land cover mapvar classProperty = 'landcover';// Train a k-NearestNeighbors classifiervar classifier = ee.Classifier.kNearestNeighbors(10).train({
K-NearestNeighbors (KNN): This method classifies a data point based on the majority class of its Knearestneighbors in the training data. Support Vector Machines (SVM): This algorithm finds a hyperplane that best separates data points of different classes in high-dimensional space.
Leveraging a comprehensive dataset of diverse fault scenarios, various machine learning algorithms—including Random Forest (RF), K-NearestNeighbors (KNN), and Long Short-Term Memory (LSTM) networks—are evaluated. An ensemble methodology, RF-LSTM Tuned KNN, is proposed to enhance detection accuracy and robustness.
The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. What are KNearestNeighbors in Machine Learning? Definition of KNN Algorithm KNearestNeighbors (KNN) is a simple yet powerful machine learning algorithm for classification and regression tasks.
K-nearestneighbors are sufficient for detecting specific medialike in copyright protectionbut less reliable when analyzing a broad range of factors. The best type of model depends on what you want your A/V analysis to accomplish. Keep your input types, goals, computing hardware availability and budget in mind when choosing.
It supports advanced features such as result highlighting, flexible pagination, and k-nearestneighbor (k-NN) search for vector and semantic search use cases.
self.index.add(self.embeddings_vec) def topk(self, vector, k = 4): """ A function that takes in a vector and an optional parameter k and returns the indices of the knearestneighbors in the index. k (optional): An integer representing the number of nearestneighbors to retrieve.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories. Click to learn more about author Kartik Patel. In this article, we will discuss the KNN Classification method of analysis. What Is the KNN Classification Algorithm?
From not sweating missing values, to determining feature importance for any estimator, to support for stacking, and a new plotting API, here are 5 new features of the latest release of Scikit-learn which deserve your attention.
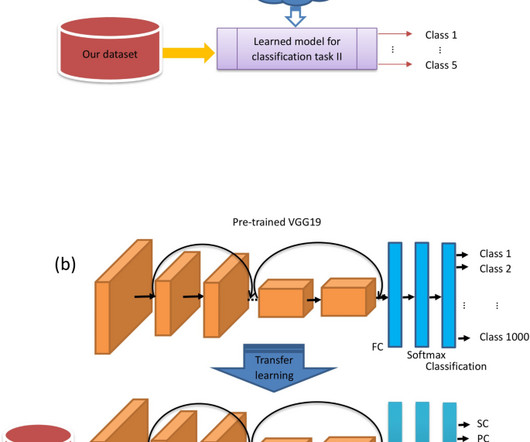
The proven classifier models, k - nearestneighbor (KNN) and support vecter machine (SVM) models, are integrated to classify the extracted deep CNN features. 3 distinct experiments with the same deep CNN features but different classifier models (softmax, KNN, SVM) are performed.
MongoDB Atlas Vector Search uses a technique called k-nearestneighbors (k-NN) to search for similar vectors. k-NN works by finding the k most similar vectors to a given vector. Vector data is a type of data that represents a point in a high-dimensional space.
In the world of computer vision and image processing, the ability to extract meaningful features from images is important. These features serve as vital inputs for various downstream tasks, such as object detection and classification. There are multiple ways to find these features. The naive way is to count the pixels.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content