This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
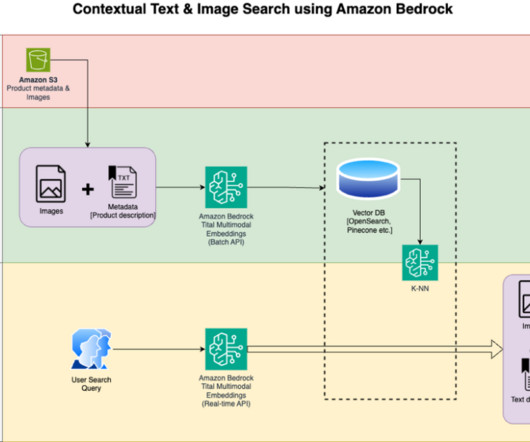
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. Open the titan_mm_embed_search_blog.ipynb notebook.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. This module provides a comprehensive set of tools and abstractions that streamline the process of incorporating and deploying these advanced AI models.
For more information about the naturallanguage understanding-powered search functionalities of OpenSearch Service, refer to Building an NLU-powered search application with Amazon SageMaker and the Amazon OpenSearch Service KNN feature. Initializes the OpenSearch Service client using the Boto3 Python library. Solution overview.
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. This is one of the best Machine learning projects in Python. Doctor-Patient Appointment System in Python using Flask Hey guys, in this blog we will see a Doctor-Patient Appointment System for Hospitals built in Python using Flask.
Alternatively, you can use a serverless Lambda function to extract frames of a stored video file with the Python OpenCV library. You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3).
One such intriguing aspect is the potential to predict a user’s race based on their tweets, a task that merges the realms of NaturalLanguageProcessing (NLP), machine learning, and sociolinguistics. This allowed us to gain rapid insights into the dataset, paving the way for model selection and evaluation.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-NearestNeighbor (k-NN) search in Amazon OpenSearch Service ), among others.
Joblib: A Python library used for lightweight pipelining in Python, handy for saving and loading large data structures. KK-Means Clustering: An unsupervised learning algorithm that partitions data into K distinct clusters based on feature similarity.
Naturallanguageprocessing ( NLP ) allows machines to understand, interpret, and generate human language, which powers applications like chatbots and voice assistants. K-NearestNeighbors), while others can handle large datasets efficiently (e.g., Random Forests).
They are: Based on shallow, simple, and interpretable machine learning models like support vector machines (SVMs), decision trees, or k-nearestneighbors (kNN). We will divide this section into two categories: Python library and web based tools. Libact : It is a Python package for active learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content