This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By understanding machinelearning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Predict traffic jams by learning patterns in historical traffic data. Learn in detail about machinelearning algorithms 2.
Summary: Classifier in MachineLearning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. Introduction MachineLearning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions.
These features can be used to improve the performance of MachineLearning Algorithms. In the world of data science and machinelearning, feature transformation plays a crucial role in achieving accurate and reliable results.
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machinelearning, involving algorithms that create new content on their own. This approach involves techniques where the machinelearns from massive amounts of data.
Summary: MachineLearning algorithms enable systems to learn from data and improve over time. Introduction MachineLearning algorithms are transforming the way we interact with technology, making it possible for systems to learn from data and improve over time without explicit programming.
The competition for best algorithms can be just as intense in machinelearning and spatial analysis, but it is based more objectively on data, performance, and particular use cases. For geographical analysis, Random Forest, SupportVectorMachines (SVM), and k-nearestNeighbors (k-NN) are three excellent methods.
R has become ideal for GIS, especially for GIS machinelearning as it has topnotch libraries that can perform geospatial computation. R has simplified the most complex task of geospatial machinelearning and data science. Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. data = trainData) 5.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
In this blog we’ll go over how machinelearning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
It also includes practical implementation steps and discusses the future of classification in MachineLearning. Introduction MachineLearning has revolutionised the way we analyse and interpret data, enabling machines to learn from historical data and make predictions or decisions without explicit programming.
In the ever-evolving landscape of MachineLearning, scaling plays a pivotal role in refining the performance and robustness of models. Among the multitude of techniques available to enhance the efficacy of MachineLearning algorithms, feature scaling stands out as a fundamental process.
MachineLearning has revolutionized various industries, from healthcare to finance, with its ability to uncover valuable insights from data. Among the different learning paradigms in Machine Learnin g, “Eager Learning” and “Lazy Learning” are two prominent approaches.
A complete explanation of the most widely practical and efficient field, that nowadays has an impact on every industry Photo by Thomas T on Unsplash Machinelearning has become one of the most rapidly evolving and popular fields of technology in recent years. How is it actually looks in a real life process of ML investigation?
One such intriguing aspect is the potential to predict a user’s race based on their tweets, a task that merges the realms of Natural Language Processing (NLP), machinelearning, and sociolinguistics. With the preprocessed data in hand, we can now employ pyCaret, a powerful machinelearning library, to build our predictive models.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
In this article, we will discuss some of the factors to consider while selecting a classification & Regression machinelearning algorithm based on the characteristics of the data. For larger datasets, more complex algorithms such as Random Forest, SupportVectorMachines (SVM), or Neural Networks may be more suitable.
Every type of machinelearning and deep learning algorithm has a large number of hyperparameters. SupportVectorMachine Classification and Regression C: This hyperparameter decides the regularization strength. What is hyperparameter tuning? It can have values: [‘l1’, ‘l2’, ‘elasticnet’, ‘None’].
Introduction Anomaly detection is identified as one of the most common use cases in MachineLearning. The following blog will provide you a thorough evaluation on how Anomaly Detection MachineLearning works, emphasising on its types and techniques. Billion which is supposed to increase by 35.6% CAGR during 2022-2030.
Summary: Inductive bias in MachineLearning refers to the assumptions guiding models in generalising from limited data. Introduction Understanding “What is Inductive Bias in MachineLearning?” ” is crucial for developing effective MachineLearning models.
The concepts of bias and variance in MachineLearning are two crucial aspects in the realm of statistical modelling and machinelearning. Understanding these concepts is paramount for any data scientist, machinelearning engineer, or researcher striving to build robust and accurate models.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. Diego Martn Montoro is an AI Expert and MachineLearning Engineer at Applus+ Idiada Datalab.
Artificial Intelligence (AI) models are the building blocks of modern machinelearning algorithms that enable machines to learn and perform complex tasks. These models are designed to replicate the human brain’s cognitive functions, enabling them to perceive, reason, learn, and make decisions based on data.
Artificial Intelligence (AI) models are the building blocks of modern machinelearning algorithms that enable machines to learn and perform complex tasks. These models are designed to replicate the human brain’s cognitive functions, enabling them to perceive, reason, learn, and make decisions based on data.
The prediction is then done using a k-nearestneighbor method within the embedding space. Correctly predicting the tags of the questions is a very challenging problem as it involves the prediction of a large number of labels among several hundred thousand possible labels.
Text classification with a multi-arm bandit algorithm is a machinelearning approach that can be used to optimize the performance of a text classifier over time. bag of words or TF-IDF vectors) and splitting the data into training and testing sets. Text classification using Multi-Armed Bandit.
What makes it popular is that it is used in a wide variety of fields, including data science, machinelearning, and computational physics. Scikit-learn A machinelearning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many data scientists.
By understanding crucial concepts like MachineLearning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
Figure 1 Preprocessing Data preprocessing is an essential step in building a MachineLearning model. K-Nearest Neighbou r: The k-NearestNeighbor algorithm has a simple concept behind it. We make use of ensemble learning through a Voting Classifier to increase our model’s performance.
Algorithms for Anomaly Detection We can divide anomaly detection algorithms ( Figure 5 ) into the following: statistical methods machinelearning methods proximity-based methods ensemble methods Figure 5: Algorithms for detecting anomalies (source: Medium ). Supervised Learning These methods require labeled data to train the model.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machinelearning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science? Let us see some examples.
Targeted Resource Allocation Traditional machine-learning approaches often require extensive data labeling, which can be costly and time-consuming. Active Learning significantly reduces these costs through strategic selection of data points. Traditional Active Learning has the following characteristics.
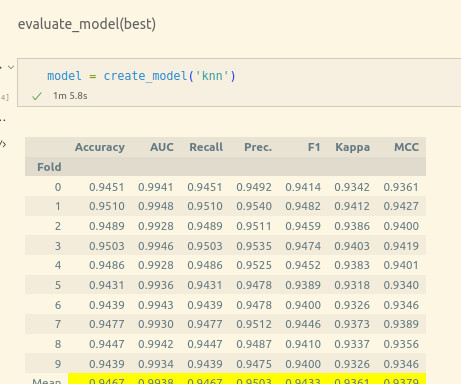
Check out the previous post to get a primer on the terms used) Outline Dealing with Class Imbalance Choosing a MachineLearning model Measures of Performance Data Preparation Stratified k-fold Cross-Validation Model Building Consolidating Results 1. among supervised models and k-nearestneighbors, DBSCAN, etc.,
Apart from many areas in our lives, hybrid machinelearning techniques can help us with effective heart disease prediction. So how can the technology of our time, machinelearning, be used to improve the quality and length of human life? According to the World Health Organization , heart disease takes an estimated 17.9
Machinelearning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. What are machinelearning algorithms? Regression: Focuses on predicting continuous values, such as forecasting sales or estimating property prices.
These samples can provide a good basis for machinelearning , which can determine (with some probability) the type of unknown files using a model built on the different distributions. In a procedure based on BFD (Byte Frequency Distribution), it is not necessary to read the whole file, which saves time.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content