This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A prominent example is Google’s Duplex , a technology that enables AI assistants to make phone calls on behalf of users for tasks like scheduling appointments and reservations.
Here are a few key components of the discussed process described below: Feature engineering : Transforming raw clinical data into meaningful numerical representations suitable for vector space. This may involve techniques like naturallanguageprocessing for medical records or dimensionality reduction for complex biomolecular data.
adults use only work when they can turn audio data into words, and then apply naturallanguageprocessing (NLP) to understand it. K-nearestneighbors are sufficient for detecting specific medialike in copyright protectionbut less reliable when analyzing a broad range of factors.
MongoDB Atlas Vector Search uses a technique called k-nearestneighbors (k-NN) to search for similar vectors. k-NN works by finding the k most similar vectors to a given vector. Vector data is a type of data that represents a point in a high-dimensional space.
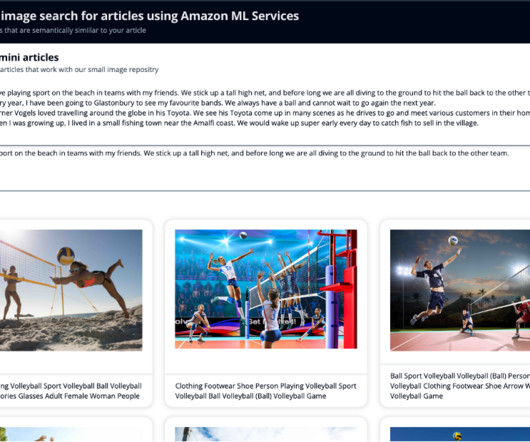
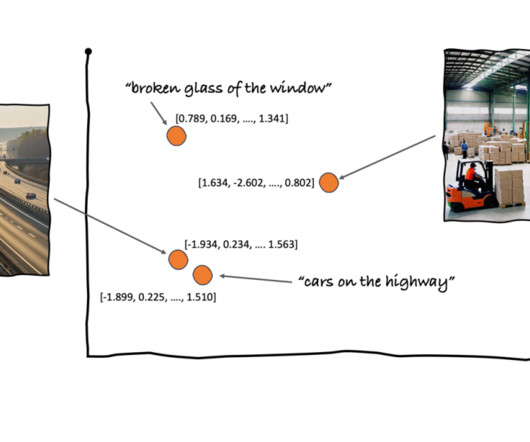
You also generate an embedding of this newly written article, so that you can search OpenSearch Service for the nearest images to the article in this vector space. Using the k-nearestneighbors (k-NN) algorithm, you define how many images to return in your results. For this example, we use cosine similarity.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
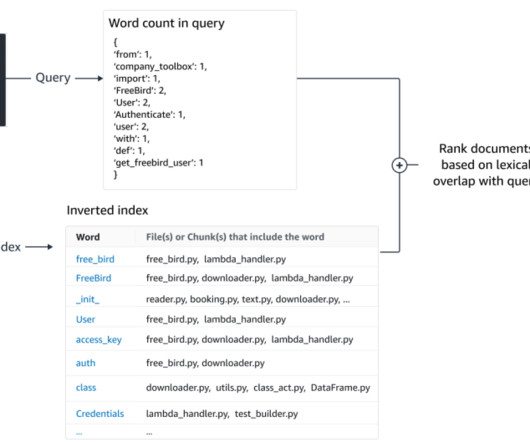
Formally, often k-nearestneighbors (KNN) or approximate nearestneighbor (ANN) search is often used to find other snippets with similar semantics. Her research interests lie in NaturalLanguageProcessing, AI4Code and generative AI. Semantic retrieval BM25 focuses on lexical matching.
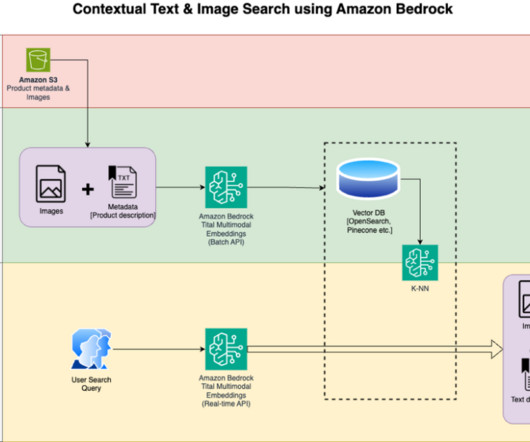
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality.
These vectors are typically generated by machine learning models and enable fast similarity searches that power AI-driven applications like recommendation engines, image recognition, and naturallanguageprocessing. How is it Different from Traditional Databases?
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others.
It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean. K-NN (knearestneighbors): K-NearestNeighbors (K-NN) is a simple yet powerful algorithm used for both classification and regression tasks in Machine Learning.
You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). The following diagram visualizes the semantic search with naturallanguageprocessing (NLP).
One such intriguing aspect is the potential to predict a user’s race based on their tweets, a task that merges the realms of NaturalLanguageProcessing (NLP), machine learning, and sociolinguistics. This allowed us to gain rapid insights into the dataset, paving the way for model selection and evaluation.
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. The summary describes an image related to the progression of naturallanguageprocessing and generative AI technologies, but it does not mention anything about particle physics or the concept of quarks.
For more information about the naturallanguage understanding-powered search functionalities of OpenSearch Service, refer to Building an NLU-powered search application with Amazon SageMaker and the Amazon OpenSearch Service KNN feature. Solution overview. Matthew Rhodes is a Data Scientist I working in the Amazon ML Solutions Lab.
Model invocation We use Anthropics Claude 3 Sonnet model for the naturallanguageprocessing task. This LLM model has a context window of 200,000 tokens, enabling it to manage different languages and retrieve highly accurate answers. temperature This parameter controls the randomness of the language models output.
While this bias is powerful in tasks like image recognition and naturallanguageprocessing , it can be computationally expensive and prone to overfitting when data is limited or not properly regularised. k-NearestNeighbors (k-NN) The k-NN algorithm assumes that similar data points are close to each other in feature space.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-NearestNeighbor (k-NN) search in Amazon OpenSearch Service ), among others.
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. He is broadly interested in Deep Learning and NaturalLanguageProcessing. Some plays are mixed into other coverage types, as shown in the following figure (right). He obtained his Ph.D.
Introduction In naturallanguageprocessing, text categorization tasks are common (NLP). K-Nearest Neighbou r: The k-NearestNeighbor algorithm has a simple concept behind it. Foundations of Statistical NaturalLanguageProcessing [M]. Uysal and Gunal, 2014). Dönicke, T.,
Transformer Models: Originally designed for naturallanguageprocessing, transformers have been adapted to vision transformers (ViT) and are now used for image analysis. They have proved to yield better results than CNNs in some applications. As we can see, applications of image embeddings can vary.
Naturallanguageprocessing ( NLP ) allows machines to understand, interpret, and generate human language, which powers applications like chatbots and voice assistants. K-NearestNeighbors), while others can handle large datasets efficiently (e.g., Random Forests).
Gender Bias in NaturalLanguageProcessing (NLP) NLP models can develop biases based on the data they are trained on. K-NearestNeighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance.
KK-Means Clustering: An unsupervised learning algorithm that partitions data into K distinct clusters based on feature similarity. K-NearestNeighbors (KNN): A simple, non-parametric classification algorithm that assigns a class to a data point based on the majority class of its Knearest neighbours.
How to perform Face Recognition using KNN In this blog, we will see how we can perform Face Recognition using KNN (K-NearestNeighbors Algorithm) and Haar cascades. NaturalLanguageProcessing Projects with source code in Python 69. Its accuracy is slightly less compared to these big boys like MTCNNs.
They are: Based on shallow, simple, and interpretable machine learning models like support vector machines (SVMs), decision trees, or k-nearestneighbors (kNN). Relies on explicit decision boundaries or feature representations for sample selection. Works well with small datasets and models with fewer parameters.
Jiang, Wenda Li, Szymon Tworkowski, Konrad Czechowski, Tomasz Odrzygóźdź, Piotr Miłoś, Yuhuai Wu , Mateja Jamnik TPU-KNN: KNearestNeighbor Search at Peak FLOP/s Felix Chern , Blake Hechtman , Andy Davis , Ruiqi Guo , David Majnemer , Sanjiv Kumar When Does Dough Become a Bagel?
Naturallanguageprocessing for classifying text based on word frequency vectors. Classification problems In classification tasks, feature vectors assist algorithms like neural networks and k-nearestneighbors in making informed predictions based on historical data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content